
Daskは、大規模データ分析向けに設計された並列計算フレームワーク。PythonのPandasやNumPyと互換性があり、Scikit-LearnやXGBoostなどの機械学習ライブラリとの統合も可能。ここでは、Daskが抱える課題解決への貢献度やその技術的な特徴について掘り下げていく。
この記事の目次
- 並列処理のフレームワーク
- 歴史と発展
- 技術的仕組み
- 競合製品との比較
- まとめ
並列処理のフレームワーク

Daskは、MapReduceやSparkのアプローチから影響を受けつつ独自の方式を開発した。Daskのアーキテクチャは、タスクグラフと呼ばれる概念を採用し、効率的なスケジューリングと並行計算を行う。このアーキテクチャは、PythonのPandasやNumPyといったデータ操作ライブラリを容易に拡張可能にする一方で、新たな課題も生み出している。
歴史と発展
Daskは、2015年に開発者が問題解決のためのソリューションとして始動した。その後、コミュニティからの要求に応えてパフォーマンスと機能を拡張し続けている。現在では、大規模データセットに対して効率的な並列処理を可能にする強力なツールへと成長したが、依然として開発は続いている。
技術的仕組み

Daskは、Pythonライブラリとの統合を容易にするために遅延評価と呼ばれる技術を採用している。これはデータ変換の計算をすぐに実行せず、代わりにタスクグラフを作成する方法である。このアプローチにより、システムが効率的なスケジューリングを行うことが可能になる。
競合製品との比較
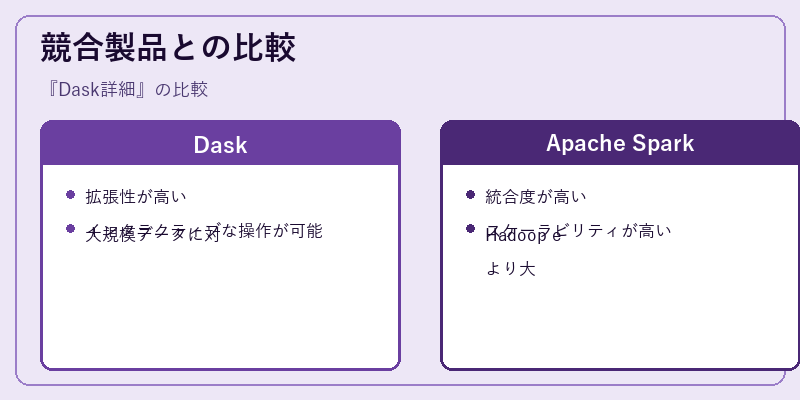
DaskとSparkは、大規模データ処理において重要な役割を果たす並列計算フレームワークである。しかし、両者は技術的なアプローチや目的の違いから異なる強みを持っている。例えば、Pythonとの統合が優れている点でDaskが有利な一方で、Hadoop生態系と連携しているSparkは、データウェアハウス規模のスケーラビリティにおいて優位性を示す。
まとめ
Daskのフレームワークは、大規模データ処理における効率化と柔軟性の追求に不可欠な要素であり、Python開発者コミュニティの成長とともに進化を続ける。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







