
データ匿名化は、デジタル時代におけるプライバシー保護の重要な手法である。1970年代にサイバネティクス理論家によって提唱され、現在ではGDPRやCCPAなどの法規制にもとづいて実装が進む。
この記事の目次
- 匿名化とは
- 匿名化の仕組み
- 匿名化とパーソナライゼーション
- 法律と規制
- まとめ
匿名化とは
匿名化は、個々のユーザーを特定できないようにデータを加工する過程である。これにより、個人情報保護が強化されると同時に、企業や研究機関の情報管理も容易になる。
例えば、オンラインショッピングサイトでは利用者の購買履歴に固有のIDではなく、乱数を使用することで匿名化を行う。
匿名化の仕組み
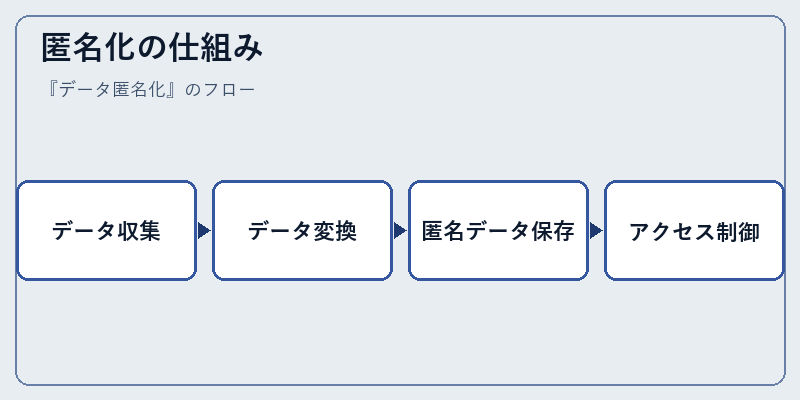
匿名化には特定のプロセスが存在し、まずは個人情報として扱われる全てのデータを抽出するところから始まる。その後、この情報を適切な方法で加工して匿名化を行う。
その後、匿名データは安全なサーバーに保存され、アクセス制御を通じて非許可ユーザーによる不正アクセスから守られる。
しかし、完全な匿名性確保には挑戦が伴う。例えば、大量の匿名化されたデータを解析することで、特定の個人が再識別される可能性があるため、適切な匿名化技術とガイドラインが必要となる。
匿名化とパーソナライゼーション

匿名化とパーソナライゼーションは相反する要素のように見えがちだが、適切なバランスを取りながら両方を実現することが可能である。
一方で匿名化は個人情報を保護し、その逆にパーソナライゼーションは個別のユーザー体騪の向上を目的とする。そのため、これらの技術の統合には高度なデータ管理能力が求められる。
法律と規制

近年の規制強化に伴い、匿名化技術は特に重要な地位を占めるようになった。GDPRやCCPAなどの法律では、個人情報の適切な取り扱いや保護について厳格な規定が設けられている。
これらの法規により、企業が匿名化プロセスの導入と強化を促されている。これには法的義務だけでなく、信頼性や安全性の向上も含まれる。
まとめ
データ匿名化は、個人情報保護とビジネス運用のバランスを取る上で不可欠な技術であり、適切な対応策を講じることでプライバシー保護と経済活動が共存することが可能となる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







