
Federated Sharding for Data Parallelism (FSDP)は、効率的な大規模モデル学習に焦点を当てた技術で、PyTorch 1.10から導入されました。この記事では、FSDPの背景、機能、および最新の応用事例について詳しく説明します。
この記事の目次
- FSDPとは何か?
- FSDPの歴史と進化
- FSDPの内部仕組み
- FSDPとDataParallelism比較
- まとめ
FSDPとは何か?
FSDPは、大規模な深層学習モデルのパラレルトレーニングとスケーラビリティを可能にするメカニズムです。これにより、非常に大量のパラメータを持つモデルを効果的に訓練することができます。
モデルがメモリ上に完全に収まらない場合でも、FSDPはデータ並列学習においてシャーディング機能を提供します。
FSDPの歴史と進化

FSDPは、PyTorch 1.10でデビューし、当初から大規模なデータセットやモデルを扱う際のパフォーマンス問題に取り組んでいました。
各バージョンでは新たな機能が追加され、特に最新版では複雑さが増すモデルでも安定性と効率性を維持するための改良が行われました。
FSDPの内部仕組み
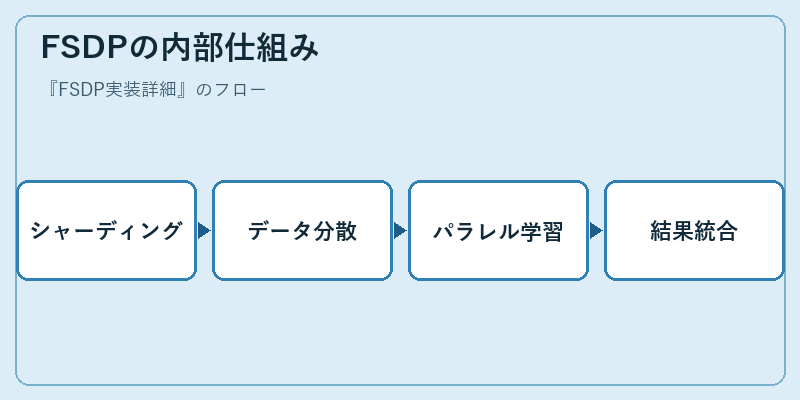
シャーディングとは、モデルとデータを複数のプロセスに分割して処理することで、各プロセッサの負荷を最適化します。このステップは、通信コストの削減と並行学習の効率向上へつながります。
最後には、各シャードで生成された情報を統合し、全体的なモデルパフォーマンスを評価・改善するためのデータが得られます。
FSDPとDataParallelism比較

DataParallelは簡単で効果的な分散処理方法ですが、モデルサイズが大きくなるとメモリ使用量やスケーラビリティに課題が出始める。
一方、FSDPはデータシャーディング機能を強化し、通信コストの削減や並列学習の効率化へ貢献しています。
まとめ
FSDPは大規模モデルに対する高効率なトレーニングを可能にする重要な技術であり、今後もその可能性が広がっていくことが期待されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







