
ElasticsearchのAnalyzersは、全文検索エンジンにおける重要な役割を果たす。この記事では、その歴史的背景、機能、そして現代的な応用について深く掘り下げていく。
この記事の目次
- Analyzersの基本構造
- Analyzerの歴史的進化
- 主要Analyzerの比較
- Analyzerの応用例
- まとめ
Analyzersの基本構造
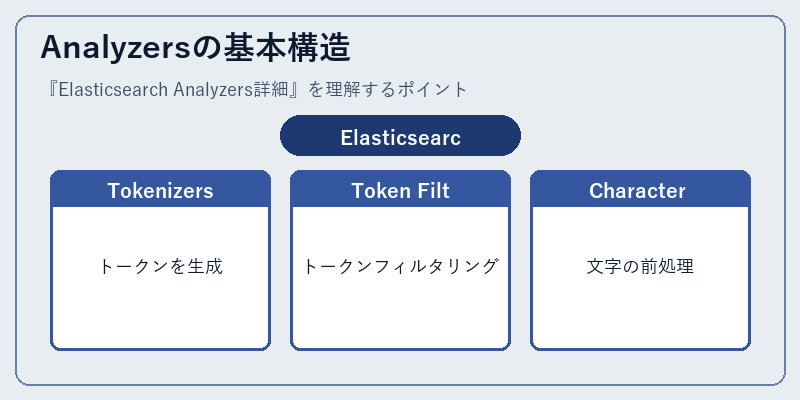
Elasticsearch Analyzersは、テキストを検索可能な単位に分解するためのモジュールです。その中心となる3つのコンポーネント:Tokenizer, Token Filter, Character Filterについて理解することは不可欠。
たとえば、シンプルなTokenizerが単語レベルでテキストを分割し、その後Token Filterはトークンリストから不要な文字や数字を取り除きます。Character Filterは、検索前に特殊な文字を置き換えたり削除したりします。
Analyzerの歴史的進化
Elasticsearch Analyzersは、2010年に初リリースされたElasticsearch 0.90と同時に登場しました。当時のシンプルな構造から始まり、徐々に複雑さが増し、今日では高度なテキスト解析を可能にしています。
例えば、言語固有のTokenizerやUnicode規格への対応など、開発者のニーズと技術進歩に対応しながら改良されてきました。
主要Analyzerの比較

Standard Analyzerは、英語文書の基本的な解析を提供します。一方、Snowball Analyzerはより高度な形態素処理を可能とし、言語ごとの特定の機能を備えています。
たとえば、Standard Analyzerは停用詞の除去や数字・文字の変換を行うのに対し、Snowball Analyzerは言葉の根幹部分へと解析範囲を広げます。
Analyzerの応用例

Elasticsearch Analyzersは、様々な業界やアプリケーションで広範に活用されています。たとえば、オンラインショップでは顧客レビューの分析に利用されることがあります。
また、検索エンジン最適化(SEO)でも重要な役割を果たし、ウェブサイトコンテンツに対するユーザーフレンドリーな検索体験を提供します。
まとめ
Elasticsearch Analyzersは、高度なテキスト解析と検索機能の基盤として、今日でも重要な役割を果たし続けています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







