
CrossViTは、画像と自然言語間の相互作用を強化する新たな双方向学習モデルです。開発者の目的や進展状況を通じて、機械が視覚情報と文脈的理解力を同時に育成することの重要性を探ります。
目次
この記事の目次
- CrossViTの基本構造
- CrossViTの発展背景
- CrossViTにおける情報伝達
- CrossViTと従来モデルの比較
- まとめ
CrossViTの基本構造
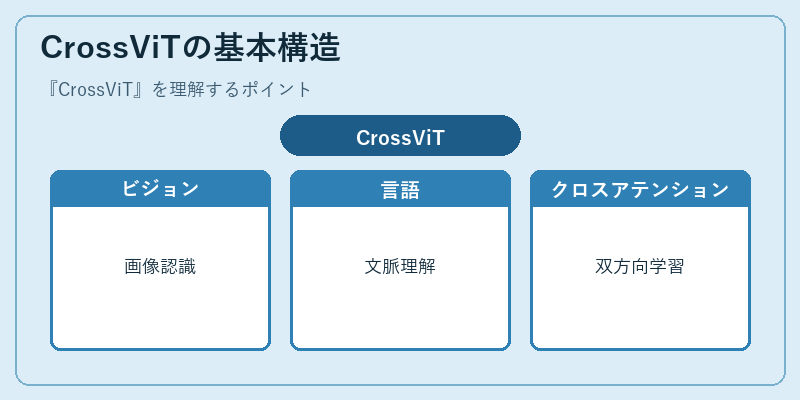
CrossViTは、視覚と文の間で情報を共有し合う構造を採用しています。この仕組みにより、モデルは複雑なタスクにも対応できます。
具体的には、画像から得られた特徴量とテキストの情報が交換され、互いに理解を深めます。これによって視覚的な解釈と文脈に基づく推論が一体化します。
CrossViTの発展背景

CrossViTは、視覚と自然言語の統合を推進する一環として生まれました。これにより画像処理や文書理解など多様な応用が可能となります。
具体的には、モデルは大量の教師データを利用して学習し、その結果、ユーザーとの対話能力向上に寄与します。
CrossViTにおける情報伝達

CrossViTは、画像データの分析からテキスト情報の生成へと連続的に情報を処理します。
その過程では、多層に渡るクロスアテンション機構が活用され、精度の高い双方向通信を実現しています。
CrossViTと従来モデルの比較
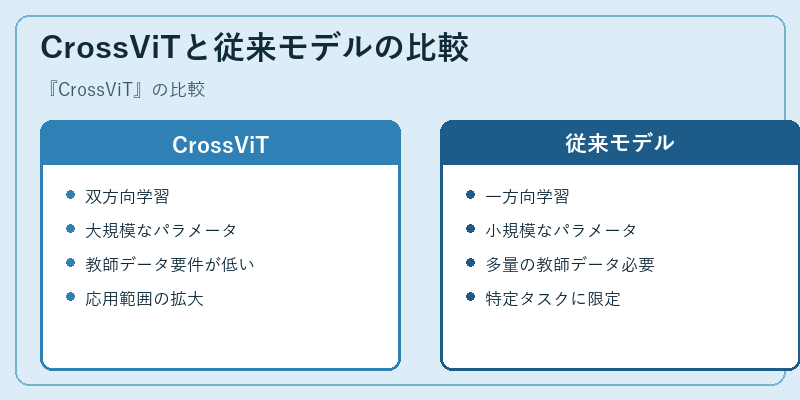
CrossViTは、従来の単方向モデルと比べて柔軟性と広範囲な応用可能性を備えています。
具体的には、双方向通信により、より少ない教師データでも高い性能を癐むことが可能です。
まとめ
CrossViTは画像とテキストの両方に対して優れた理解能力を持つことから、今後の機械学習における革新的な進展が期待されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







