
Apache Flink Table APIは、分散データ処理フレームワークFlinkにおけるSQLとの統合を容易にする重要な要素です。開発者のデータアクセスや処理を柔軟にし、大規模なリアルタイム分析も可能としました。
この記事の目次
- Flink Table APIとは
- Flink Table APIの歴史
- Flink Table APIの仕組み
- 他の分散処理フレームワークとの比較
- まとめ
Flink Table APIとは
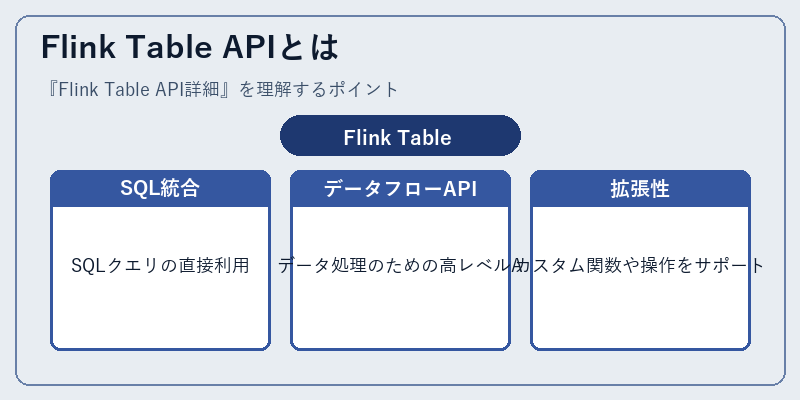
Flink Table APIは、分散データ処理フレームワークApache Flinkの中で、SQLとの統合とデータフロープログラミング間の連携を実現する役割を持っています。
このAPIは開発者に柔軟な操作や高度な分析機能を提供し、例えば複雑なJoin処理やWindow関数を使用したリアルタイムアプリケーションの開発を可能とします。
Flink Table APIの歴史
Flink Table APIは2015年頃から開発が始まり、SQLとの統合機能が追加されつつ進化してきました。
このAPIはApache Flinkの版アップデートを通じて多くの改善を受け、分散処理システムにおけるデータ操作の柔軟性とパフォーマンスを向上させました。
Flink Table APIの仕組み

Flink Table APIは、データフローの抽象化とSQLクエリの実行を統合し、開発者の作業負担を軽減します。
このAPIは複雑なデータ処理のための柔軟性を持ち、カスタム関数やWindow処理などの高度な操作が可能となっています。
他の分散処理フレームワークとの比較
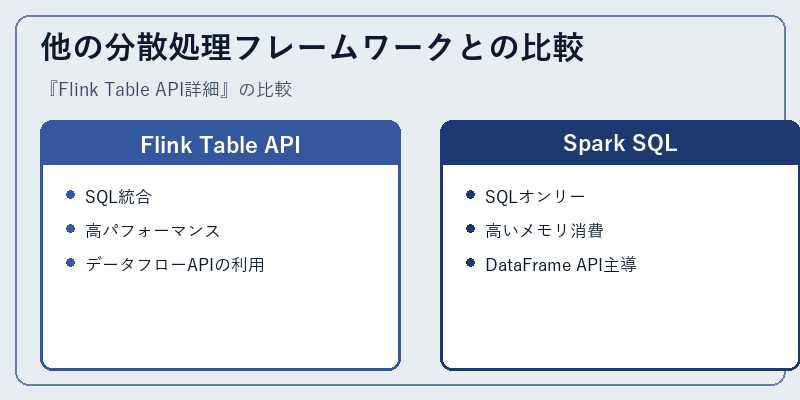
Flink Table APIはApache Flink特有の機能であり、他のフレームワークとの比較では独自性が際立ちます。
例えばSpark SQLと比較すると、パフォーマンスやメモリ効率、そしてAPI体系において異なる特性を持つことが分かります。
まとめ
Apache Flink Table APIは分散データ処理における柔軟性とパフォーマンスを向上させる重要なツールです。開発者はこのAPIを活用することで、リアルタイム分析や複雑なデータ操作に取り組むことができます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







