
ハッシュエンコーディングとは、文字列データを固定長のハッシュ値に変換する手法です。この技術は1970年代から存在し、近年の機械学習やセキュリティ分野で再び脚光を浴びています。ここではその概念、用途、そして他のエンコーディング方法との比較を解説します。
この記事の目次
- ハッシュエンコードの仕組み
- ハッシュエンコードと機械学習
- ハッシュエンコードと他の変換手法
- ハッシュエンコードの歴史と発展
- まとめ
ハッシュエンコードの仕組み
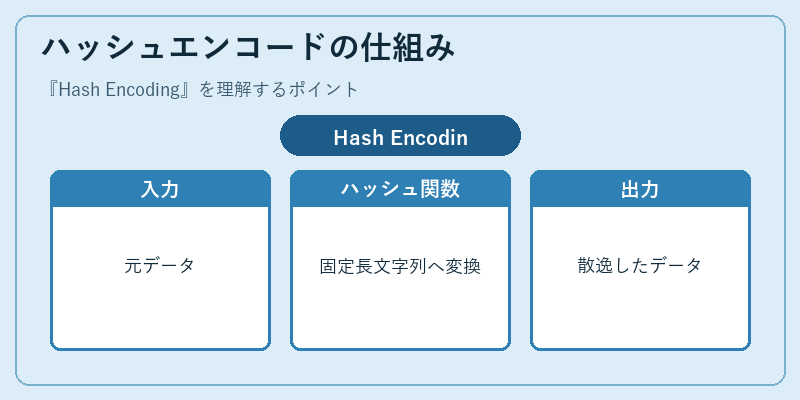
ハッシュエンコードは、文字列から一定長の値を生成します。これは乱数のように見えるため、データの識別性を損ないますが、一方向性を持つハッシュ関数は復元不可能です。
例えば、パスワードやID情報といった機密情報を保管する際、元データが盗まれるリスクを低減できます。また、自然言語処理でも有用で、文章の特徴を表現します。
ハッシュエンコードと機械学習

ハッシュエンコーディングは、文書の内容を保ちつつプライバシーを守るための有力な手段です。機械学習モデルに直接文字列データを投げ込む代わりに、それらを適切に散逸したハッシュ値として提供します。
例えば、大量のテキストデータから感情分析を行う場合、ユーザー情報が保護された形で処理されます。これはデータサイエンスにおけるセキュリティ上の重大な進歩と言えます。
ハッシュエンコードと他の変換手法
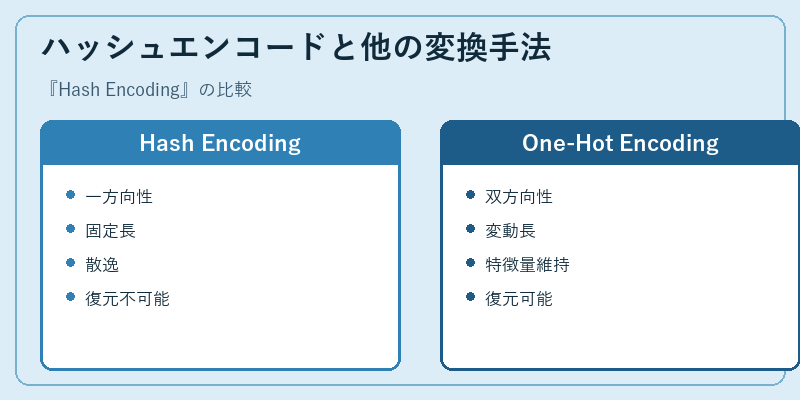
ハッシュエンコードは、他のテキストエンコーディング方法と比較して独自の特性を持っています。一方向性により、安全にデータを扱うことが可能です。
一方で、One-Hotエンコーディングなどの手法は、固定長ではありながら元データから復元可能であるため、セキュリティ面での対応が求められます。
ハッシュエンコードの歴史と発展

ハッシュエンコードは古くから存在し、情報の散逸と非逆変換性を求める中で進化してきました。MD5やSHAといったアルゴリズムはセキュリティ分野での必須アイテムとなりました。
現在では大量データに対する効率的なハッシュ生成も求められており、実用性がさらに向上しています。これらの技術の継続的な改良は、今後もデータサイエンス界隈を支える重要な要素となるでしょう。
まとめ
ハッシュエンコードは、機密情報保護と大規模データ分析に不可欠な技術であるとともに、その他のテキスト変換手法との比較から新たな視点が開けます。今後もセキュリティ強化やモデル性能向上に寄与することが期待されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







