
エンコーダーとデコーダーから成るこのアーキテクチャは、機械学習において言語翻訳や文章生成などのシーケンシャルタスクを効率的に解決する基盤となりました。ここでは、その仕組みの特徴や応用事例について深掘りします。
この記事の目次
- Encoder-Decoder の基本構造
- Encoder-Decoder の歴史的背景
- Encoder-Decoder の仕組みの詳細
- Encoder-Decoder と Transformer の比較
- まとめ
Encoder-Decoder の基本構造
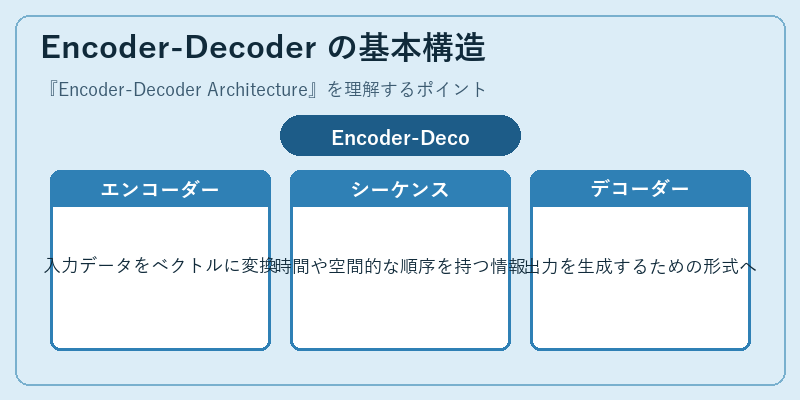
Encoder-Decoderアーキテクチャは、まずエンコーダーが入力データを抽象化したベクトルに変換します。これにより、複雑な情報構造も扱いやすく。
続いてデコーダーがその情報を解読し、必要な出力を生成します。このプロセスは言語翻訳や文章の要約など、多くのアプリケーションで利用されています。
Encoder-Decoder の歴史的背景

Encoder-Decoderは、Seq2Seqモデルとして最初に提案され、その後Attentionメカニズムの導入により精度が大きく向上しました。
これらの改良を経てTransformerなど現代的なアーキテクチャへと発展し続けています。
Encoder-Decoder の仕組みの詳細
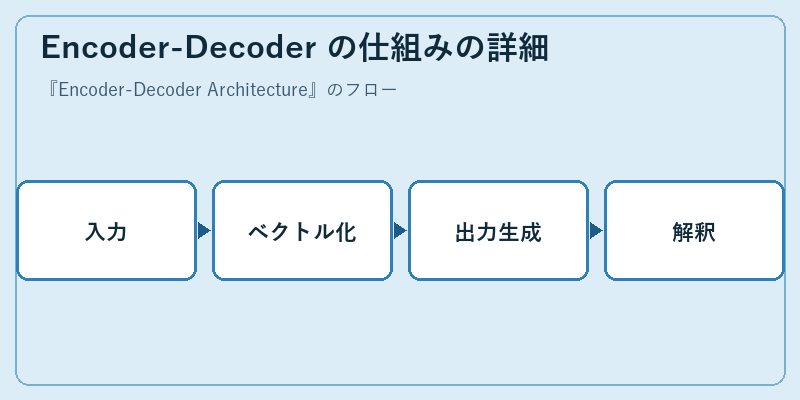
エンコーダーでは、まずテキストが逐次処理され、その情報が全体の意味を表すベクトルに圧縮されます。
これを受けてデコーダーは、適切な形式で出力を生成し解釈します。このプロセスは複雑なデータ間の関連性を捉えるのに優れています。
Encoder-Decoder と Transformer の比較
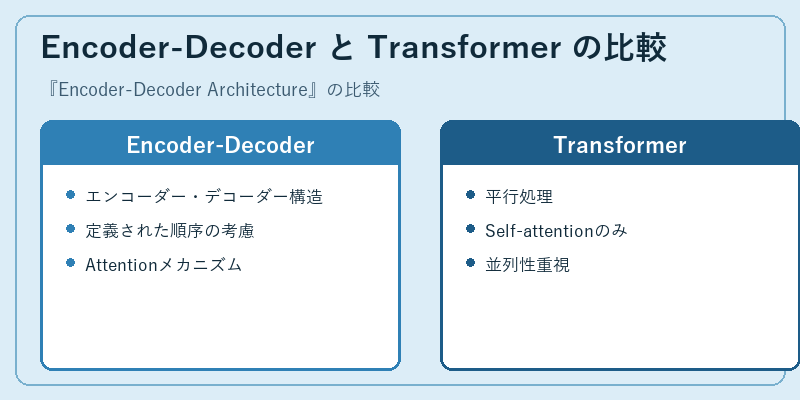
Encoder-Decoderアーキテクチャはエンコーダーとデコーダーを明確に区別します。これにより、順序付けられた入力データの解析が容易になります。
一方で、Transformerでは全ての情報を同時に処理するため、大規模なデータセットに対しても効果的です。
まとめ
Encoder-Decoderアーキテクチャは、言語翻訳や自然言語生成といったタスクにおいて不可欠な役割を果たしていますが、Transformerモデルの登場により新たな進化も見られています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







