
データ増強は、機械学習モデルの訓練を補完する手法として発展し、特に視覚的タスクでの性能改善に効果的。深度学習初期から採用され、近年ではより高度な変換アルゴリズムが開発されている。
この記事の目次
- データ増強の定義と目的
- データ増強の歴史と進化
- データ増強の仕組み:画像認識への応用
- データ増強と合成データの比較
- まとめ
データ増強の定義と目的
機械学習における欠陥として、特に深度学習では大量の訓練データが必要である。そのため画像認識タスクを例に取れば、データ増強は既存データから派生した新たなサンプルを作り出し、モデルのパフォーマンスを向上させる技術となる。
具体的には、回転、反転、切り抜きなどの操作を通じて同一画像に対する多様な視点を得ることができる。これにより学習済みモデルは様々なパターンに対応でき、実世界での予測精度が向上する。
データ増強の歴史と進化
データ増強は2015年頃から深度学習の普及と共に脚光を浴び、単純な画像操作から複雑なパターン生成へと進化した。
初期にはデータの歪みやサイズ変更といった単純な方法が用いられ、次にカスタムアルゴリズムやGANといった高度な技術が取り入れられた。
データ増強の仕組み:画像認識への応用

画像データでは、特定の視点からのみ学習するよりも、多様な観察角度からパターンを抽出すると汎化性能が向上する。
具体的には、回転や反転により同一物体に対する異なる表現を得たり、クロップとスケーリングでサイズ変更を行ったりすることで、学習モデルはその物の視覚的特性をより深く理解できるようになる。
データ増強と合成データの比較
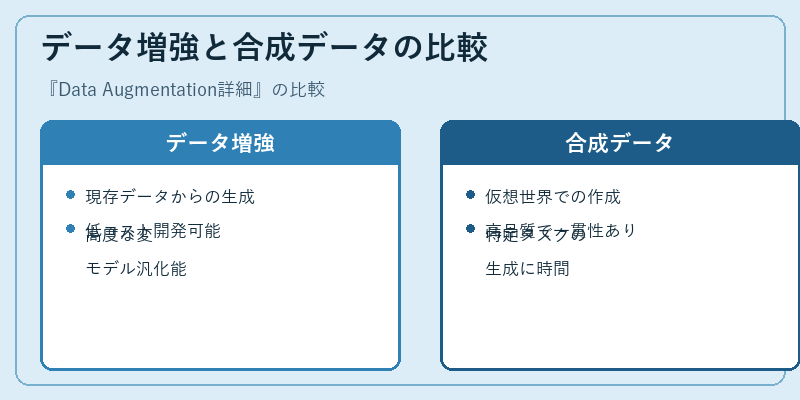
データ増強と合成データはともに訓練データ不足を解消するが、それぞれ異なるアプローチを採用している。
データ増強は既存のリアルデータを利用して新たなパターンを作り出しやすく、一方で合成データは仮想環境での一貫したシナリオ生成により特化したタスクに対して効果的である。
まとめ
データ増強技術は、画像認識など機械学習モデルの性能向上に不可欠な手法として、今後も継続的に進化と適用を続けるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







