
Feature Storeとは機械学習プロジェクトにおける特徴データを一元管理する重要な技術です。その始まりから現在に至るまでの歴史と、Feastが果たす役割について詳しく見ていきましょう。
目次
この記事の目次
- Feastの定義と目的
- Feastの機能と仕組み
- Feastの歴史的背景
- Feastと他のフレームワークの比較
- まとめ
Feastの定義と目的
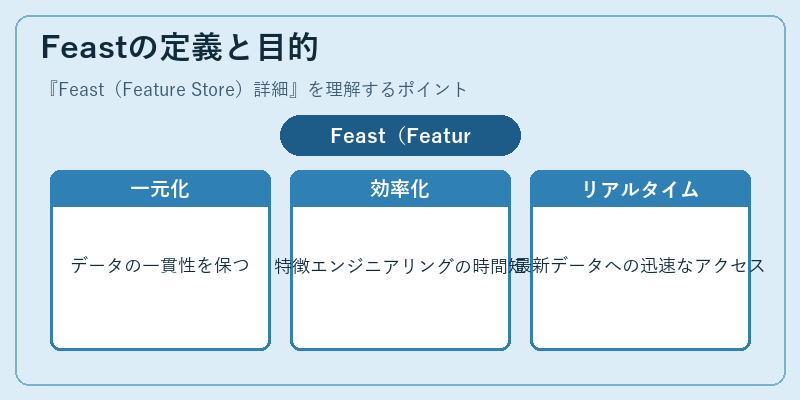
Feastは、機械学習モデル開発における特徴データの管理と共有を容易にするフレームワークです。これにより、
データサイエンティストは、効率的に新しい特徴を作成し、既存のものに対して迅速な更新を適用することが可能になります。たとえば、顧客属性のアップデートや最新の行動パターンの分析に利用されます。
Feastの機能と仕組み
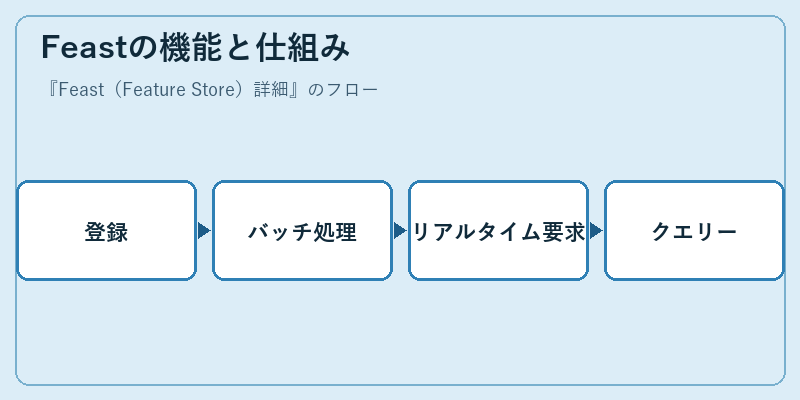
特徴データを効果的に利用するためには、Feastが提供する機能の理解が必要です。例えば
データソースからの特徴登録やバッチ処理での更新を行い、リアルタイム要求に応じてクエリーを生成します。このプロセスは全て自動化されており、手間のかかる作業から解放されます。
Feastの歴史的背景

Feastは2019年に登場し、それ以前の特徴データ管理の課題を解決するために開発されました。
初期段階では主に大規模な機械学習プロジェクトで使用され、その後、様々な業界に広がりを見せています。
Feastと他のフレームワークの比較

Feastは、類似の特徴データ管理ツールと比較して優れた性能を発揮します。
これは特に大規模なシステムや複雑なビジネス要件に対応する際には顕著に表れます。
まとめ
Feature StoreとしてのFeastは、特徴データ管理における効率性と信頼性を向上させることで、機械学習プロジェクト全体のパフォーマンスを強化します。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







