
2013年に登場したGoogle Dataflowは、分散データ処理を容易にするクラウドネイティブなフレームワークです。Apache Beamの前身となりました。この記事ではその概要と特徴、さらには利用事例について掘り下げます。
目次
この記事の目次
- Dataflowの定義
- Dataflowの進化とApache Beam
- Dataflowの内部構造
- Dataflowの用途と比較
- まとめ
Dataflowの定義
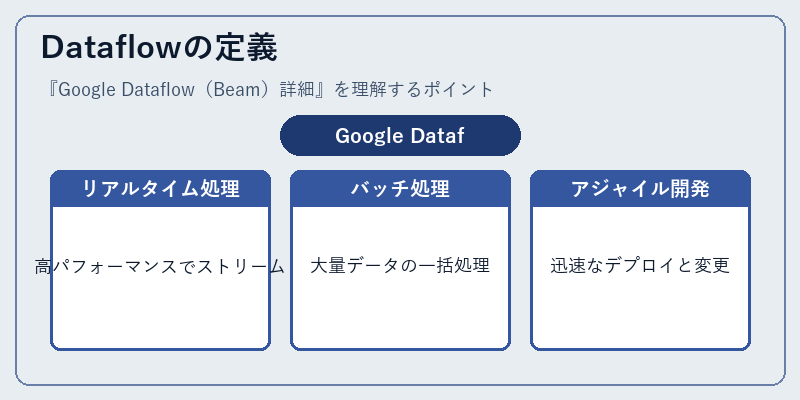
Google Dataflowは、リアルタイムとバッチの両方に対応した柔軟性の高いフレームワークである。
これにより開発者は様々なユースケースを迅速にサポートすることが可能になり、大規模データ処理における効率が向上します。
Dataflowの進化とApache Beam
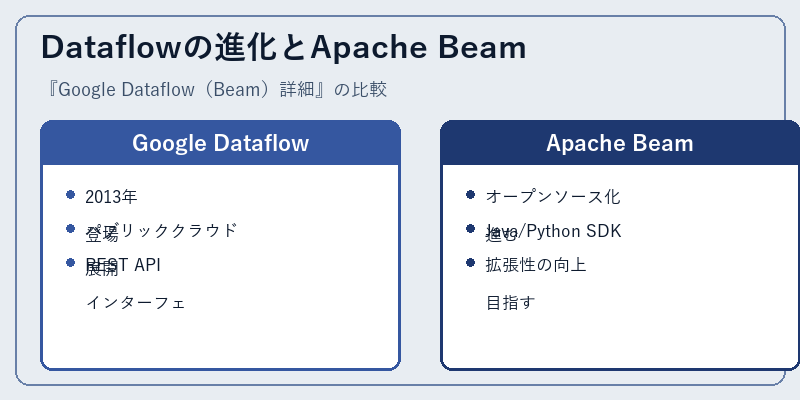
2013年に登場したGoogle Dataflowは、2016年にはオープンソースプロジェクトApache Beamとして発展を続けた。
これにより開発者は自身のニーズに合わせてフレームワークをカスタマイズすることが可能となりました。
Dataflowの内部構造
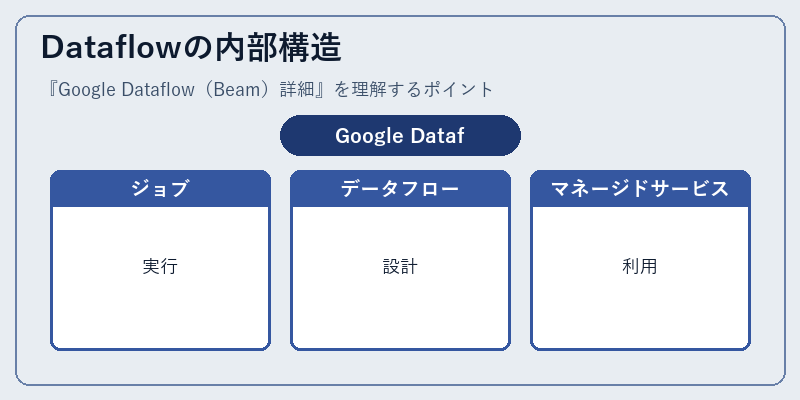
Google Dataflowは、クラウド上で分散処理を効率的に行うためにジョブを適切に分割し実行します。
また、その詳細な内部構造や管理方法について理解することでより柔軟性が向上するでしょう。
Dataflowの用途と比較

Google Dataflowは、他の分散処理フレームワークと比較して様々な点で優れた性能を発揮します。
例えば、Apache FlinkやSparkといったプラットフォームと比べてもその柔軟性と効率的なパフォーマンスは際立つでしょう。
まとめ
Google Dataflow(Beam)を利用することで、リアルタイムストリーミングから大量データの分析まで幅広いユースケースに対応することが可能となる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







