
Apache Hadoop Distributed File System (HDFS) は、大規模データセットの処理とストレージを可能にする分散型ファイルシステムとして知られています。開発者のDoug CuttingとMike Cafarellaによって2003年に始まったこのプロジェクトは、GoogleのGFS(GoogleFileSystem)からインスピレーションを得て、その後のビッグデータ時代において重要な役割を果たしています。
この記事の目次
- HDFSの基本概念
- HDFSの内部構造
- HDFSの信頼性設計
- HDFSとS3の比較
- まとめ
HDFSの基本概念
HDFSは、非常に大きなデータセットを管理するための特別なアプローチを持っています。このファイルシステムでは、データが多数のノードに分散され、各ノードは他のノードと連携して一貫した名前空間を形成します。
具体的には、ユーザーがアクセスしたいファイルやディレクトリについてHDFSが管理する名前スペースは、複数の物理的なデバイス上に存在し、それらが互いに協調動作することで一元化されたファイルシステムとして機能します。
HDFSの内部構造
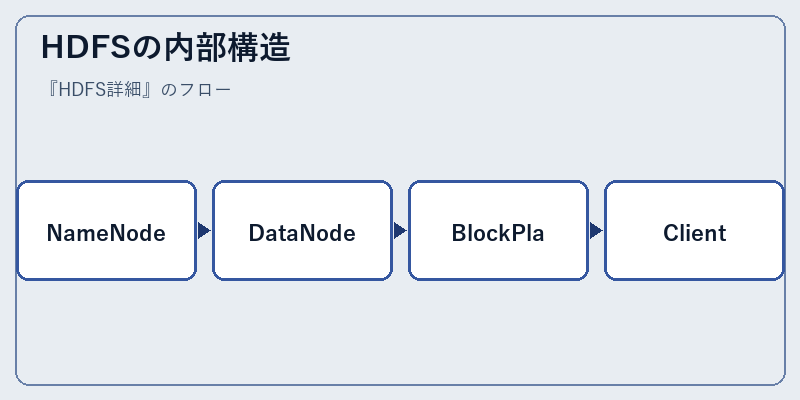
HDFSは、データを管理するための2つの主要な役割を持ったコンポーネントで構成されています。まず、名前空間とファイルアクセス制御を行う”NameNode”、次に実際のデータを保存し分散処理を行う”DataNodes”がそれにあたります。
これらは密接に関連しており、「Client」からのリクエストにより各コンポーネント間で情報をやり取りします。たとえば、ユーザーがファイルを読み書きするためには、まずNameNodeへアクセスし、その後データが格納されているDataNodesに直接アクセスする流れになります。
HDFSの信頼性設計

HDFSは高可用性と高い信頼性を確保するため、様々な機能が組み込まれています。主なものはデータの複製や障害時の自動復旧などです。
これらの仕組みにより、単一のノードがダウンしても他のノードから同じデータにアクセス可能であり、大規模なシステムでも信頼性を維持することが可能です。
HDFSとS3の比較

HDFSとAmazon S3は、それぞれ異なるアプローチでファイルシステムの問題を解決しています。HDFSは自社のインフラストラクチャ上で動作し、分散データ処理や大規模データセットへの対応に優れています。
S3はその一方でクラウドプラットフォーム上での即時利用と高いセキュリティを強みとしており、特にモビリティやスケーラビリティが必要な場合に適しています。
まとめ
HDFSの高度な分散アーキテクチャは、ビッグデータ時代における大規模データ管理において決定的な役割を果たしてきました。その詳細な仕組みと特性を理解することは、今後の技術進展や新たな課題解決に向けた重要なステップとなります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







