
HiveQLは、Apache Hiveプロジェクトが提供するデータウェアハウス系ソフトウェアのSQL風クエリ言語です。大規模な分散ファイルシステム上のデータを効率的に扱うために開発され、2008年にFacebookで始まりました。
この記事の目次
- HiveQLとは
- HiveQLの歴史
- HiveQLの仕組み
- 他のSQL言語との比較
- まとめ
HiveQLとは
HiveQLは、Apache Hiveプロジェクトの中心的な役割を果たすSQL風クエリ言語で、大規模な分散ファイルシステム上に保存された大量のデータに対して効率的にクエリを実行します。ユーザーは、通常のSQLと似た構文を使ってHDFS上のデータベーステーブルを作成したり削除したりできます。
しかし、この言語が提供する機能には制限があり、複雑なJOIN操作やリアルタイム処理はサポートされません。また、パフォーマンスの最適化のためにカスタムUDF(ユーザー定義関数)を使用することが推奨されます。
HiveQLの歴史
HiveQLは2008年にFacebookで開発が開始されました。当時の問題として、大量のユーザー行動データを効率的に取り扱う方法が必要でした。そのため、Apache Hadoop上で動作する分散型データベースシステムApache Hiveが作られました。
その後、HiveQLはさまざまな企業や組織に採用され、ビッグデータ分析における重要な役割を果たしています。現在も活発な開発が続けられており、より高度な機能やパフォーマンスの向上を目指しています。
HiveQLの仕組み

HiveQLは、データウェアハウスにおける大量の非構造化データを処理するためのフレームワークです。まずテーブルを作成し、その後クエリで必要な情報を取得します。
また、複雑なビジネスロジックを実装するためにユーザー定義関数(UDF)を使用することも可能です。このようにしてHiveQLは高度なデータ分析に対応しています。
他のSQL言語との比較
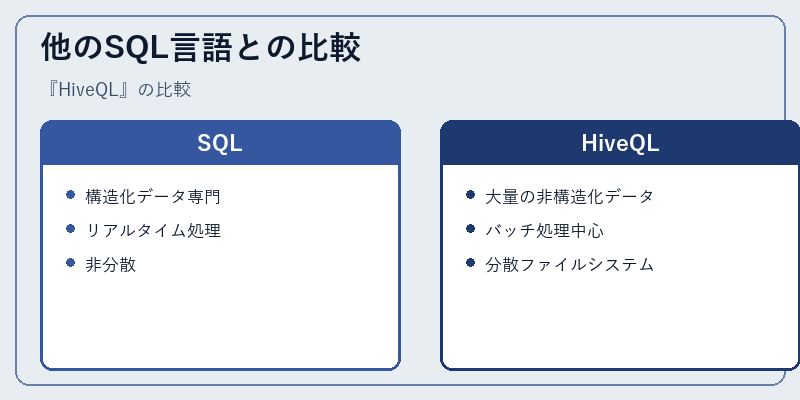
HiveQLは他のSQL言語と比較して、主に大量の非構造化データを扱うためのものであり、リアルタイム処理よりもバッチ処理を中心に設計されています。
また、標準的なSQLでは非分散なデータベースシステムで動作するが、HiveQLはApache Hadoop上で動作し、大規模な分散ファイルシステム上のデータを取り扱える点も特徴的である。
まとめ
HiveQLはビッグデータ分析において重要な役割を果たしており、今後も進化が予想される。しかし、リアルタイム処理や複雑なJOIN操作には不向きな点に注意が必要だ。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







