
ウェブ開発において不可欠なGETは、1990年代初頭にトム・マーノーやティム・バーネルズ=リーらがW3Cで作成したRFCで定義された。その後数十年、Webの進化と共に機能を拡張しながら今日まで使われ続けている。ここではGETの基本から最新動向まで深堀りしてみよう。
この記事の目次
- GETの基本仕様
- GETの発展と変遷
- GETとPOSTの対比
- GETの安全性とリスク
- まとめ
GETの基本仕様
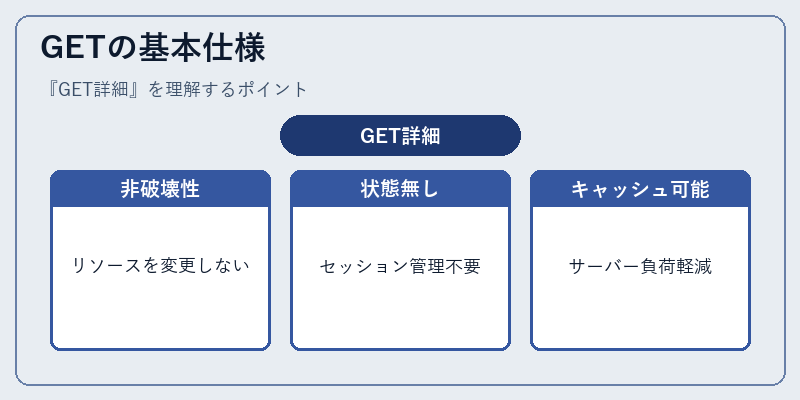
GETはウェブ上でのリソース取得のためのHTTPメソッドで、クライアントが指定したURLを参照してサーバーから情報を引き出す。非破壊性という特徴により、同じ条件下では常に同一結果が返ってくる。このため、ブラウザの戻るボタンでの再現やキャッシュ利用などが可能になる。
実際のWebサイトでは、商品詳細ページの表示や検索エンジンからの結果取得などに広く採用されている。しかし、GETはパラメータがURLに直接付与されることから、情報漏洩のリスクもあるため注意が必要だ。
GETの発展と変遷

1990年代、W3CではHTTP/1.0を含む様々な仕様書が公開された。その中でGETメソッドは初めから重要な位置付けだった。その後、RESTful APIの普及と共にGETはWebサービス間でのデータ交換でも大いに活躍した。
さらに近年では単一ページアプリケーション(SPA)といった新たなウェブ開発手法が登場し、GETリクエストの利用範囲も更に広がった。この流れの中で、セキュアなGETリクエストを実現するための技術や標準化活動も活発になっている。
GETとPOSTの対比

ウェブ開発でGETと並ぶ重要なHTTPメソッドは、リソース作成や更新に使われるPOSTだ。両者の大きな違いは破壊性があるかないかである。この点、POSTはデータの追加・変更といった破壊的操作をサポートする反面、GETは非破壊性という特性を持つ。
また、POSTでは任意の長さのデータを送信できるが、GETはURLの長さに制約がある。さらにPOSTはセッション管理や認証情報が必要となるケースが多い一方で、GETは何も持ち運ばずにリソースへアクセスできる点も特徴的だ。
GETの安全性とリスク

GETリクエストを通じて送られるパラメータは、アクセスログやURL自体に記録されるため情報漏洩を引き起こす可能性がある。そのため、安全性を確保するにはこれらの対策が欠かせない。
具体的には、まず送信データの形式をURLエンコードして文字エンコーディング誤解を防ぐことが重要だ。さらにサーバー側ではキャッシュ制御ヘッダーを適切に設定することで不必要なアクセスも抑制できる。また、セッションIDや認証情報を含むリクエストパラメータはPOSTで送信するなど、リスク管理にも気を配るべきだろう。
まとめ
GETの使い方と安全性について学び、適切な状況で利用し続けていこう。今後もHTTPメソッドとしての役割を果たしつつ進化が続くことだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







