
2014年にHintonらによって提案されたDropoutは、深層学習における過学習問題を解決する画期的な技術です。ニューラルネットワークの汎化性能向上に大きく貢献し、現在でも幅広い分野で利用されています。
この記事の目次
- Dropoutとは:定義と目的
- Dropoutの仕組みと実装
- Dropoutとその他の正則化手法
- Dropoutの変種と応用
- まとめ
Dropoutとは:定義と目的
Dropoutは、ニューラルネットワークの過学習問題に対処する技術です。訓練中に一部のノードを無効にすることで、モデルが訓練データを記憶しすぎることを防ぎます。これにより、未知のデータに対する予測精度が向上します。
具体的な例では、自然言語処理(NLP)における文章要約タスクでDropoutを使用すると、生成されたサマリーは訓練セットから独立した特徴を反映し、より幅広い文脈での理解に役立ちます。
Dropoutの仕組みと実装
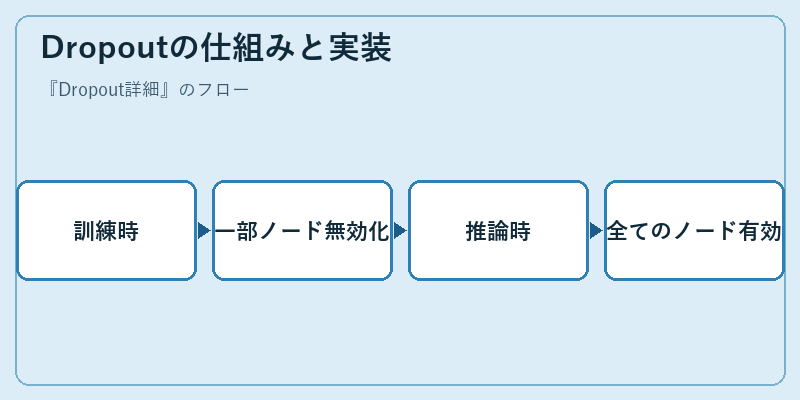
Dropoutは、ニューラルネットワークの学習プロセスを訓練と推論に分けて制御します。訓練時に特定の確率で一部のユニットを無効にすることで、モデルが訓練データからの過剰な情報依存を防ぎます。これにより、モデルはより汎用性のある特徴を学習するようになります。
具体的には、画像認識タスクにおいてDropoutを使用すると、ノイズや変形に対しても高い識別性能を維持できます。これは訓練データの多様化効果によるもので、モデルが特定パターンに偏らない柔軟な特性を獲得します。
Dropoutとその他の正則化手法
Dropoutは、L2正則化と比較して、より効果的に過学習を防止します。L2では重みパラメータのスムーズな分布を目指す一方で、Dropoutは訓練時にランダムにノードを無効にするため、モデルがより多くのパターン集合から特徴を抽出します。
具体的には、時間系列分析において、どちらの手法も過学習のリスクを低減します。しかし、Dropoutの方が多様なシーケンスパターンを学習できるため、将来の予測精度が向上する可能性があります。
Dropoutの変種と応用

Dropoutには多くのバリエーションがあり、特定のタスクに適した方法が開発されています。空間ドロップアウトは画像データに対して効果的で、局所的な特徴を保持しながら冗長性を除去します。
さらに、文脈に応じたドロップアウトも提案されており、自然言語処理では特に有益です。この手法により、文章の重要な部分は保持されつつ不要な情報が抑制され、より精緻な表現力を持つモデルが実現できます。
まとめ
Dropoutは、ニューラルネットワークにおける過学習問題を解決する効果的な手法であり、深層学習の発展に大きく寄与しています。今後もその応用範囲やバリエーションが広がり続けるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







