
2013年にDatabricks社が開発したApache Sparkを基盤とするDatabricksは、大規模な分散データ処理に特化した強力なクラウドサービスとして広く採用されている。本記事では、その背景と仕組みについて詳しく探る。
この記事の目次
- Databricksの誕生
- Databricksの主要機能
- 技術的アーキテクチャ
- 競合製品との比較
- まとめ
Databricksの誕生
DatabricksはApache Sparkを基盤とした技術革新の産物で、2013年にアミタブ・デイ氏らによって開発された。このプラットフォームはデータウェアハウス機能と機械学習フレームワークの統合を目指し、大規模なデータセット処理を可能にした。
具体的には、企業がクラウド上でのリアルタイム分析やマシンラーニングモデル開発を行う際、Databricksはそのニーズに対応する柔軟性と効率性の高さで注目を集めている。
Databricksの主要機能

Databricksは、パワフルなデータ処理エンジンだけでなく、ストレージ管理からユーザーインターフェースまでを包括的にサポートする。これにより、企業は大規模なデータウェアハウスを迅速に構築し、大量のデータに対して高度な分析を行うことが可能になる。
さらに、Databricksはセキュリティとガバナンスにも重点を置き、組織がデータ保護とプライバシー遵守を確保しながら効率的に作業を進めるための機能を提供している。
技術的アーキテクチャ
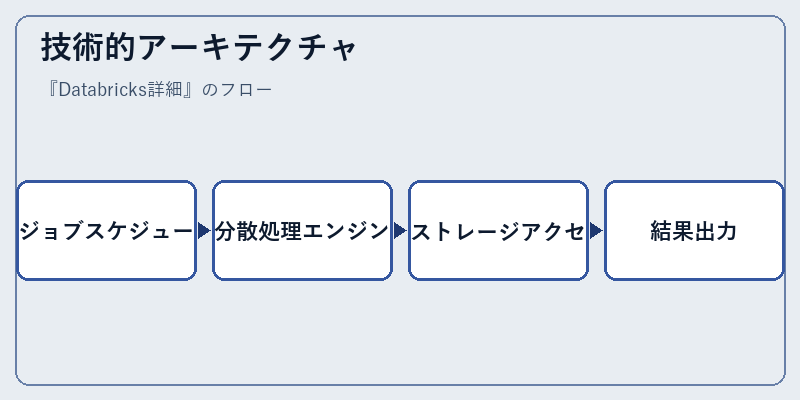
Databricksの内部では、Apache Sparkに依存する分散処理エンジンが中心的な役割を果たす。このエンジンは大量のデータを効率的に取り扱うことで知られている。ジョブスケジューリング機能により、タスクが適切な順序で実行され、リソースが最適に利用される。
また、Databricksは各種ストレージバックエンドとの連携も可能とし、柔軟性を高めている。これによって、ユーザーは様々なデータ形式やソースから情報を取得し分析することが容易となる。
競合製品との比較
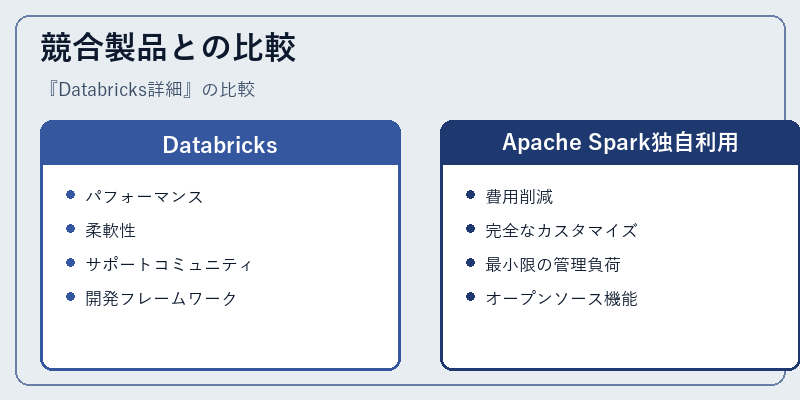
Databricksは、単にApache Spark上での開発を支援するだけでなく、その上で動作させるための環境やツールを提供している。これにより、ユーザーはより高いパフォーマンスと柔軟なアーキテクチャを得ることが可能となる。
一方で、Apache Sparkを独自で利用する場合、開発者は管理負荷やコストを抑えつつ、完全にカスタマイズ可能な環境を作り出すことができる。ただし、その実装には一定の技術的知識と時間が必要になる。
まとめ
Databricksは、大規模なデータ処理環境において高い効率性と柔軟性を提供する一方で、コストや管理負荷に関する考慮点も持つ。個々の状況に応じて最適な選択を行うことが重要だ。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







