
Faunaは、2015年に設立されたクラウドネイティブなデータベースとして登場し、すぐにサーバーレス技術の先端に立ちました。その強力な機能と柔軟性により、開発者は複雑なストレージと検索要件を容易に解決できるようになりました。
この記事の目次
- Faunaとは
- Faunaの歴史と発展
- Faunaの仕組み
- Fauna vs AWS DynamoDB
- まとめ
Faunaとは
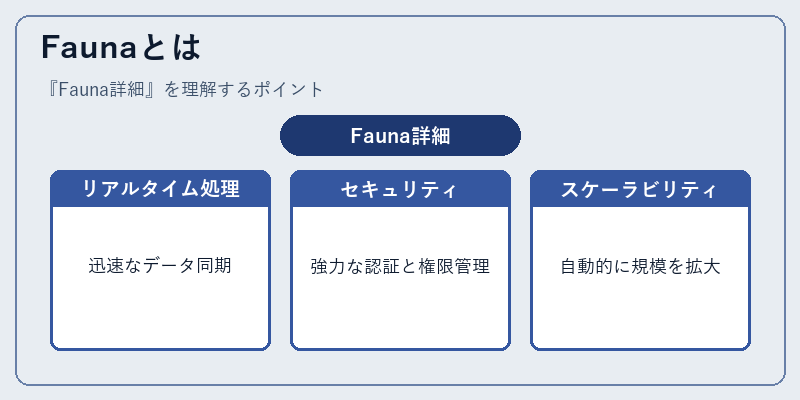
Faunaは、一連のサーバーレスサービスを通じてデータを効率的かつ安全に管理できるフレームワークです。開発者はAPIを利用して、データベースと通信し、リアルタイムな操作や高速な検索が可能になります。
このプラットフォームは、分散型アーキテクチャの利用により、サービスのスケーラビリティを向上させています。これにより大規模なアプリケーションでも安定したパフォーマンスを維持できます。
Faunaの歴史と発展
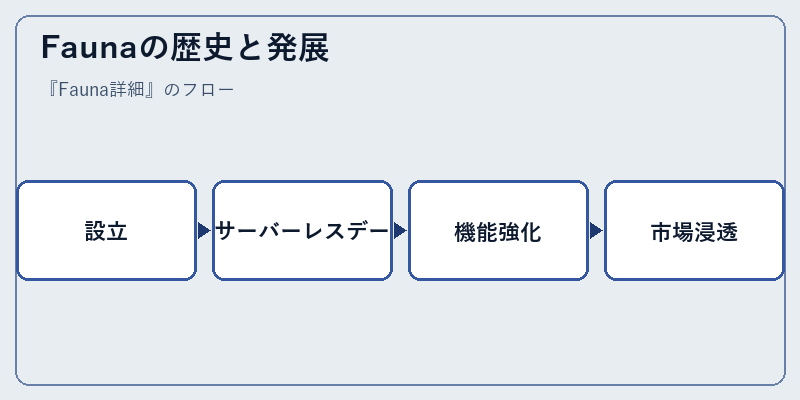
Faunaは、数年前にデータ管理技術を革新するという目的で誕生しました。その後、急速な進化を通じて現在では多くの企業が信頼できるプラットフォームとなっています。
開発者はFaunaの柔軟性と機能強度から恩恵を受け、高度なデータ操作や安全な情報管理を実現しています。これらの特徴は特にクラウドネイティブなアプリケーションにおいて高く評価されています。
Faunaの仕組み

Faunaはサーバーレスアーキテクチャを採用し、開発者はデータベースの設定や維持に必要な手間が最小限で済みます。また、リアルタイムな同期機能によって、アプリケーションの更新と反映が迅速に行われます。
このプラットフォームはSQLとNoSQLの両方をサポートしているため、幅広いデータ要件に対応可能であり、開発者は最適な技術を選択することができます。
Fauna vs AWS DynamoDB
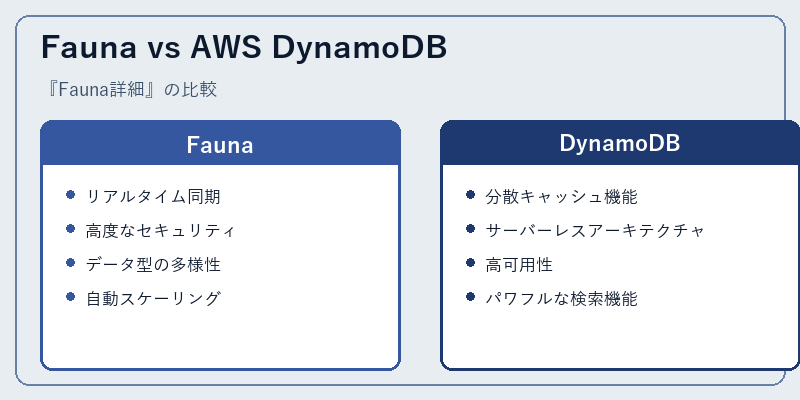
FaunaとAWSのDynamoDBは、データベースニーズを満たすための有力な選択肢ですが、それぞれが異なる特性や強みを持っています。Faunaはその柔軟性とセキュリティで知られています。
一方、DynamoDBは分散キャッシュ機能などの特徴から、特定のアプリケーションニーズに最適化されています。開発者はこれらを比較することで自社のプロジェクトにとって最も有益なソリューションを見つけることができます。
まとめ
Faunaはサーバーレスデータベース領域において革新的で効率的な解決策を提供しますが、特定のニーズに最適かどうか評価するためにはその技術と仕組みを深く理解することが求められます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







