
PyTorchなどの深層学習フレームワークにおいて、効果的なデータ管理と処理を可能にする重要なクラス。その詳細な機能や役割について、開発者向けに解説します。
目次
この記事の目次
- DataLoaderの定義
- 歴史と進化
- 内部仕組みの理解
- 他のライブラリとの比較
- まとめ
DataLoaderの定義
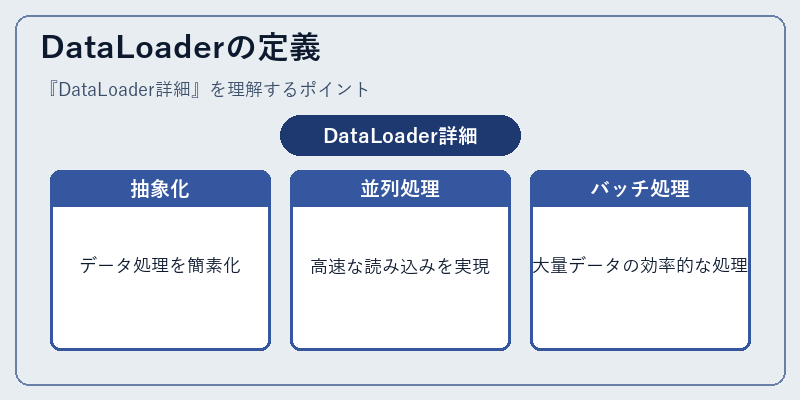
DataLoaderは、入力データセットから学習用のデータサンプルを生成し配るためのクラスです。
これにより、開発者は訓練モデルに必要な具体的なデータ操作を考える必要がなくなります。
歴史と進化
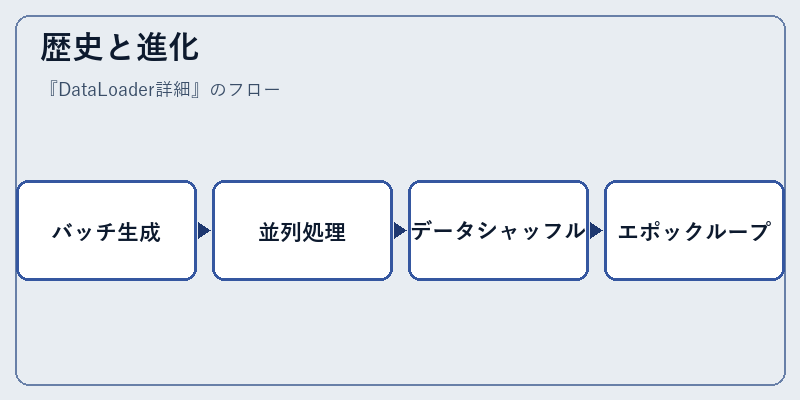
2016年にFacebookがPyTorchをリリースした際、DataLoaderは重要な役割を果たしました。
その当時から現在まで、バージョンアップと共に機能強化が続けられています。
内部仕組みの理解
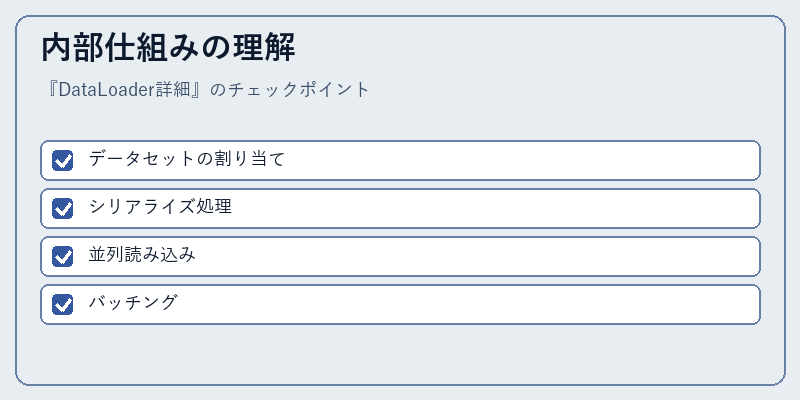
DataLoaderはデータセットと連携し、効率的なデータ配分を可能にします。
これらの機能により、深い学習モデルに対して最適な入力データを提供することができます。
他のライブラリとの比較
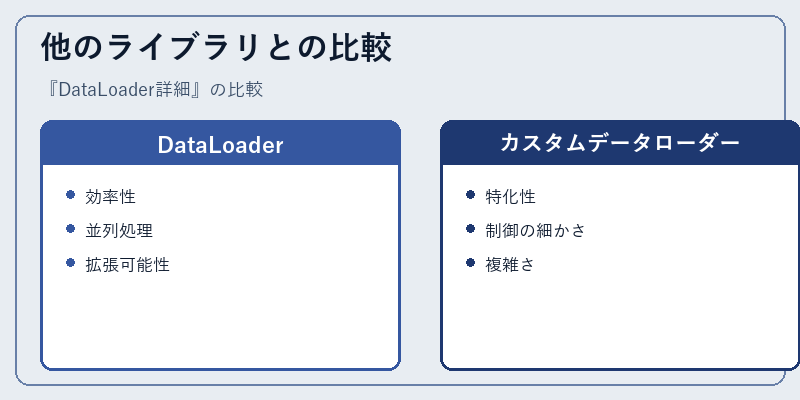
他のフレームワークや独自に開発されたクラスと比べて、DataLoaderはその柔軟な機能セットで優れています。
ただし特定のニーズに応じたカスタムソリューションも時には有効であるということが示されています。
まとめ
DataLoaderを上手く活用することで、深層学習モデルにおけるデータ処理の負担が軽減され、開発プロセス全体の効率性が向上します。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







