
EVAはViT(Vision Transformer)の変種であり、近年画像認識における注目を浴びているモデルです。本記事では、その特徴、進化経緯、そして他の深層学習アーキテクチャとの違いについて解説します。
目次
この記事の目次
- EVAの定義と起源
- EVAの仕組み
- EVAと他のモデルの違い
- EVAによる画像認識の進化
- まとめ
EVAの定義と起源
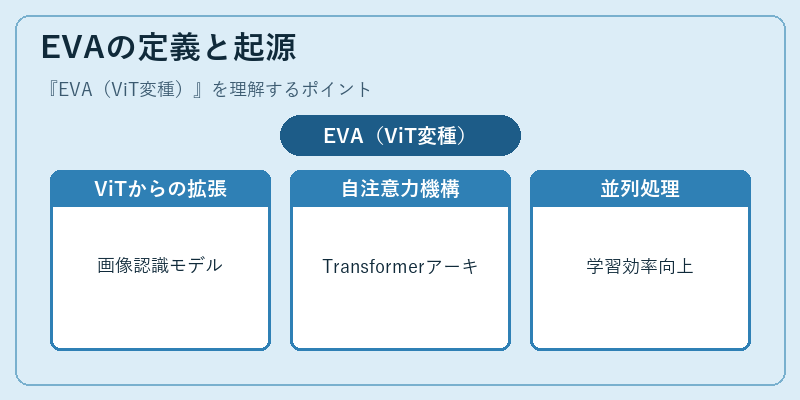
EVAは、Vision Transformerをベースに開発された深層学習モデルです。
このモデルでは、ViTの構造を拡張し、自注意力機構と並列処理による計算効率化が実現されています。
EVAの仕組み

EVAは画像データを受け取り、それに対してエンコーダによる情報処理を行います。
結果として得られた情報を用いて最終的な出力を決定し、必要に応じてフィードバックが行われます。
EVAと他のモデルの違い
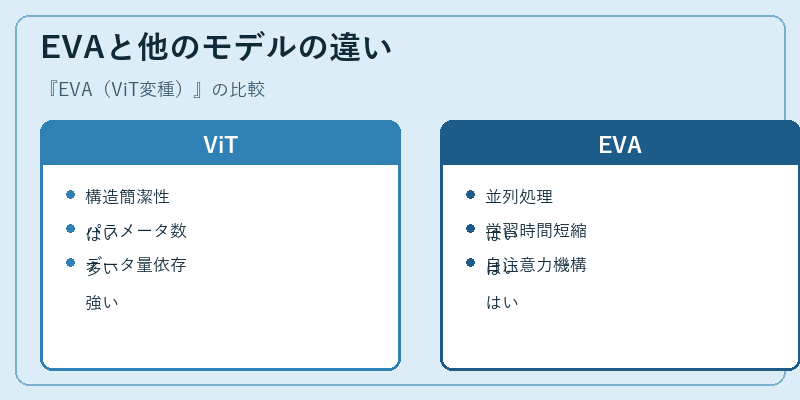
ViTと比較して、EVAでは入力データのパラメータ数が多くなりますが、その一方で並列化により効率が向上します。
また、データ量に対する依存度も低く抑えられるため、大きなデータセットがない場合でも性能を発揮する可能性があります。
EVAによる画像認識の進化

EVAは画像認識タスクにおいて高い精度を達成し、また効率的な学習と高速なインファレンスを可能にします。
その結果として、複雑なタスクへの適用が加速され、さらなる進化の可能性を開くこととなりました。
まとめ
EVAはViTから派生した画像認識モデルであり、並列処理や自注意力機構といった特徴を有しています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







