
エンベディングとは、文字や単語といった離散的なデータを連続値のベクトルに変換する手法です。近年の自然言語処理では不可欠な存在となり、モデルの効率化と精度向上に貢献しています。
この記事の目次
- エンベディングとは
- エンベディングの歴史と進化
- エンベディングの仕組み
- エンベディングとワンホット表現
- まとめ
エンベディングとは
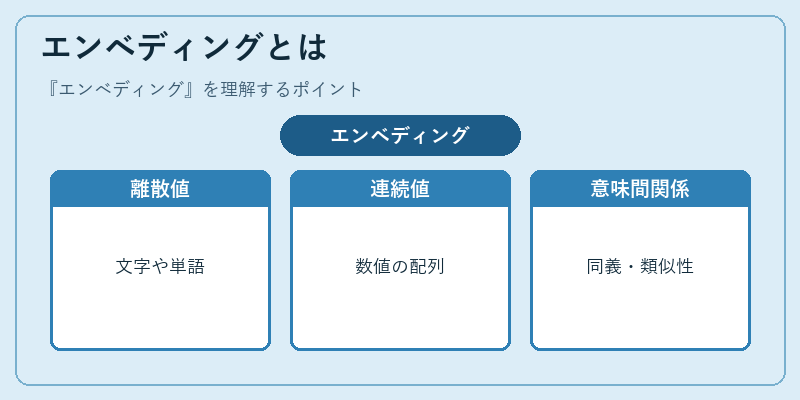
エンベディングは、テキストデータを意味的特徴を持つ連続値に変換します。具体的には、同種の単語が近接するように配置することで文脈と意味間関係を捉えます。
例えば、「犬」と「猫」は動物という共通項を持ちますが、それぞれ固有の特性も持ちます。エンベディングではこれらの複雑な関係性を数値で表現します。
エンベディングの歴史と進化

エンベディングの開発は2013年のCBOWとSkip-gramモデルから始まりました。これらの初期技術は単語同士の意味関係を捉えることに成功しました。
その後、Word2VecやTransformerに基づくTransformer言語モデルが登場し、より複雑な文脈理解を可能にしています。最近ではBERTのような強力なエンベディング技術が広く使用されています。
エンベディングの仕組み

エンベディングの基本的な動作は、まずテキストを数値インデックスに変換することから始まります。その次にはネットワークの重みが反復学習によって更新され、最終的に意味的特徴を抽出したベクトル空間が形成されます。
これらのベクトル間では、語彙の類似性や文脈関係が距離や内積などの数学的な手段で評価できます。こういった技術は機械学習モデル全体の性能向上に寄与します。
エンベディングとワンホット表現
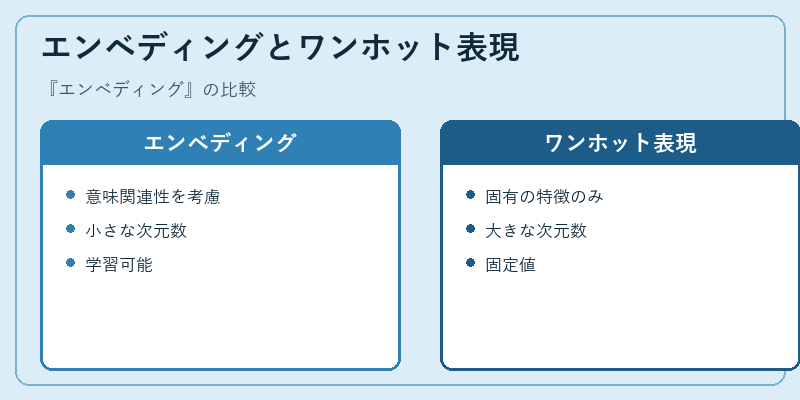
エンベディングと対比されるワンホット表現は、文字列を1-of-N形式で処理します。これは単語それぞれが独立した特徴を持つと解釈されます。
一方のエンベディングでは文脈や類似性に基づき低次元空間で効率的な表現を行い、モデルに学習させることが可能です。
まとめ
エンベディングは自然言語処理における重要な手法であり、テキストデータを適切な形式へ変換する役割を果たします。その多様なアプリケーションは今後ますます進化していくでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







