
G-Evalは、AI言語モデルが生成したテキストの倫理性を評価するためのフレームワークです。2021年に提出された論文によって注目を集めました。
この記事の目次
- G-Evalとは何か
- G-Evalの発展
- G-Evalの内部仕組み
- G-Evalとその他の指標の比較
- まとめ
G-Evalとは何か
G-Evalは、AIが生成したテキストに潜在的な不適切な内容がないかを検出する指標として開発されました。これには偏見や誤情報の拡散を防ぐという重要な役割があります。
具体的には、モデルが学習に使用されたデータセットから倫理的に問題となる文脈を抽出し、それらと生成テキストを比較することで評価を行います。
G-Evalの発展

G-Evalの開発はまだ初期段階ですが、既に多くの改善点が提案されています。例えば、評価の精度を高めるために新たなデータセットやアルゴリズムの導入が検討されています。
さらに、モデルの透明性とユーザビリティの向上も重要な課題となっています。ユーザーが容易に利用できる形でG-Evalを利用することで、より広範な活用が期待されます。
G-Evalの内部仕組み
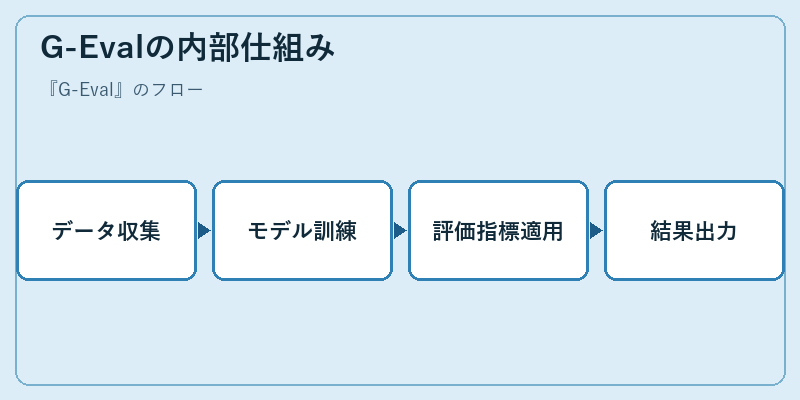
G-Evalは、まず大規模なテキストデータセットから倫理的に問題となる表現やフレーズを抽出します。これらが「危険信号」となります。
次に、AI言語モデルにこの信号に基づく訓練を行います。最終的な評価では、生成された文章がこれらの信号と一致するかどうかを確認し、スコアリングします。
G-Evalとその他の指標の比較
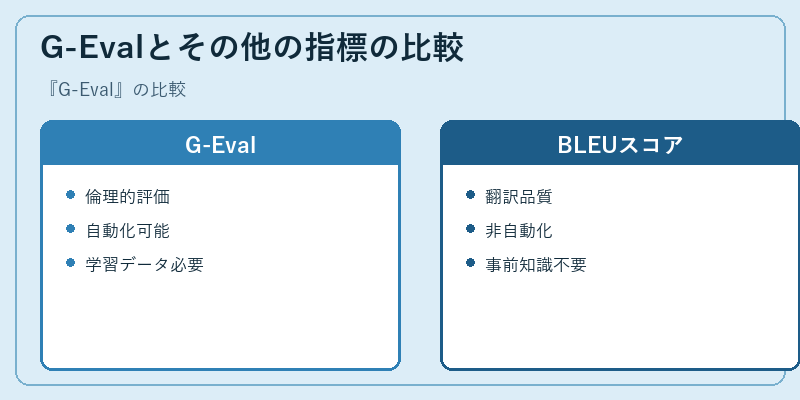
G-Evalは、他の評価指標と比較して、言語モデルの生成結果に対して倫理的観点から評価することを主眼に置いています。一方、BLEUスコアは翻訳の品質を計る指標で、両者は目的が異なります。
また、G-Evalでは学習データが必要であり、それが評価結果に影響を与えますが、BLEUスコアは事前知識や大量データなしでも利用可能です。
まとめ
G-Evalの開発は、AI言語モデルにおける倫理的な課題に対する解決策の一端を担っていますが、今後の進化と実装に注目が必要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







