
HQQ(Hypercube Querying)は、高次元データ分析において重要な手法の一つであり、三次元以上の複雑な空間を理解するための技術です。その発展と変遷について解説し、現代における応用例も紹介します。
この記事の目次
- HQQとは:定義と基本概念
- 歴史的背景:開発と進化
- 内部仕組み:機能と機構
- 他のアプローチとの比較:HQQの位置づけ
- まとめ
HQQとは:定義と基本概念
HQQは、高次元空間におけるデータ検索と分析を行うための技術であり、その中心となる概念が存在します。具体的には、データ集合に対して効率的なクエリ処理を行い、結果を可視化することで人間にとって理解しやすい形に変換します。
しかし、高次元空間における問題は単純ではなく、データの数や種類が増えると計算量も急激に増加するため、それを克服するためにさまざまな最適化手法が開発されています。HQQはこうした課題に対処する一つの重要なアプローチとなっています。
歴史的背景:開発と進化
HQQは1990年代からデータベースと機械学習の研究者たちにより開発が進められ、2000年頃には実用的な形で使用されるようになりました。その後、高速化や精度向上のための改良が継続的に行われ、現在では複雑な分析作業において欠かせない存在となっています。
その進歩の一端を担った代表的な研究者たちがいることも忘れてはなりません。これらの開発過程における多くの課題解決により、現代のデータサイエンスに貢献しています。
内部仕組み:機能と機構

HQQは、その内部仕組みを通じてデータ分析の各フェーズを支えています。具体的には、高次元空間におけるデータ点間の距離計算を効率化し、クエリ処理時間の短縮に寄与します。
これによりユーザーは迅速な結果を得ることができますが、さらなる技術的側面としては、データ構造の抽象的な表現が重要であり、これは専門家だけでなく非専門家でも理解できる形式へと変換する役割を果たします。
他のアプローチとの比較:HQQの位置づけ
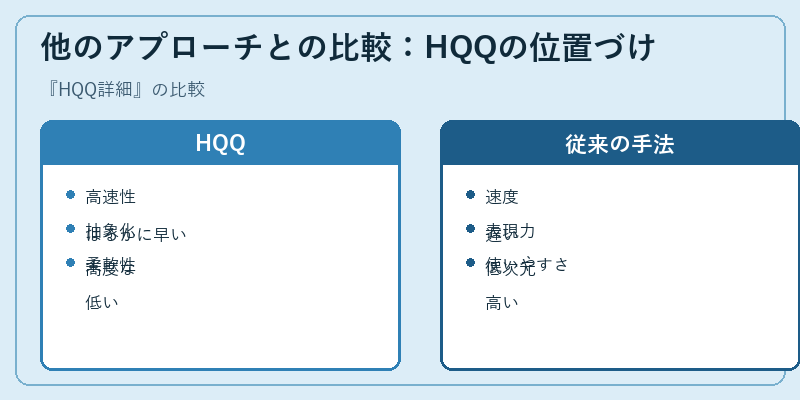
HQQと他のデータ分析アプローチを比較すると、それぞれが持つ長所と短所が明確になります。HQQは特に高速性において優れており、大量の高次元データに対して迅速な解析結果を提供します。
一方で従来の手法は操作性に優れていますが、これに対しHQQは高度な抽象化能力を持つことで、より深い洞察を得ることができます。このように、使用目的や状況により選択すべきアプローチは変わってくるでしょう。
まとめ
本記事ではHQQの基本的な概念から歴史的背景、内部仕組みまでを概観しました。これらを通じて現代におけるデータサイエンスにおける重要性が理解できるはずです。今後も引き続き技術進化を見守りましょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







