
2019年にSOTAを更新したALBERT(A Lite BERT)は、Transformerベースの自然言語処理モデルの進化を象徴する存在。この記事では、その起源から高度な機能までを探求し、最先端のNLP技術を理解します。
この記事の目次
- ALBERTの起源と特徴
- ALBERTとその周辺技術
- ALBERTの仕組みと内部構造
- BETOとの比較
- まとめ
ALBERTの起源と特徴
ALBERTは、元となるBERTから重要な改良を加えつつ生まれた。このモデルの開発者は,パラメータ共有とファインチューニングによる効率化を追求した。
具体的には,パラメータ数を削減し,これにより学習時間を短縮しつつ、依然として高い精度を維持することが可能となった。これは、大規模なモデルを利用する際の制約緩和につながっている。
ALBERTとその周辺技術

ALBERTは,Transformerアーキテクチャの進化をリードする一連のモデルと並行して開発された。これらの他の技術との関係性も理解することで、NLPにおける最新動向が見えてくる。
例えば,BERTやXLNetなどの前駆者から学んだ教訓に基づき,ALBERTは独自の強みを持つこととなった。このような背景を踏まえると,ALBERTは単なるパラメータの削減に留まらず、さらなる効率化を可能にする革新的なアプローチを持ち合わせている。
ALBERTの仕組みと内部構造
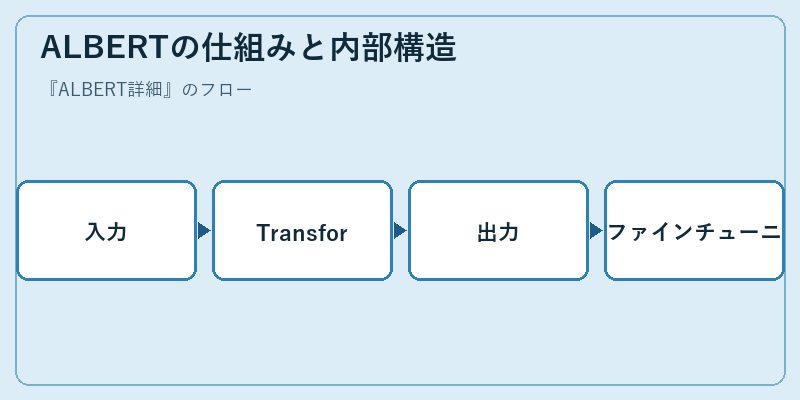
ALBERTの機能を深く理解するためには,その内部構造を詳しく見ることが重要だ。まず,入力を受けてから複数のTransformerレイヤーを通じて処理が行われる。
この後,出力結果はさらなるファインチューニングによって精度向上に寄与し、最終的なモデル性能の確立へと繋がっていく。これらのプロセスはALBERTの効率性とパフォーマンスを支えている。
BETOとの比較
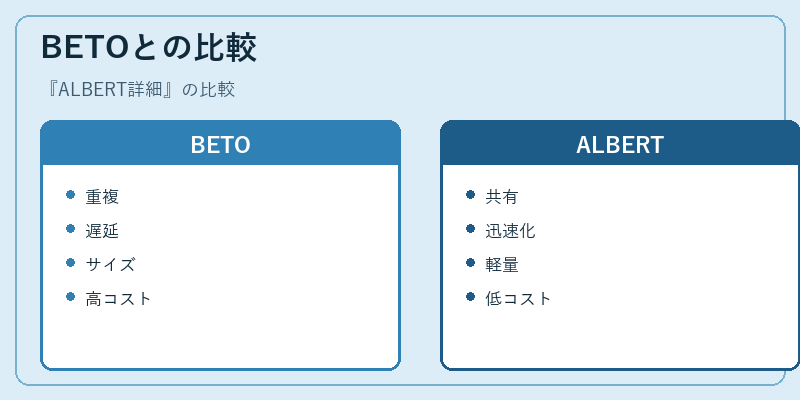
ALBERTと従来のBETOとの間には,重要な違いが存在する。特にパラメータの重複とサイズにおいて大きな進歩が見られる。
結果として,モデルの学習時間を大幅に短縮し,効率性を向上させることで,より多くの実用的なNLPタスクへの適用が可能となる。
まとめ
ALBERTは軽量化とパフォーマンスのバランスを成功裏に達成したモデルであり、大規模なデータセットでの応用範囲も広いことが確認できる。今後もその進化に注目したい。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント