
データ分析技術が発展し、大規模データ処理に焦点を当てる中、ELTとETLはその中心的な役割を果たしている。2000年代初頭から使用されてきたETLは、抽出、変換、ロードの工程で構造化データを統合する仕組みを提供したが、近年ではより柔軟性とスケーラビリティを重視するELTが台頭している。この記事ではその進化過程やそれぞれの手法の特徴について詳細に解説する。
この記事の目次
- ETLの基本構造
- ELTの登場と特性
- ETLとELTのワークフロー
- ETLとELTを比較
- まとめ
ETLの基本構造
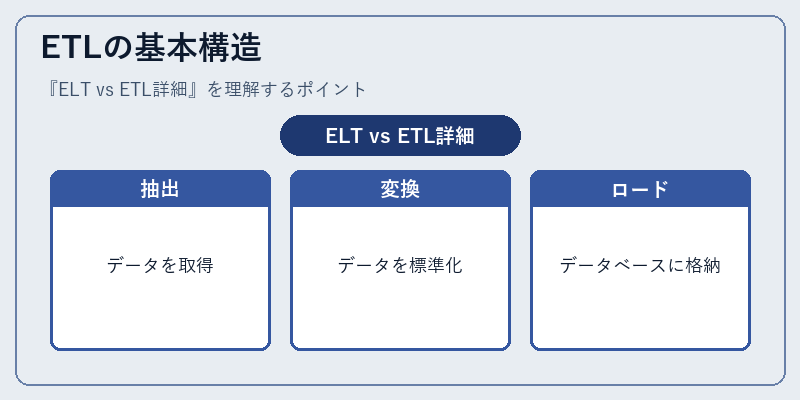
ETLは、主に3つのプロセスから成り立つ。最初のステップである「抽出」では、ソースシステムから必要な情報を取得する。次に「変換」を行い、データを統一的な形式に合わせる。最後に「ロード」としてデータベースへ保存される。
従来型DBやBIツールといった構造化された環境でETLは効果的であり、その具体的な利用例としてはSalesforceからOracleへのデータ移行などが挙げられる。
ELTの登場と特性
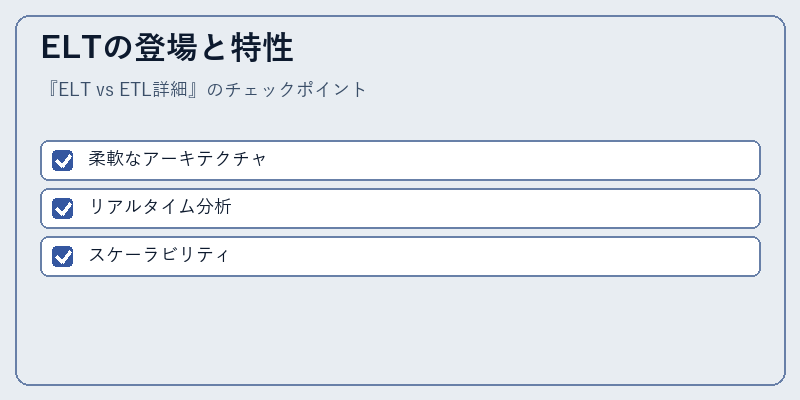
ELTは2010年代に入り、Hadoopやクラウドベースのデータウェアハウスが普及したタイミングで脚光を浴びた。その特徴は柔軟なシステム設計と高速処理能力にある。
具体的には、まず大量のデータをロードし、必要に応じてクエリ処理を行うという手順だ。このアプローチにより、迅速かつ効率的なビジネスインテリジェンスが可能になる。
ETLとELTのワークフロー
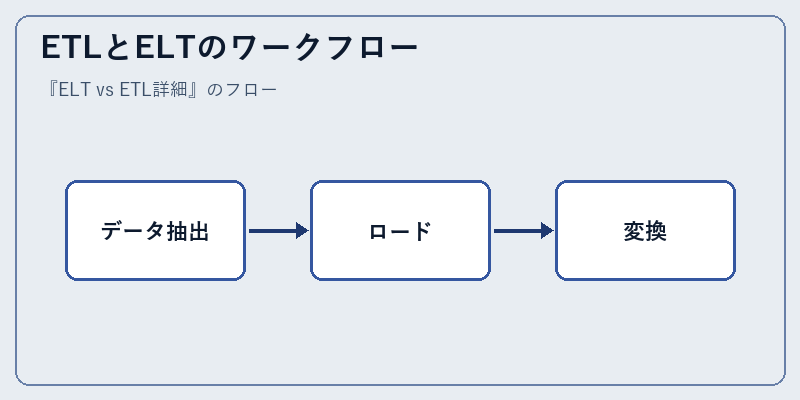
ETLとELTはプロセスの流れで大きな違いを持つ。その差異を理解するには、両者のワークフローを見比べるのが有効だ。ETLではデータの変換が先行するのに対し、ELTではまずロードを行う。
この順序の違いにより、処理速度やシステム負荷が大きく異なることが容易に想像できるだろう。
ETLとELTを比較
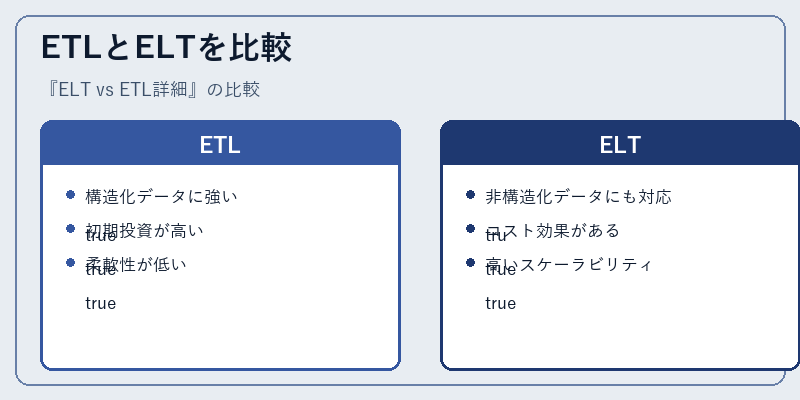
ETLとELTの主な違いは、処理アプローチや費用面にある。ETLは既存のデータウェアハウスとの親和性が高い一方で、新しい取り組みへの柔軟性が不足している。逆にELTは、クラウド環境での活用が進むなど、新技術に対する適応力がある。
また、コスト効果面でも違いがあり、特にデータ量が多い場合、ELTの方が経済的であることが多くなる。
まとめ
ETLとELTはそれぞれの利点を持ち、特定の環境では優れたパフォーマンスを発揮する一方で、他の状況では制約や課題も生まれる。これらの手法を正しく評価し、最適な選択を行うためには、プロジェクト固有の要件とアーキテクチャを理解することが必要となるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







