
Databricksが提唱するLakehouseアーキテクチャは、データウェアハウスとデータレイクの最良要素を融合させ、大規模なリアルタイムデータ処理を可能にします。クラウドネイティブ設計のこの技術は、機械学習やAIアプリケーションにも広く利用されており、業界標準となりつつあります。
この記事の目次
- Lakehouseアーキテクチャの定義
- 歴史的背景と開発過程
- Databricks Lakehouseの技術仕組み
- Databricks Lakehouse vs. 他社製品
- まとめ
Lakehouseアーキテクチャの定義
Databricks Lakehouseは、データのストレージと処理を効率化するアプローチです。この技術は、企業が従来のデータウェアハウスとは異なる方法で、大規模な分散データセットを管理できます。
具体的には、LakehouseはテーブルフォーマットとしてApache IcebergやDelta Lakeを採用し、セマンティックレイヤーと呼ばれる概念を使用して統合性を向上させます。これにより、ビジネスインテリジェンスツールとの連携が容易になり、一貫したデータモデルの維持が可能になります。
歴史的背景と開発過程
Databricksは、2013年にサンフランシスコで設立され、その創設メンバーたちはApache Spark開発者の一員でもありました。初期段階から大規模データ処理と分散システムの問題解決に取り組んできました。
その後、データウェアハウスとデータレイクそれぞれの長所を活かしつつ短所を克服するため、独自のLakehouseアーキテクチャを開発しました。このアプローチは、データ統合性やパフォーマンス向上において大きな前進を遂げました。
Databricks Lakehouseの技術仕組み

Databricks Lakehouseは、Apache Sparkなどのパワフルな分析エンジン上で動作します。これにより、企業がビジネスインテリジェンスやデータサイエンスのニーズに対応することが可能となります。
また、API連携を通じて他のクラウドサービスともシームレスに統合でき、セキュアなアクセス制御を実現する機能も充実しています。これにより、信頼性と効率性が両立したデータ環境の構築が可能となります。
Databricks Lakehouse vs. 他社製品
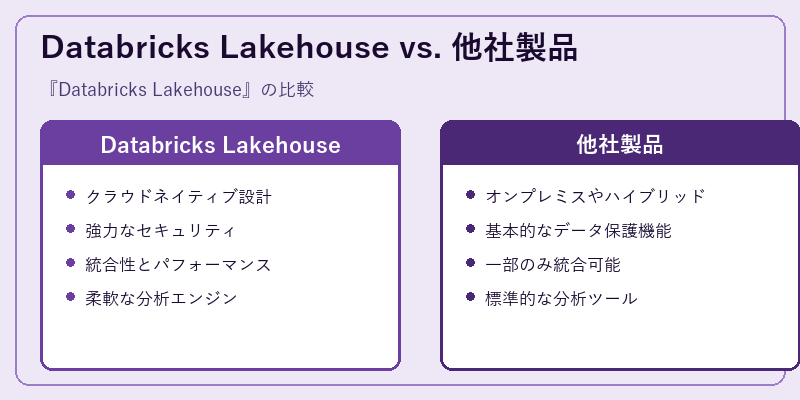
Databricks Lakehouseは、他の競合製品と比較して、クラウドネイティブ設計という点で優れています。これにより、迅速かつ効率的にデータを処理することが可能となります。
一方、他社の製品はオンプレミスやハイブリッド環境に特化している場合が多く、Databricks Lakehouseのような統合性やパフォーマンスの向上が難しいことがしばしばです。これにより、全体的なデータ管理の効率が低下する可能性があります。
まとめ
Databricks Lakehouseは、データ統合とリアルタイム分析における画期的なアプローチを提供しています。その強力な機能セットは、企業がデータドリブンの意思決定を行う上で大きな助けとなるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







