
自然言語処理におけるベクトル化技術であるEmbedding Model選定。近年、文脈を考慮したより洗練されたモデルが登場し、テキストデータ分析におけるパフォーマンス向上に貢献しています。この記事ではその進化と現状について掘り下げます。
この記事の目次
- Embedding Modelとは
- 選定プロセスの重要性
- 進化の歴史と現状
- 主なEmbedding Model比較
- まとめ
Embedding Modelとは
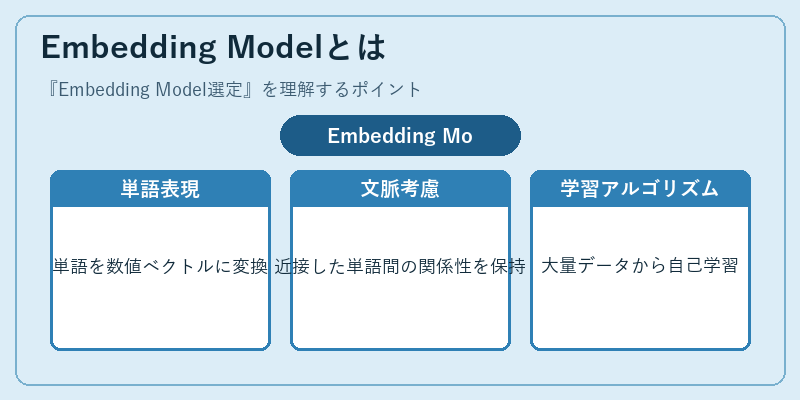
Embedding Modelは、機械が人間言語を理解するための基盤技術です。単純な文字列としての意味ではなく、文脈や関連性に基づいて各単語またはフレーズにベクトル表現を与えることで、テキスト分析の精度を高めます。
近年の進化では、より深い学習アルゴリズムが用いられ、長文間の概念的類似度も把握できるようになりつつあります。代表的なモデルとしてはWord2VecやBERTがあります。
選定プロセスの重要性
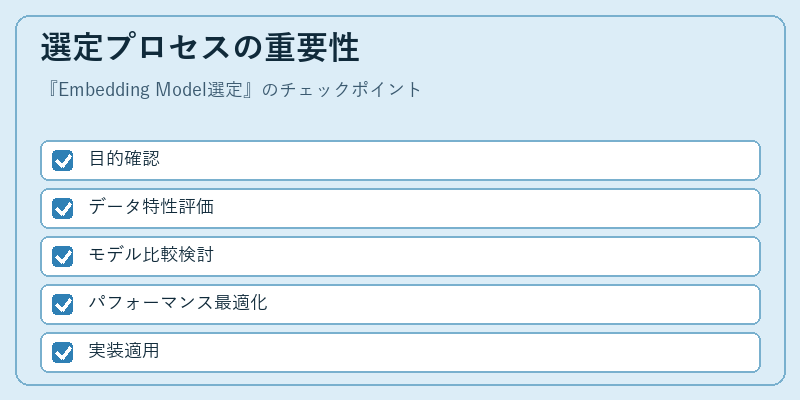
Embedding Modelの選定においては、その用途やデータ性質に応じた適切なモデルを選ぶことが不可欠です。目的が何であるかを見極め、さらに分析対象のデータの特性を詳細に調査することが求められます。
また、候補となるモデルについて比較検討を行い、最終的にパフォーマンスが最適化されたものを選択するプロセスは欠かせません。
進化の歴史と現状
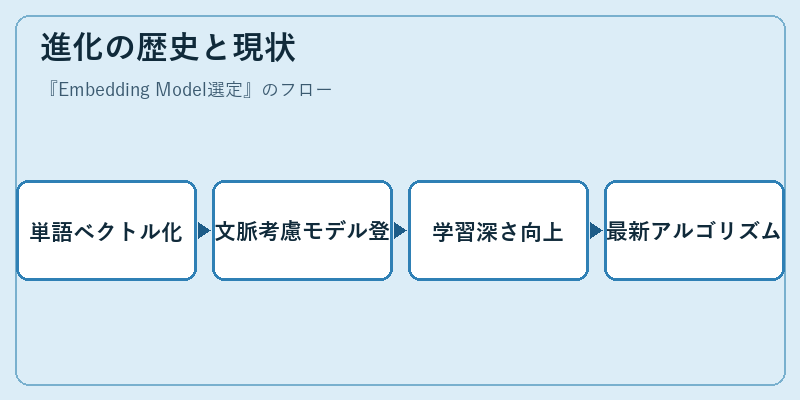
Embedding Modelは、その歴史を遡ると単純な単語ベクトル化から始まりました。その後、単に一義的な意味だけでなく文脈における関係性も考慮するモデルが開発され、さらに進化しました。
今日では、より深い学習アルゴリズムの適用により、長文間の概念的類似度すら把握できるようになったという点で大きな飛躍を遂げています。
主なEmbedding Model比較
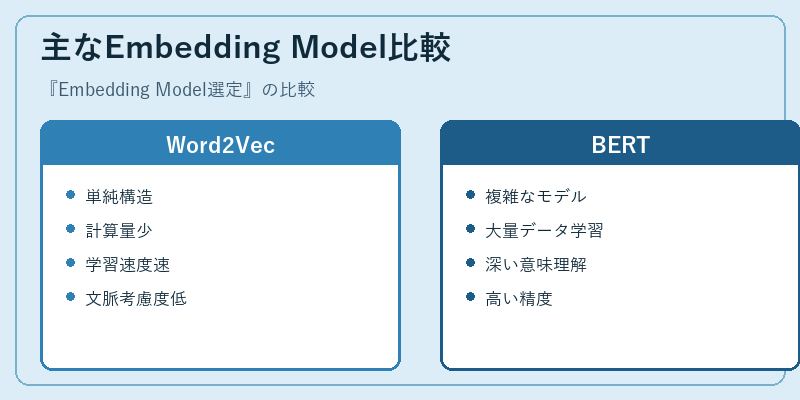
Word2VecとBERTは代表的なEmbedding Modelですが、それぞれの特性や適用範囲が異なります。Word2Vecは単純なモデルであり計算量も少なく、文脈考慮度に比べて低いものの、学習速度が速い特徴があります。
一方で、BERTはより複雑なモデルを採用し、大量のデータから深い意味理解を可能とします。その結果、高い精度を発揮する反面、計算量や学習時間は増加します。
まとめ
Embedding Model選定において、目的に応じて最適なモデルを選択し、パフォーマンスの最大化を目指すことが求められます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







