
データパイプラインとは、データ収集から処理、分析までのプロセスを自動化し一元管理する仕組み。1980年代のETL技術が起源で、クラウド時代に入り新たな展開を遂げている。
この記事の目次
- 定義と構成要素
- 技術の進化
- 主な機能と利点
- 主な製品と比較
- まとめ
定義と構成要素
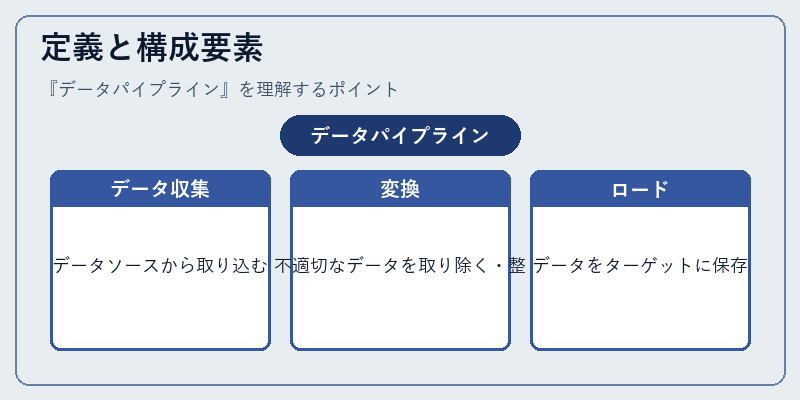
データパイプラインは、ビジネス分析の重要な要素である。具体的には、ログファイルやセンサーデータといった各種ソースから情報を引き出し、ビジネスに役立つ形へと変換し、最終的にデータウェアハウスやレポーティングツールなどに保存するプロセスを自動化します。
たとえば、Salesforceから顧客の行動履歴を抽出して分析用のテーブルへロードする場合、パイプラインはエラー処理やデータの一貫性を確保するための機能も持ちます。
技術の進化
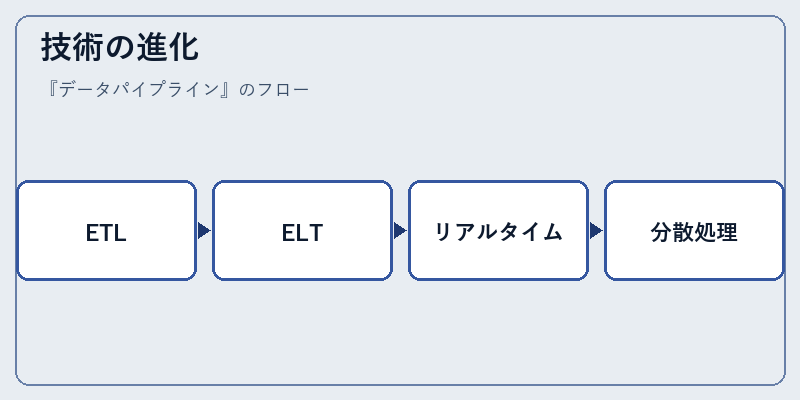
データパイプラインは、初期のETL(Extract, Transform, Load)から発展し、現在ではELT(Extract, Load, Transform)まで進化しています。後者はデータウェアハウス上でより柔軟な変換が可能で、処理効率を向上させることが期待されます。
また、リアルタイム分析や分散処理も重要なトレンドとなっており、これらは大量のデータを高速に扱い、ビジネス意思決定のスピードと精度を高める役割を果たします。
主な機能と利点
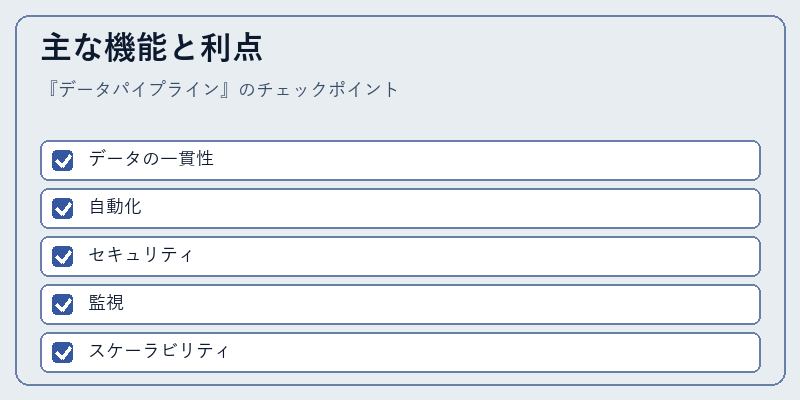
データパイプラインは、データの一貫性を保つためにエラー検出やデータ整形を行うとともに、継続的な処理のための自動化機能も提供します。
例えば、Pentaho Data Integrationのようなツールでは、これらの要素が統合されており、複雑なビジネス環境における効率的かつ安全なデータ管理を可能にしています。
主な製品と比較

Amazon EMRとGoogle Dataflowは、異なるアプローチを用いてビッグデータのパイプライン管理を支援します。EMRはPrestoやHadoopといったオープンソース技術に強力なサポートを提供し、S3との統合により柔軟性が向上しています。
一方、Dataflowはサーバーレスアーキテクチャと高度な分析機能を持ち、ストリームプロセシングも得意とする。両者の違いは主に、オンプレミスの柔軟さとクラウドネイティブの利便性のバランスです。
まとめ
データパイプラインは現代ビジネスにおいて不可欠な存在であり、その技術選択は組織全体の分析能力を大きく左右する
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







