
データアノニマイゼーションは、個人情報保護の観点から重要性を増し続ける手法です。この記事では、その歴史と技術的進化、そして現在における活用例について解説します。
この記事の目次
- 匿名化とは何か
- 技術進化の背景
- 匿名化の仕組み
- 匿名化 vs データマスキング
- まとめ
匿名化とは何か

匿名化は、個人情報を非識別情報へと変換することで利用者のプライバシーを確保します。代表的な技術には、パーサブル・アノニマス(Pseudonymization)、キープリバシブ・データ・ストリーム(Differential Privacy)があります。
たとえば、病院では患者の個人情報を匿名化して医療データベースに保存することが一般的です。これにより、統計的な解析や研究が可能になる一方で、個々の患者を特定することは困難になります。
技術進化の背景

近年、データの量と種類が爆発的に増加したことで、匿名化技術も急速に進化しています。GDPRのような国際的な規制強化は、企業や組織における個人情報保護への取り組みを強く後押ししました。
さらに、人工知能(AI)の高度化とクラウド上のデータ管理が増えたことも要因となり、匿名化技術の開発は重要な分野となっています。これらの変化に対応するためには、セキュリティも考慮した柔軟なソリューションが必要です。
匿名化の仕組み
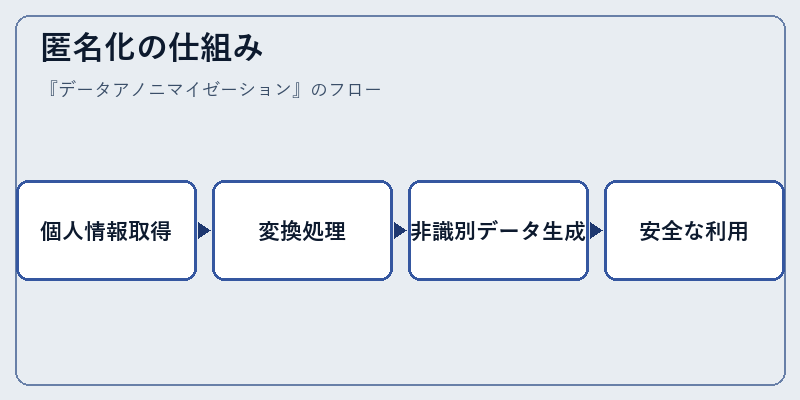
匿名化は、まず個々のデータを収集し、その後それを変形または置き換えます。この過程では、特徴的な情報を消去したり、ランダムな値に代用したりすることで個人識別が不可能となる非識別データを作り出します。
生成された匿名化データは、統計分析や機械学習のためのトレーニングセットとして利用できます。しかし、この過程で重要な情報量を失わないよう、適切なアルゴリズムの選択と適用が求められます。
匿名化 vs データマスキング

匿名化とデータマスキングは、どちらも個人情報を保護するための重要な手段ですが、それぞれに特徴があります。匿名化では、完全な非識別性を追求し、個々の情報からユーザーを特定することは困難です。
一方で、データマスキングではより柔軟なアプローチが採用され、部分的な隠蔽や復号可能により詳細な情報を必要とする場合に役立ちます。どちらの手法も適切なセキュリティポリシーに基づいて選択されるべきです。
まとめ
データアノニマイゼーションは、プライバシ保護とデータ利用性を両立させるための重要な技術であり、今後ますますその重要性が高まることが予想されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







