
FL Frameworkは分散型マシンラーニングの主要ツールで、エッジデバイス間でのデータ共有を可能にし、プライバシーとセキュリティを保護します。ここではその仕組みや特性について詳しく解説します。
この記事の目次
- Flowerの機能と目的
- Flowerの技術的背景
- Flowerの構築と実装
- Flowerと他のフレームワークの比較
- まとめ
Flowerの機能と目的
Flowerは、エッジコンピューティングにおける機械学習モデルのトレーニングを効率化するためのフレームワークです。このツールは、多数の分散デバイスが同時に動作し、データ共有とプライバシー保護のバランスを取ることが可能です。
具体的には、Flowerはサーバー側でモデルのパラメータを集約し、エッジデバイスでは個別の訓練データを使用してローカル学習を行います。これにより、大規模なデータセットを扱う際の通信コストやセキュリティリスクが軽減されます。
Flowerの技術的背景

Flowerは、分散型機械学習アルゴリズムであるFederated Learning(FL)に基づいています。このアプローチでは、多くのエッジデバイスが同期的または非同期的に協調してモデルをトレーニングします。
開発者や研究者はPythonでFlowerを簡単に導入できる一方、そのフレキシブルな設計は他のプログラミング言語への移植にも対応しています。これにより、多様なデバイス環境での活用が可能となります。
Flowerの構築と実装
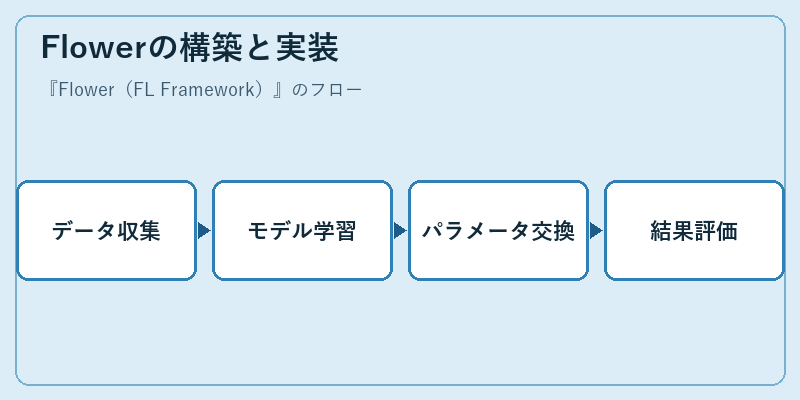
Flowerを使用してプロジェクトを始める際、まず最初のステップは適切なデータセットの選定と収集です。次に、それらのデータを使って初期モデルをトレーニングします。
その後、サーバーとエッジデバイス間で学習済みパラメータの交換を行います。最後に、モデルの性能評価を行い、必要であれば改善策を講じます。これにより、Flowerは実世界での応用が可能となります。
Flowerと他のフレームワークの比較

Flowerは分散環境下での効率的な機械学習に特化しており、エッジデバイス間の通信を最適化します。これに対してSpark MLlibはデータ処理とビッグデータ分析のためのフレームワークで、より広範囲なアプリケーションに対応しています。
両者の大きな違いは学習プロセスのアーキテクチャで、Flowerでは各デバイスが独立して学習を行うのに対し、Spark MLlibはクラスタ内の全てのノードが連携して一貫したモデルを構築します。
まとめ
FL Frameworkは分散型環境での機械学習に最適なフレームワークであり、プライバシーやセキュリティの観点からも大きな価値を持っています。その特徴と優位性について理解を深めるとともに、実践的な活用方法を探求していきましょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







