
機械学習モデルのパフォーマンスを維持するため、データドリフトは欠かせない概念だ。この記事では、データドリフトの定義から最新の対応まで幅広く解説する。
この記事の目次
- データドリフトとは何か
- データドリフトの検出方法
- データドリフトへの対応策
- データドリフトと概念シフトの違い
- まとめ
データドリフトとは何か
データドリフトは、機械学習モデルが訓練された初期状態と運行中の現実世界におけるデータが異なることを指す概念だ。この差異は、モデルの性能を大きく左右する要因となる。
例えば、商品購入予測モデルにおいて、季節による需要変動や新製品投入などによって学習時に想定した行動パターンと現実が乖離すると、データドリフトが発生しやすくなる。
データドリフトの検出方法

データドリフトを早期に特定するためには、学習データとテストデータ間の統計的違いを探求することが有効だ。異常検知アルゴリズムやヒストグラム比較といった手法も利用可能。
また、時間経過による特徴量変動を追跡し、モデルの性能が低下する兆候がないか定期的にチェックを行うことが推奨される。
データドリフトへの対応策
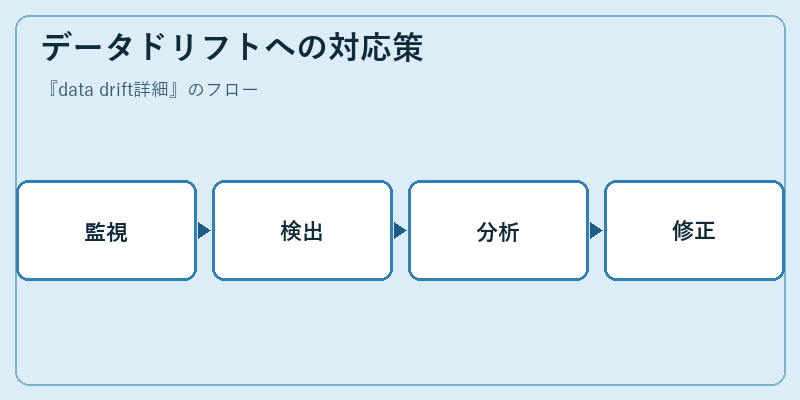
データドリフトが発生した場合、まず問題の範囲を把握するための監視から始める。次に、異常箇所を具体的な基準で検出し、その影響度を評価する。
その後、問題の本質を探り、適切な対処法を決定し、必要であればモデルの更新や新たな学習データの投入などを行って対応を行う。
データドリフトと概念シフトの違い

データドリフトと同様に、概念シフトも機械学習のパフォーマンスに影響を与える重要な現象だ。両者の違いを理解することで、より効果的な対策が可能となる。
例えば、消費者の嗜好が急激に変化した場合、データドリフトと概念シフトはそれぞれ異なる戦略が必要となる。
まとめ
データドリフトは機械学習モデルの維持管理において重要な役割を果たす。その特性や対策法を理解し、適切に対応することで、予測精度と信頼性を向上させることが可能だ。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







