
局所感応ハッシュ(LSH)は、大規模な高次元データ集合において効率的に近似した類似度を持つ要素を探索する技術。1990年代後半から研究が活発化し、近年では画像認識や推薦システムなどに幅広く応用されている。LSHの背後に潜む数学的な洞察とその応用範囲について深堀りします。
この記事の目次
- LSHの定義と目標
- LSHの数学的背景
- LSHの実装と応用
- LSHと他の近傍探索アルゴリズムの比較
- まとめ
LSHの定義と目標
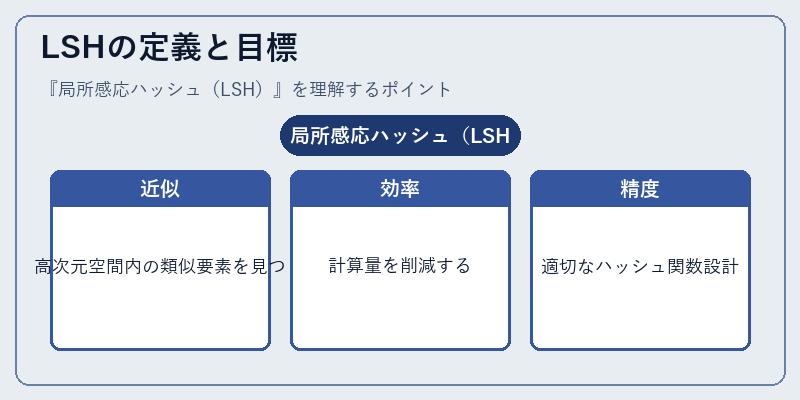
LSHは、データセットから類似度が高いアイテムを見つけるためのアプローチで、その中心となるアイデアは類似した点が同じバケットに格納されるようにする。
具体的には、画像の特徴量ベクトルを対象として、これらの特徴値間の類似度を保証しつつ効率よく探索を行うためのハッシュ関数を選択することが重要となる。
LSHの数学的背景

LSHは、高次元空間における近傍探索問題を解決するための数学的手法に依拠している。
たとえば、画像や文書の集合から類似するアイテムを見つける場合、ランダムな超平面上でデータ点を投影し、それによって得られる低次元特徴空間での近似距離を利用します。
LSHの実装と応用
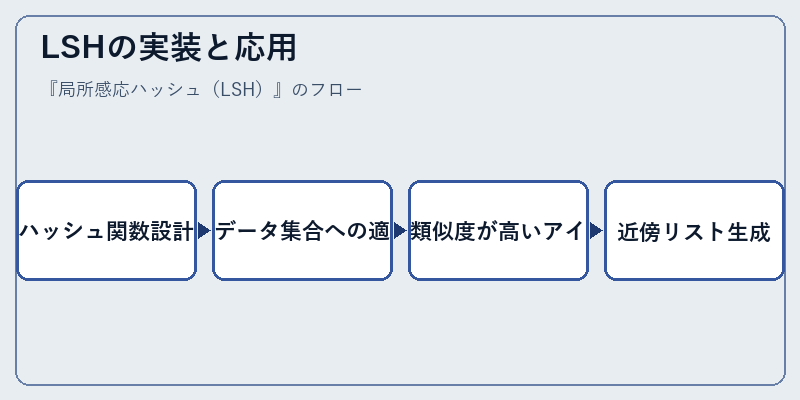
実際にLSHを活用するには、まず該当する問題状況に適したハッシュ関数を選定し、それを利用してデータセットから探したい要素の集まりを得る。
この手法は画像認識や音楽類似性検出といった多様な場面で利用され、従来の全探索とは比較にならないほど高速で効率的な検索が可能となります。
LSHと他の近傍探索アルゴリズムの比較
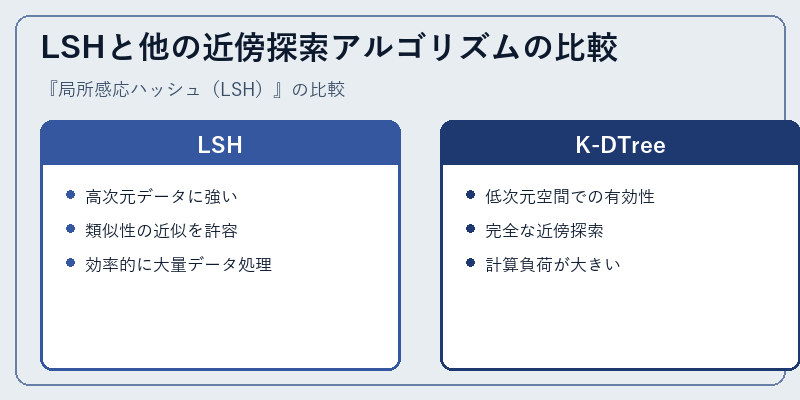
LSHは、他の近似検索アルゴリズムと比較して、特に高次元データに対して優れたパフォーマンスを発揮します。
例えば、K-DTreeは完全な近傍探索を可能にしますが、データの次元数が増えれば増えるほど計算負荷が大きくなり、LSHのようなアプローチが有利になるケースが多い。
まとめ
局所感応ハッシュ(LSH)は、大規模な高次元空間での効率的な類似性検索を可能にする技術として、さまざまな領域でその有用性が証明されています。今後も新たな適用分野や改良が期待される。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







