
データベース管理システムにおいて、故障時の迅速な切り替えが不可欠です。1980年代から発展してきたフェイルオーバーは、停止時間を最小限に抑えつつサービスの連続性を保つための重要な機能となっています。この記事では、フェイルオーバーの仕組みとその進化について深く掘り下げます。
この記事の目次
- フェイルオーバーの基本原理
- 手順とプロセス
- フェイルオーバーとデータ同期
- フェイルオーバーと他の可用性技術の比較
- まとめ
フェイルオーバーの基本原理

データベース管理は、サービスの一貫性と安定性を維持する上で鍵となる。フェイルオーバーは、これが機能しない場合のバックアップとして存在し、通常通り動作を保証します。
たとえば、主要データベースがダウンした際、フェイルオーバーは自動的に待機モードのサーバに切り替えを行い、ユーザーには影響を与えずにサービスを継続する。
手順とプロセス
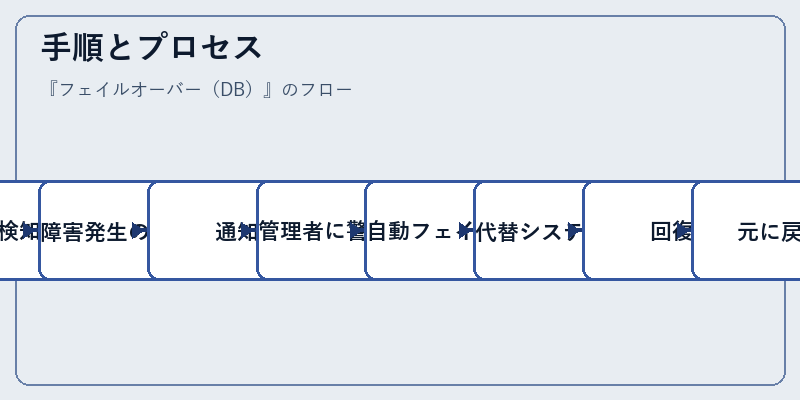
フェイルオーバーは、障害が発生した時点で即座に対応することが求められます。これは通常のデータベース管理プロセスとは別に機能します.
具体的には、監視ツールが故障を検出するとすぐに、代替システムへの切り替えやユーザへの通知といった手順が自動的に行われます。
フェイルオーバーとデータ同期

フェイルオーバーは、データベースとそのレプリカの同期を維持することで効果を発揮します。これにより、主となるシステムが利用不能になった場合でも直ちに切り替えが可能になります。
例えば、オンラインストアにおける取引情報はミラーサイトにリアルタイムでレプリケートされ、一時的な障害が発生した際にも引き続きサービスを提供します。
フェイルオーバーと他の可用性技術の比較

フェイルオーバーは、他の可用性技術と比較して特徴的な点があります。最も主要なのは、障害発生時に自動的に切り替えができる点です。これにより、人的介入を最小限に抑えることができます。
冗長化システムと異なり、フェイルオーバーは通常は待機モードで動作しますので、常に複数のサーバが稼働するわけではないため、コストやエネルギー使用量を抑えられるという利点があります。
まとめ
データベースのフェイルオーバーは、障害時にサービスの可用性と継続性を確保する鍵となる技術です。これにより、企業や組織がサービスの一貫性を維持し、ビジネスに支障を与えないことが可能となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







