
Apache Druidは、大規模分散データセットを高速に処理するためのオープンソースデータストアです。2013年にPinterest社によって開発され、現在ではGoogleやNetflixなども採用しています。Druidは主にOLAPクエリに対するリアルタイムレポーティング機能を提供し、時間系列データの可視化において優れたパフォーマンスを発揮します。
この記事の目次
- Apache Druidとは
- Druidの開発と進化
- Druidの技術仕組み
- Druidと他のデータベース製品との比較
- まとめ
Apache Druidとは
Druidは、大規模な分散システムで高速にクエリを実行するための技術である。例えば、サービス利用状況やウェブサイトアクセス履歴などの大量のログデータに対応できるよう設計されている。
具体的には、Druidはデータを複数のノードに分散し、その上でパラレル処理を行うことで高速なデータ取得を可能にする。これにより、リアルタイム分析やダッシュボード更新が迅速に行えるようになる。
Druidの開発と進化

Druidは、Pinterest社が内部で使用していたデータ管理システムとして開発されました。その後、その能力と柔軟性から多くの企業に広く受け入れられていきました。
2015年にはApacheプロジェクトとなったことにより、さらに改良や機能追加が行われています。こうした進化の過程を通じて、Druidは現在では時間系列データを扱う最適なツールとして認知されるようになりました。
Druidの技術仕組み
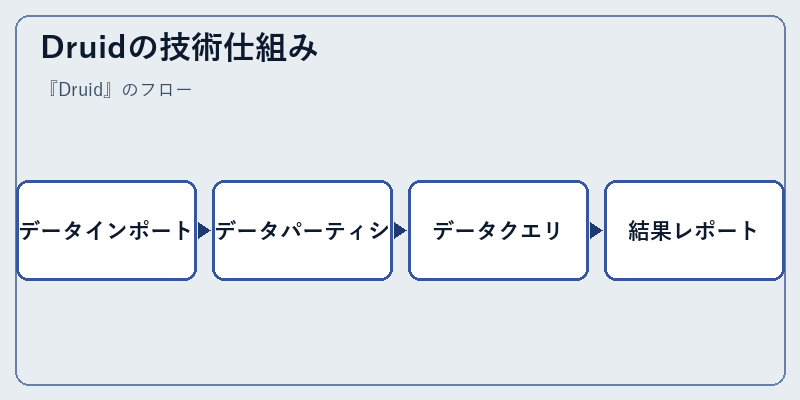
Druidは、大規模なデータセットを効率的に処理するための複雑なアルゴリズムとメカニズムを持つ。その構造は、高速な読み込みと書き込みを可能にするための設計となっています。
例えば、データインポート時に高度に最適化されたスキーマを利用することで、後のクエリプロセスにおいて迅速な結果が得られます。これにより時間系列データの可視化や分析が容易になります。
Druidと他のデータベース製品との比較
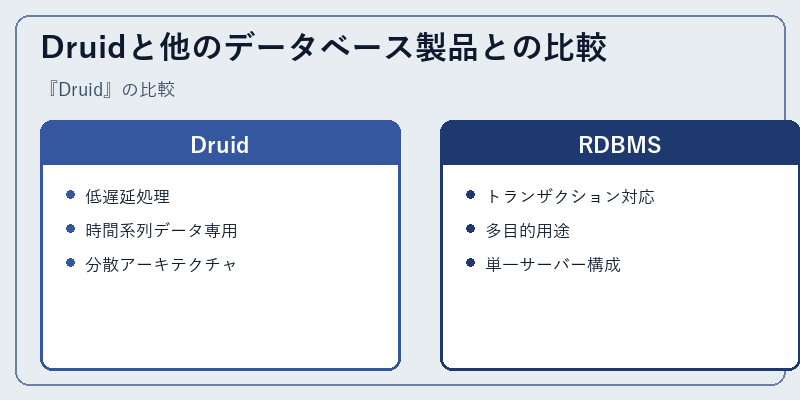
Druidは、リアルタイムでの大量データ処理を得意とする一方で、他のデータベース製品との比較では異なる強みが存在します。
具体的には、リレーショナルデータベース管理システム(RDBMS)と比べると、Druidはその特定のユースケースに最適化された設計をしているため、パフォーマンスや効率性において大きな違いが見られます。
まとめ
Apache Druidは、時間系列データを高速かつ効率的に処理するためのツールとして注目を集めている。その高度な機能と性能により、大量のイベントログやユーザー行動分析など、リアルタイムレポーティングに必要な要件に対応できる強力なソリューションとなる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







