
2010年代初頭にIBMによって提唱された「データファブリック」は、分散したデータを一元的に管理・活用するためのアーキテクチャです。今ではAWSやAzureがこれを支援し、企業のデジタルトランスフォーメーション(DX)において欠かせない存在となっています。
目次
この記事の目次
- データファブリックとは
- データファブリックの歴史
- データファブリックの機能
- データファブリックと分散ストレージの比較
- まとめ
データファブリックとは
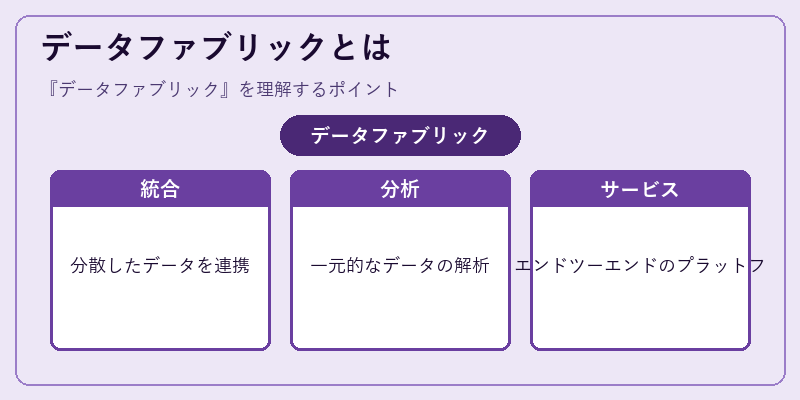
データファブリックは、組織内で存在する多種多様なデータソースを横断的に統合し、それらから得られる洞察情報をビジネスに活かす基盤です。
このアプローチにより企業は複雑なデータ環境において効率的な意思決定を行うことが可能になります。
データファブリックの歴史

2010年代初め、IBMは分散したデータ管理を改善するためのフレームワークとしてデータファブリックを発表しました。
その後、この概念は急速に普及し、AWSやAzureといったクラウドプロバイダーやSaaSプラットフォームとの統合が進んでいます。
データファブリックの機能

データファブリックは、一元的な視点から組織全体のデータを管理し、その上で最新技術を容易に導入することが可能です。
これにより従来よりも高度な分析や予測モデルが可能になり、ビジネス成果を向上させることができます。
データファブリックと分散ストレージの比較

分散ストレージでは、個々のデータソースは孤立したままとなり、全体像を把握しにくい状況が生じます。
一方でデータファブリックはそれらを包括的に管理することで、ビジネス上の課題解決に貢献します。
まとめ
データファブリックは分散した情報源を統合・分析するための強力なツールであり、今日のデジタル時代においてその重要性はますます高まっています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







