HTMLパーサライブラリhtml.parser: HTML文書の解析に欠かせないPython標準モジュール


1990年代後半から開発が進められたPythonのhtml.parserは、HTML文書を構造化データとして読み解くのに重要な役割を果たしている。この記事では、html.parserの歴史と特徴に焦点を当てつつ、その利用法や内部メカニズムを探る。
目次
この記事の目次
- HTML文書の構造解析
- HTMLパーサライブラリの進化
- html.parserとその他のパーサライブラリとの比較
- パーサの詳細設定とカスタマイズ
- まとめ
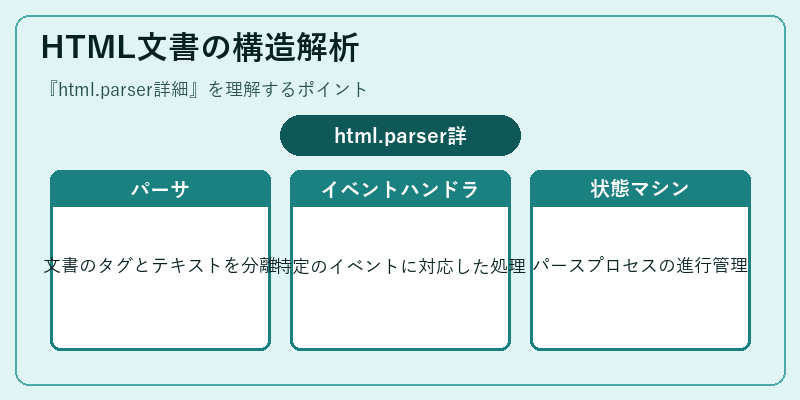
HTML文書の構造解析
html.parserはHTML文書を解析するためのツールであり、その基本的な機能はタグとテキストの区別や構造の再現にあり。具体的には、
や<body>といったマークアップ要素を抽出し、それをPythonオブジェクトとして扱うことができる。</p>
<p>このメカニズムによって、ユーザーはWebページから必要なデータだけを取り出すことが可能になり、それらを利用した様々なアプリケーション開発が容易になる。</p>
<h2>HTMLパーサライブラリの進化</h2>
<figure class="wp-block-image"><img decoding="async" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s2.png" alt="HTMLパーサライブラリの進化" class="lazyload" ><noscript><img decoding="async" src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s2.png" alt="HTMLパーサライブラリの進化" ></noscript></figure>
<p>html.parserはPython 2.2から導入され、その後も継続的に改善されてきた。開発初期の頃は基本的な機能のみだったが、時間と共に複雑さや柔軟性を増し、より広範な用途に利用可能になった。「読み込み」段階では、対象となるHTMLドキュメントを一括で取り込む。次に「解析」というステップで、その文書の構造的要素を抽出する。最後に、「イベントハンドリング」プロセスを通じて特定のタグや属性に対してユーザー定義のアクションを設定できるようになる。</p>
<h2>html.parserとその他のパーサライブラリとの比較</h2>
<figure class="wp-block-image"><img decoding="async" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s3.png" alt="html.parserとその他のパーサライブラリとの比較" class="lazyload" ><noscript><img decoding="async" src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s3.png" alt="html.parserとその他のパーサライブラリとの比較" ></noscript></figure>
<p>html.parserはPythonの標準ライブラリとして提供されるため、インストール不要で利用可能である一方、その機能範囲はそれほど広くない。これに対し、第三_party_ライブラリのBeautifulSoup4はHTML5規格にも対応しており、高度なデータ抽出能力を有する。html.parserとBeautyfulSoup4は、それぞれ異なる特長を持つが、どちらもWebスクレイピングやデータ解析などにおいて重要な役割を果たすものと言えるだろう。</p>
<h2>パーサの詳細設定とカスタマイズ</h2>
<figure class="wp-block-image"><img decoding="async" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" data-src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s4.png" alt="パーサの詳細設定とカスタマイズ" class="lazyload" ><noscript><img decoding="async" src="https://serverside.jp/wp-content/uploads/2026/06/html-parser-s4.png" alt="パーサの詳細設定とカスタマイズ" ></noscript></figure>
<p>html.parserは詳細なカスタマイズが可能で、ユーザーは自身に必要な機能のみを追加したり既存機能を置き換えたりできる。例えば、特定のタグだけを取り出すフィルターを作成することができ、更にはHTMLエンティティ(”<",">“,”&”など)をプレーンテキストとして取り扱うことも可能だ。また、このパーサはデフォルトではXML形式の文書も処理できるよう設計されており、その柔軟性を活かして多様な用途に応用されることがある。</p>
<h2>まとめ</h2>
<p>html.parserはPythonでHTMLを解析する際に使用される重要なライブラリである。開発者にとっては既存の文書を効率よく処理し、必要な情報だけを抽出するために有用であり、今後も幅広く活用され続けるであろう。</p>
<p class="notice"><small>※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。</small></p>
<div class="post-views content-post post-64427 entry-meta load-static">
<span class="post-views-icon dashicons dashicons-chart-bar"></span> <span class="post-views-label">Post Views:</span> <span class="post-views-count">37</span>
</div> </div>
<div class="p-articleFoot">
<div class="p-articleMetas -bottom">
<div class="p-articleMetas__termList c-categoryList">
<a class="c-categoryList__link hov-flash-up" href="https://serverside.jp/category/uncategorized/" data-cat-id="1">
未分類 </a>
</div>
<div class="p-articleMetas__termList c-tagList">
<a class="c-tagList__link hov-flash-up" href="https://serverside.jp/tag/h/" data-tag-id="30">
H </a>
<a class="c-tagList__link hov-flash-up" href="https://serverside.jp/tag/it%e7%94%a8%e8%aa%9e%e9%9b%86/" data-tag-id="49">
IT用語集 </a>
<a class="c-tagList__link hov-flash-up" href="https://serverside.jp/tag/%e5%9f%ba%e7%a4%8e%e7%9f%a5%e8%ad%98/" data-tag-id="50">
基礎知識 </a>
</div>
</div>
</div>
<div class="c-shareBtns -bottom -style-block">
<div class="c-shareBtns__message">
<span class="__text">
よかったらシェアしてね! </span>
</div>
<ul class="c-shareBtns__list">
<li class="c-shareBtns__item -facebook">
<a class="c-shareBtns__btn hov-flash-up" href="https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F" title="Facebookでシェア" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=800,width=600');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-facebook" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -twitter-x">
<a class="c-shareBtns__btn hov-flash-up" href="https://twitter.com/intent/tweet?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&text=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="X(Twitter)でシェア" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=400,width=600');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-twitter-x" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -hatebu">
<a class="c-shareBtns__btn hov-flash-up" href="//b.hatena.ne.jp/add?mode=confirm&url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F" title="はてなブックマークに登録" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=600,width=1000');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-hatebu" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -pocket">
<a class="c-shareBtns__btn hov-flash-up" href="https://getpocket.com/edit?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&title=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="Pocketに保存" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-pocket" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -line">
<a class="c-shareBtns__btn hov-flash-up" href="https://social-plugins.line.me/lineit/share?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&text=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="LINEに送る" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-line" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -copy">
<button class="c-urlcopy c-plainBtn c-shareBtns__btn hov-flash-up" data-clipboard-text="https://serverside.jp/html-parser/" title="URLをコピーする">
<span class="c-urlcopy__content">
<svg xmlns="http://www.w3.org/2000/svg" class="swl-svg-copy c-shareBtns__icon -to-copy" width="1em" height="1em" viewBox="0 0 48 48" role="img" aria-hidden="true" focusable="false"><path d="M38,5.5h-9c0-2.8-2.2-5-5-5s-5,2.2-5,5h-9c-2.2,0-4,1.8-4,4v33c0,2.2,1.8,4,4,4h28c2.2,0,4-1.8,4-4v-33
C42,7.3,40.2,5.5,38,5.5z M24,3.5c1.1,0,2,0.9,2,2s-0.9,2-2,2s-2-0.9-2-2S22.9,3.5,24,3.5z M38,42.5H10v-33h5v3c0,0.6,0.4,1,1,1h16
c0.6,0,1-0.4,1-1v-3h5L38,42.5z"/><polygon points="24,37 32.5,28 27.5,28 27.5,20 20.5,20 20.5,28 15.5,28 "/></svg> <svg xmlns="http://www.w3.org/2000/svg" class="swl-svg-copied c-shareBtns__icon -copied" width="1em" height="1em" viewBox="0 0 48 48" role="img" aria-hidden="true" focusable="false"><path d="M38,5.5h-9c0-2.8-2.2-5-5-5s-5,2.2-5,5h-9c-2.2,0-4,1.8-4,4v33c0,2.2,1.8,4,4,4h28c2.2,0,4-1.8,4-4v-33
C42,7.3,40.2,5.5,38,5.5z M24,3.5c1.1,0,2,0.9,2,2s-0.9,2-2,2s-2-0.9-2-2S22.9,3.5,24,3.5z M38,42.5H10v-33h5v3c0,0.6,0.4,1,1,1h16
c0.6,0,1-0.4,1-1v-3h5V42.5z"/><polygon points="31.9,20.2 22.1,30.1 17.1,25.1 14.2,28 22.1,35.8 34.8,23.1 "/></svg> </span>
</button>
<div class="c-copyedPoppup">URLをコピーしました!</div>
</li>
</ul>
</div>
<div class="c-shareBtns -fix -style-block">
<ul class="c-shareBtns__list">
<li class="c-shareBtns__item -facebook">
<a class="c-shareBtns__btn hov-flash-up" href="https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F" title="Facebookでシェア" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=800,width=600');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-facebook" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -twitter-x">
<a class="c-shareBtns__btn hov-flash-up" href="https://twitter.com/intent/tweet?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&text=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="X(Twitter)でシェア" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=400,width=600');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-twitter-x" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -hatebu">
<a class="c-shareBtns__btn hov-flash-up" href="//b.hatena.ne.jp/add?mode=confirm&url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F" title="はてなブックマークに登録" onclick="javascript:window.open(this.href, '_blank', 'menubar=no,toolbar=no,resizable=yes,scrollbars=yes,height=600,width=1000');return false;" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-hatebu" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -pocket">
<a class="c-shareBtns__btn hov-flash-up" href="https://getpocket.com/edit?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&title=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="Pocketに保存" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-pocket" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -line">
<a class="c-shareBtns__btn hov-flash-up" href="https://social-plugins.line.me/lineit/share?url=https%3A%2F%2Fserverside.jp%2Fhtml-parser%2F&text=HTML%E3%83%91%E3%83%BC%E3%82%B5%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AAhtml.parser%3A+HTML%E6%96%87%E6%9B%B8%E3%81%AE%E8%A7%A3%E6%9E%90%E3%81%AB%E6%AC%A0%E3%81%8B%E3%81%9B%E3%81%AA%E3%81%84Python%E6%A8%99%E6%BA%96%E3%83%A2%E3%82%B8%E3%83%A5%E3%83%BC%E3%83%AB" title="LINEに送る" target="_blank" role="button" tabindex="0">
<i class="snsicon c-shareBtns__icon icon-line" aria-hidden="true"></i>
</a>
</li>
<li class="c-shareBtns__item -copy">
<button class="c-urlcopy c-plainBtn c-shareBtns__btn hov-flash-up" data-clipboard-text="https://serverside.jp/html-parser/" title="URLをコピーする">
<span class="c-urlcopy__content">
<svg xmlns="http://www.w3.org/2000/svg" class="swl-svg-copy c-shareBtns__icon -to-copy" width="1em" height="1em" viewBox="0 0 48 48" role="img" aria-hidden="true" focusable="false"><path d="M38,5.5h-9c0-2.8-2.2-5-5-5s-5,2.2-5,5h-9c-2.2,0-4,1.8-4,4v33c0,2.2,1.8,4,4,4h28c2.2,0,4-1.8,4-4v-33
C42,7.3,40.2,5.5,38,5.5z M24,3.5c1.1,0,2,0.9,2,2s-0.9,2-2,2s-2-0.9-2-2S22.9,3.5,24,3.5z M38,42.5H10v-33h5v3c0,0.6,0.4,1,1,1h16
c0.6,0,1-0.4,1-1v-3h5L38,42.5z"/><polygon points="24,37 32.5,28 27.5,28 27.5,20 20.5,20 20.5,28 15.5,28 "/></svg> <svg xmlns="http://www.w3.org/2000/svg" class="swl-svg-copied c-shareBtns__icon -copied" width="1em" height="1em" viewBox="0 0 48 48" role="img" aria-hidden="true" focusable="false"><path d="M38,5.5h-9c0-2.8-2.2-5-5-5s-5,2.2-5,5h-9c-2.2,0-4,1.8-4,4v33c0,2.2,1.8,4,4,4h28c2.2,0,4-1.8,4-4v-33
C42,7.3,40.2,5.5,38,5.5z M24,3.5c1.1,0,2,0.9,2,2s-0.9,2-2,2s-2-0.9-2-2S22.9,3.5,24,3.5z M38,42.5H10v-33h5v3c0,0.6,0.4,1,1,1h16
c0.6,0,1-0.4,1-1v-3h5V42.5z"/><polygon points="31.9,20.2 22.1,30.1 17.1,25.1 14.2,28 22.1,35.8 34.8,23.1 "/></svg> </span>
</button>
<div class="c-copyedPoppup">URLをコピーしました!</div>
</li>
</ul>
</div>
<div id="after_article" class="l-articleBottom">
<ul class="p-pnLinks -style-normal">
<li class="p-pnLinks__item -prev">
<a href="https://serverside.jp/html-mojiyu-ru/" rel="prev" class="p-pnLinks__link">
<span class="p-pnLinks__title">HTMLモジュール詳細:Pythonでのウェブコンテンツ生成</span>
</a>
</li>
<li class="p-pnLinks__item -next">
<a href="https://serverside.jp/html-shadow-dom/" rel="next" class="p-pnLinks__link">
<span class="p-pnLinks__title">HTML Shadow DOM: 独自DOM空間を実現する技術</span>
</a>
</li>
</ul>
<section class="l-articleBottom__section -author">
<h2 class="l-articleBottom__title c-secTitle">
この記事を書いた人 </h2>
<div class="p-authorBox">
<div class="p-authorBox__l">
<img alt='編集長のアバター' src='https://secure.gravatar.com/avatar/6ac01dbe43b7af7cbe537a7b0efb65d9e90813539515501bc5ccf362678c9bdf?s=100&d=mm&r=g' srcset='https://secure.gravatar.com/avatar/6ac01dbe43b7af7cbe537a7b0efb65d9e90813539515501bc5ccf362678c9bdf?s=200&d=mm&r=g 2x' class='avatar avatar-100 photo' height='100' width='100' loading='lazy' decoding='async'/> <a href="https://serverside.jp/author/ownf8363/" class="p-authorBox__name hov-col-main u-fz-m">
編集長 </a>
</div>
<div class="p-authorBox__r">
</div>
</div>
</section>
<section class="l-articleBottom__section -related">
<h2 class="l-articleBottom__title c-secTitle">関連記事</h2><ul class="p-postList p-relatedPosts -type-card"><li class="p-postList__item">
<a href="https://serverside.jp/html-mojiyu-ru/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="html モジュール詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/html-mojiyu-ru-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">HTMLモジュール詳細:Pythonでのウェブコンテンツ生成</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/href/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="href属性詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/href-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/href-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/href-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/href-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/href.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/href-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">HTMLのhref属性: リンク構築の鍵</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hr-tech/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="HR Tech詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hr-tech-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hr-tech-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hr-tech-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hr-tech-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hr-tech.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hr-tech-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">HR Tech詳細:人材採用・管理に革新を</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hr/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="hr要素詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hr-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hr-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hr-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hr-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hr.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hr-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">hr要素詳細:水平線の描画と役割</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hover-media-query/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="hover media query詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hover-media-query-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hover-media-query-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hover-media-query-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hover-media-query-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hover-media-query.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hover-media-query-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">ホバーメディアクエリ:ウェブデザインにおけるインタラクティブ性</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hover/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt=":hover詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hover-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hover-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hover-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hover-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hover.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hover-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">:hover セレクタ:ウェブページ上でマウスオーバー時のスタイル設定</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hostname/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="hostname詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hostname-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hostname-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hostname-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hostname-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hostname.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hostname-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">hostname: Linuxシステムにおけるホスト名管理</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
<li class="p-postList__item">
<a href="https://serverside.jp/hospital-information-technology/" class="p-postList__link">
<div class="p-postList__thumb c-postThumb">
<figure class="c-postThumb__figure">
<img width="300" height="158" src="data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" alt="Hospital Information Technology詳細 アイキャッチ" class="c-postThumb__img u-obf-cover lazyload" sizes="(min-width: 600px) 320px, 50vw" data-src="https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology-300x158.png" data-srcset="https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology-300x158.png 300w, https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology-1024x538.png 1024w, https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology-768x403.png 768w, https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology.png 1200w" data-aspectratio="300/158" ><noscript><img src="https://serverside.jp/wp-content/uploads/2026/06/hospital-information-technology-300x158.png" class="c-postThumb__img u-obf-cover" alt=""></noscript> </figure>
</div>
<div class="p-postList__body">
<div class="p-postList__title">Hospital Information Technology: 医療現場に情報技術を取り入れる</div>
<div class="p-postList__meta"><div class="p-postList__times c-postTimes u-thin">
<time class="c-postTimes__posted icon-posted" datetime="2026-06-04" aria-label="公開日">2026年6月4日</time></div>
</div> </div>
</a>
</li>
</ul></section>
</div>
</article>
</main>
<aside id="sidebar" class="l-sidebar">
<div id="block-2" class="c-widget widget_block widget_search"><form role="search" method="get" action="https://serverside.jp/" class="wp-block-search__button-outside wp-block-search__text-button wp-block-search" ><label class="wp-block-search__label" for="wp-block-search__input-1" >検索</label><div class="wp-block-search__inside-wrapper" ><input class="wp-block-search__input" id="wp-block-search__input-1" placeholder="" value="" type="search" name="s" required /><button aria-label="検索" class="wp-block-search__button wp-element-button" type="submit" >検索</button></div></form></div><div id="block-3" class="c-widget widget_block"><div class="wp-block-group"><div class="wp-block-group__inner-container"><h2 class="wp-block-heading">最近の投稿</h2><ul class="wp-block-latest-posts__list wp-block-latest-posts"><li><a class="wp-block-latest-posts__post-title" href="https://serverside.jp/infiniband-for-ai/">InfiniBand for AI詳細:高速なデータ転送技術</a></li>
<li><a class="wp-block-latest-posts__post-title" href="https://serverside.jp/infiniband/">InfiniBand: 高速な並列処理ネットワーク技術</a></li>
<li><a class="wp-block-latest-posts__post-title" href="https://serverside.jp/inet/">INET型詳細:SQLデータベースにおけるネットワーク通信</a></li>
<li><a class="wp-block-latest-posts__post-title" href="https://serverside.jp/inertiajs/">InertiaJS: フルスタックJavaScriptフレームワーク</a></li>
<li><a class="wp-block-latest-posts__post-title" href="https://serverside.jp/inertia-js-ssr/">Inertia.js SSR詳細:SPAとSSRのハイブリッド</a></li>
</ul></div></div></div><div id="block-4" class="c-widget widget_block"><div class="wp-block-group"><div class="wp-block-group__inner-container"><h2 class="wp-block-heading">最近のコメント</h2><div class="no-comments wp-block-latest-comments">表示できるコメントはありません。</div></div></div></div><div id="block-5" class="c-widget widget_block"><div class="wp-block-group"><div class="wp-block-group__inner-container"><h2 class="wp-block-heading">アーカイブ</h2><ul class="wp-block-archives-list c-listMenu wp-block-archives"><li><a href="https://serverside.jp/2026/06/">2026年6月<span class="post_count"></span></a></li></ul></div></div></div><div id="block-6" class="c-widget widget_block"><div class="wp-block-group"><div class="wp-block-group__inner-container"><h2 class="wp-block-heading">カテゴリー</h2><ul class="wp-block-categories-list c-listMenu wp-block-categories-taxonomy-category wp-block-categories"> <li class="cat-item cat-item-6"><a href="https://serverside.jp/category/ai%e3%83%bb%e6%a9%9f%e6%a2%b0%e5%ad%a6%e7%bf%92%e3%83%bb%e3%83%87%e3%83%bc%e3%82%bf%e3%82%b5%e3%82%a4%e3%82%a8%e3%83%b3%e3%82%b9/">AI・機械学習・データサイエンス</a>
</li>
<li class="cat-item cat-item-10"><a href="https://serverside.jp/category/os%e3%83%bb%e3%82%bd%e3%83%95%e3%83%88%e3%82%a6%e3%82%a7%e3%82%a2/">OS・ソフトウェア</a>
</li>
<li class="cat-item cat-item-12"><a href="https://serverside.jp/category/web%e3%83%bb%e3%83%95%e3%83%ad%e3%83%b3%e3%83%88%e3%82%a8%e3%83%b3%e3%83%89%e3%83%bb%e3%83%90%e3%83%83%e3%82%af%e3%82%a8%e3%83%b3%e3%83%89/">Web・フロントエンド・バックエンド</a>
</li>
<li class="cat-item cat-item-9"><a href="https://serverside.jp/category/%e3%82%ac%e3%82%b8%e3%82%a7%e3%83%83%e3%83%88%e3%83%bb%e3%83%8f%e3%83%bc%e3%83%89%e3%82%a6%e3%82%a7%e3%82%a2/">ガジェット・ハードウェア</a>
</li>
<li class="cat-item cat-item-8"><a href="https://serverside.jp/category/%e3%82%b9%e3%83%9e%e3%83%bc%e3%83%88%e3%83%95%e3%82%a9%e3%83%b3%e3%83%bb%e3%83%a2%e3%83%90%e3%82%a4%e3%83%ab/">スマートフォン・モバイル</a>
</li>
<li class="cat-item cat-item-5"><a href="https://serverside.jp/category/%e3%82%bb%e3%82%ad%e3%83%a5%e3%83%aa%e3%83%86%e3%82%a3%e3%83%bb%e8%aa%8d%e8%a8%bc/">セキュリティ・認証</a>
</li>
<li class="cat-item cat-item-11"><a href="https://serverside.jp/category/%e3%83%87%e3%83%bc%e3%82%bf%e3%83%99%e3%83%bc%e3%82%b9%e3%83%bb%e3%83%87%e3%83%bc%e3%82%bf%e7%ae%a1%e7%90%86/">データベース・データ管理</a>
</li>
<li class="cat-item cat-item-4"><a href="https://serverside.jp/category/%e3%83%8d%e3%83%83%e3%83%88%e3%83%af%e3%83%bc%e3%82%af%e3%83%bb%e3%82%a4%e3%83%b3%e3%83%95%e3%83%a9%e3%83%bb%e3%82%af%e3%83%a9%e3%82%a6%e3%83%89/">ネットワーク・インフラ・クラウド</a>
</li>
<li class="cat-item cat-item-7"><a href="https://serverside.jp/category/%e3%83%93%e3%82%b8%e3%83%8d%e3%82%b9it%e3%83%bbdx%e3%83%bbsaas/">ビジネスIT・DX・SaaS</a>
</li>
<li class="cat-item cat-item-3"><a href="https://serverside.jp/category/%e3%83%97%e3%83%ad%e3%82%b0%e3%83%a9%e3%83%9f%e3%83%b3%e3%82%b0%e3%83%bb%e9%96%8b%e7%99%ba%e8%a8%80%e8%aa%9e/">プログラミング・開発言語</a>
</li>
<li class="cat-item cat-item-1"><a href="https://serverside.jp/category/uncategorized/">未分類</a>
</li>
</ul></div></div></div></aside>
</div>
<footer id="footer" class="l-footer">
<div class="l-footer__inner">
<div class="l-footer__foot">
<div class="l-container">
<ul class="l-footer__nav"><li class="menu-item menu-item-type-post_type menu-item-object-page menu-item-home menu-item-64484"><a href="https://serverside.jp/">ホーム</a></li>
<li class="menu-item menu-item-type-post_type menu-item-object-page menu-item-64487"><a href="https://serverside.jp/site-policy/">サイトポリシー</a></li>
<li class="menu-item menu-item-type-post_type menu-item-object-page menu-item-privacy-policy menu-item-64485"><a rel="privacy-policy" href="https://serverside.jp/privacy-policy/">プライバシーポリシー</a></li>
<li class="menu-item menu-item-type-post_type menu-item-object-page menu-item-64486"><a href="https://serverside.jp/contact/">お問い合わせ</a></li>
</ul> <p class="copyright">
<span lang="en">©</span>
IT用語辞典. </p>
</div>
</div>
</div>
</footer>
<div class="p-fixBtnWrap">
<button id="pagetop" class="c-fixBtn c-plainBtn hov-bg-main" data-onclick="pageTop" aria-label="ページトップボタン" data-has-text="">
<i class="c-fixBtn__icon icon-chevron-up" role="presentation"></i>
</button>
</div>
<div id="search_modal" class="c-modal p-searchModal">
<div class="c-overlay" data-onclick="toggleSearch"></div>
<div class="p-searchModal__inner">
<form role="search" method="get" class="c-searchForm" action="https://serverside.jp/" role="search">
<input type="text" value="" name="s" class="c-searchForm__s s" placeholder="検索" aria-label="検索ワード">
<button type="submit" class="c-searchForm__submit icon-search hov-opacity u-bg-main" value="search" aria-label="検索を実行する"></button>
</form>
<button class="c-modal__close c-plainBtn" data-onclick="toggleSearch">
<i class="icon-batsu"></i> 閉じる </button>
</div>
</div>
<div id="index_modal" class="c-modal p-indexModal">
<div class="c-overlay" data-onclick="toggleIndex"></div>
<div class="p-indexModal__inner">
<div class="p-toc post_content -modal"><span class="p-toc__ttl">目次</span></div>
<button class="c-modal__close c-plainBtn" data-onclick="toggleIndex">
<i class="icon-batsu"></i> 閉じる </button>
</div>
</div>
</div><!--/ #all_wrapp-->
<div class="l-scrollObserver" aria-hidden="true"></div>
<script type="speculationrules">
{"prefetch":[{"source":"document","where":{"and":[{"href_matches":"/*"},{"not":{"href_matches":["/wp-*.php","/wp-admin/*","/wp-content/uploads/*","/wp-content/*","/wp-content/plugins/*","/wp-content/themes/swell_child/*","/wp-content/themes/swell/*","/*\\?(.+)"]}},{"not":{"selector_matches":"a[rel~=\"nofollow\"]"}},{"not":{"selector_matches":".no-prefetch, .no-prefetch a"}}]},"eagerness":"conservative"}]}
</script>
<script>
document.addEventListener('DOMContentLoaded', function() {
var setPh = function() {
document.querySelectorAll('.asl_w input.orig, .asl_w input[type=search], .asl_w input[name="s"]').forEach(function(i) {
i.placeholder = '11,127件から検索';
});
};
setPh();
setTimeout(setPh, 500);
setTimeout(setPh, 1500);
});
</script>
<!-- Site Kit によって追加された「Google でログイン」ボタン -->
<style>
.googlesitekit-sign-in-with-google__frontend-output-button{max-width:320px}
.interim-login #login>.googlesitekit-sign-in-with-google__frontend-output-button{margin-bottom:16px}
</style>
<script src="https://accounts.google.com/gsi/client"></script>
<script data-siwg-config="{"clientID":"site-kit-siwg-1c7cad78f9c719b7","defaultButtonOptions":{"theme":"outline","text":"signin_with","shape":"rectangular"},"loginURI":"https:\/\/serverside.jp\/wp-login.php?action=googlesitekit_auth","isUserLoggedIn":false,"isWPLogin":false,"isPreview":false,"isWooCommerce":false,"isExistingUserFlow":false,"connectNonce":"","followsPostRedirect":false,"redirectTo":"","redirectCookieName":"googlesitekit_auth_redirect_to","redirectCookiePath":"\/","redirectCookieTTL":0,"shouldShowOneTapPrompt":false}" src="https://serverside.jp/wp-content/plugins/google-site-kit/dist/assets/js/sign-in-with-google-15a07dd57b5f79886b45.js"></script>
<!-- Site Kit が追加した「Google でログイン」ボタンを閉じる -->
<script id="swell_script-js-extra">
var swellVars = {"siteUrl":"https://serverside.jp/","restUrl":"https://serverside.jp/wp-json/wp/v2/","ajaxUrl":"https://serverside.jp/wp-admin/admin-ajax.php","ajaxNonce":"a4283e10e9","isLoggedIn":"","useAjaxAfterPost":"","useAjaxFooter":"","usePvCount":"1","isFixHeadSP":"1","tocListTag":"ol","tocTarget":"h3","tocPrevText":"\u524d\u306e\u30da\u30fc\u30b8\u3078","tocNextText":"\u6b21\u306e\u30da\u30fc\u30b8\u3078","tocCloseText":"\u6298\u308a\u305f\u305f\u3080","tocOpenText":"\u3082\u3063\u3068\u898b\u308b","tocOmitType":"ct","tocOmitNum":"15","tocMinnum":"2","tocAdPosition":"before","offSmoothScroll":"","psNum":"5","psNumSp":"2","psSpeed":"1500","psDelay":"5000"};
//# sourceURL=swell_script-js-extra
</script>
<script id="swell_script-js" src="https://serverside.jp/wp-content/themes/swell/build/js/main.min.js?ver=2.10.0"></script>
<script id="wp-hooks-js" src="https://serverside.jp/wp-includes/js/dist/hooks.min.js?ver=7496969728ca0f95732d"></script>
<script id="wp-i18n-js" src="https://serverside.jp/wp-includes/js/dist/i18n.min.js?ver=781d11515ad3d91786ec"></script>
<script id="wp-i18n-js-after">
wp.i18n.setLocaleData( { 'text direction\u0004ltr': [ 'ltr' ] } );
//# sourceURL=wp-i18n-js-after
</script>
<script id="swv-js" src="https://serverside.jp/wp-content/plugins/contact-form-7/includes/swv/js/index.js?ver=6.1.6"></script>
<script id="contact-form-7-js-translations">
( function( domain, translations ) {
var localeData = translations.locale_data[ domain ] || translations.locale_data.messages;
localeData[""].domain = domain;
wp.i18n.setLocaleData( localeData, domain );
} )( "contact-form-7", {"translation-revision-date":"2025-11-30 08:12:23+0000","generator":"GlotPress\/4.0.3","domain":"messages","locale_data":{"messages":{"":{"domain":"messages","plural-forms":"nplurals=1; plural=0;","lang":"ja_JP"},"This contact form is placed in the wrong place.":["\u3053\u306e\u30b3\u30f3\u30bf\u30af\u30c8\u30d5\u30a9\u30fc\u30e0\u306f\u9593\u9055\u3063\u305f\u4f4d\u7f6e\u306b\u7f6e\u304b\u308c\u3066\u3044\u307e\u3059\u3002"],"Error:":["\u30a8\u30e9\u30fc:"]}},"comment":{"reference":"includes\/js\/index.js"}} );
//# sourceURL=contact-form-7-js-translations
</script>
<script id="contact-form-7-js-before">
var wpcf7 = {
"api": {
"root": "https:\/\/serverside.jp\/wp-json\/",
"namespace": "contact-form-7\/v1"
}
};
//# sourceURL=contact-form-7-js-before
</script>
<script id="contact-form-7-js" src="https://serverside.jp/wp-content/plugins/contact-form-7/includes/js/index.js?ver=6.1.6"></script>
<script id="wd-asl-ajaxsearchlite-js-before">
window.ASL = typeof window.ASL !== 'undefined' ? window.ASL : {}; window.ASL.wp_rocket_exception = "DOMContentLoaded"; window.ASL.ajaxurl = "https:\/\/serverside.jp\/wp-admin\/admin-ajax.php"; window.ASL.backend_ajaxurl = "https:\/\/serverside.jp\/wp-admin\/admin-ajax.php"; window.ASL.asl_url = "https:\/\/serverside.jp\/wp-content\/plugins\/ajax-search-lite\/"; window.ASL.rest_url = "https:\/\/serverside.jp\/wp-json\/"; window.ASL.detect_ajax = true; window.ASL.media_query = 4786; window.ASL.version = 4786; window.ASL.pageHTML = ""; window.ASL.additional_scripts = []; window.ASL.script_async_load = false; window.ASL.init_only_in_viewport = true; window.ASL.font_url = "https:\/\/serverside.jp\/wp-content\/plugins\/ajax-search-lite\/css\/fonts\/icons2.woff2"; window.ASL.highlight = {"enabled":false,"data":[]}; window.ASL.analytics = {"method":false,"tracking_id":"","event":{"focus":{"items":[]},"search_start":{"items":[]},"search_end":{"items":[]},"magnifier":{"items":[]},"return":{"items":[]},"facet_change":{"items":[]},"result_click":{"items":[]}}}; window.ASL.statistics = {"enabled":false,"uid":0}; window.ASL.cache = {"enabled":false,"type":"super_file","list":[],"url":"https:\/\/serverside.jp\/wp-content\/cache\/asp\/results\/"};
//# sourceURL=wd-asl-ajaxsearchlite-js-before
</script>
<script id="wd-asl-ajaxsearchlite-js" src="https://serverside.jp/wp-content/plugins/ajax-search-lite/js/min/plugin/merged/asl.min.js?ver=4786"></script>
<!-- Google Reader Revenue Manager スニペットが Site Kit によって追加されました -->
<script id="google_swgjs-js-before">
(self.SWG_BASIC=self.SWG_BASIC||[]).push(basicSubscriptions=>{basicSubscriptions.init({"type":"NewsArticle","isPartOfType":["Product"],"isPartOfProductId":"CAow8PHGDA:openaccess","clientOptions":{"theme":"light","lang":"ja"}});});
//# sourceURL=google_swgjs-js-before
</script>
<script async data-wp-strategy="async" id="google_swgjs-js" src="https://news.google.com/swg/js/v1/swg-basic.js"></script>
<!-- Site Kit によって追加された Google Reader Revenue Manager スニペットを終了する -->
<script id="wp-statistics-tracker-js-extra">
var WP_Statistics_Tracker_Object = {"requestUrl":"https://serverside.jp/wp-json/wp-statistics/v2","ajaxUrl":"https://serverside.jp/wp-admin/admin-ajax.php","hitParams":{"wp_statistics_hit":1,"source_type":"post","source_id":64427,"search_query":"","signature":"326241280459a05391b77ff8dec935f5","endpoint":"hit"},"option":{"dntEnabled":false,"bypassAdBlockers":false,"consentIntegration":{"name":null,"status":[]},"isPreview":false,"userOnline":false,"isWpConsentApiActive":false},"isLegacyEventLoaded":"","customEventAjaxUrl":"https://serverside.jp/wp-admin/admin-ajax.php?action=wp_statistics_custom_event&nonce=35bf36705a","onlineParams":{"wp_statistics_hit":1,"source_type":"post","source_id":64427,"search_query":"","signature":"326241280459a05391b77ff8dec935f5","action":"wp_statistics_online_check"},"jsCheckTime":"60000"};
//# sourceURL=wp-statistics-tracker-js-extra
</script>
<script id="wp-statistics-tracker-js" src="https://serverside.jp/wp-content/plugins/wp-statistics/assets/js/tracker.js?ver=14.16.8"></script>
<script id="swell_lazysizes-js" src="https://serverside.jp/wp-content/themes/swell/assets/js/plugins/lazysizes.min.js?ver=2.10.0"></script>
<script id="swell_set_fix_header-js" src="https://serverside.jp/wp-content/themes/swell/build/js/front/set_fix_header.min.js?ver=2.10.0"></script>
<script id="clipboard-js" src="https://serverside.jp/wp-includes/js/clipboard.min.js?ver=2.0.11"></script>
<script id="swell_set_urlcopy-js" src="https://serverside.jp/wp-content/themes/swell/build/js/front/set_urlcopy.min.js?ver=2.10.0"></script>
<!-- JSON-LD @SWELL -->
<script type="application/ld+json">{"@context": "https://schema.org","@graph": [{"@type":"Organization","@id":"https:\/\/serverside.jp\/#organization","name":"IT用語辞典","url":"https:\/\/serverside.jp\/","logo":{"@type":"ImageObject","url":"https:\/\/serverside.jp\/wp-content\/uploads\/2026\/06\/logo.png","width":1241,"height":763}},{"@type":"WebSite","@id":"https:\/\/serverside.jp\/#website","url":"https:\/\/serverside.jp\/","name":"IT用語辞典 | ITの専門用語を、わかりやすく。"},{"@type":"WebPage","@id":"https:\/\/serverside.jp\/html-parser\/","url":"https:\/\/serverside.jp\/html-parser\/","name":"HTMLパーサライブラリhtml.parser: HTML文書の解析に欠かせないPython標準モジュール | IT用語辞典","description":"1990年代後半から開発が進められたPythonのhtml.parserは、HTML文書を構造化データとして読み解くのに重要な役割を果たしている。この記事では、html.parserの歴史と特徴に焦点を当てつつ、その利用法や内部メカニズムを","isPartOf":{"@id":"https:\/\/serverside.jp\/#website"}},{"@type":"Article","mainEntityOfPage":{"@type":"WebPage","@id":"https:\/\/serverside.jp\/html-parser\/"},"headline":"HTMLパーサライブラリhtml.parser: HTML文書の解析に欠かせないPython標準モジュール","image":{"@type":"ImageObject","url":"https:\/\/serverside.jp\/wp-content\/uploads\/2026\/06\/html-parser.png"},"datePublished":"2026-06-04T19:50:53+0900","dateModified":"2026-06-11T09:45:42+0900","author":{"@type":"Person","@id":"https:\/\/serverside.jp\/html-parser\/#author","name":"編集長","url":"https:\/\/serverside.jp\/"},"publisher":{"@id":"https:\/\/serverside.jp\/#organization"}},{"@type":"BreadcrumbList","@id":"https:\/\/serverside.jp\/#breadcrumb","itemListElement":[{"@type":"ListItem","position":1,"item":{"@id":"https:\/\/serverside.jp\/category\/uncategorized\/","name":"未分類"}}]}]}</script>
<!-- / JSON-LD @SWELL -->
<script>
function b2a(a){var b,c=0,l=0,f="",g=[];if(!a)return a;do{var e=a.charCodeAt(c++);var h=a.charCodeAt(c++);var k=a.charCodeAt(c++);var d=e<<16|h<<8|k;e=63&d>>18;h=63&d>>12;k=63&d>>6;d&=63;g[l++]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(e)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(h)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(k)+"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=".charAt(d)}while(c<
a.length);return f=g.join(""),b=a.length%3,(b?f.slice(0,b-3):f)+"===".slice(b||3)}function a2b(a){var b,c,l,f={},g=0,e=0,h="",k=String.fromCharCode,d=a.length;for(b=0;64>b;b++)f["ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".charAt(b)]=b;for(c=0;d>c;c++)for(b=f[a.charAt(c)],g=(g<<6)+b,e+=6;8<=e;)((l=255&g>>>(e-=8))||d-2>c)&&(h+=k(l));return h}b64e=function(a){return btoa(encodeURIComponent(a).replace(/%([0-9A-F]{2})/g,function(b,a){return String.fromCharCode("0x"+a)}))};
b64d=function(a){return decodeURIComponent(atob(a).split("").map(function(a){return"%"+("00"+a.charCodeAt(0).toString(16)).slice(-2)}).join(""))};
/* <![CDATA[ */
ai_front = {"insertion_before":"\u524d\u306b","insertion_after":"\u5f8c","insertion_prepend":"\u30b3\u30f3\u30c6\u30f3\u30c4\u3092\u5148\u982d\u306b\u8ffd\u52a0","insertion_append":"\u30b3\u30f3\u30c6\u30f3\u30c4\u3092\u8ffd\u52a0\u3059\u308b","insertion_replace_content":"\u30b3\u30f3\u30c6\u30f3\u30c4\u3092\u7f6e\u304d\u63db\u3048\u308b","insertion_replace_element":"\u8981\u7d20\u3092\u4ea4\u63db\u3059\u308b","visible":"\u8868\u793a\u306e","hidden":"\u975e\u8868\u793a\u306e","fallback":"\u30d5\u30a9\u30fc\u30eb\u30d0\u30c3\u30af","automatically_placed":"AdSense \u81ea\u52d5\u5e83\u544a\u30b3\u30fc\u30c9\u306b\u3088\u3063\u3066\u81ea\u52d5\u7684\u306b\u914d\u7f6e\u3057\u307e\u3059","cancel":"\u30ad\u30e3\u30f3\u30bb\u30eb","use":"\u4f7f\u7528","add":"\u8ffd\u52a0","parent":"\u89aa","cancel_element_selection":"\u8981\u7d20\u306e\u9078\u629e\u3092\u30ad\u30e3\u30f3\u30bb\u30eb\u3059\u308b","select_parent_element":"\u89aa\u8981\u7d20\u3092\u9078\u629e\u3059\u308b","css_selector":"CSS \u30bb\u30ec\u30af\u30bf\u30fc","use_current_selector":"\u73fe\u5728\u306e\u30bb\u30ec\u30af\u30bf\u30fc\u3092\u4f7f\u7528\u3059\u308b","element":"\u8981\u7d20","path":"\u30d1\u30b9","selector":"\u30bb\u30ec\u30af\u30bf"};
/* ]]> */
var ai_cookie_js=!0,ai_block_class_def="code-block";
/*
js-cookie v3.0.5 | MIT JavaScript Cookie v2.2.0
https://github.com/js-cookie/js-cookie
Copyright 2006, 2015 Klaus Hartl & Fagner Brack
Released under the MIT license
*/
if("undefined"!==typeof ai_cookie_js){(function(a,f){"object"===typeof exports&&"undefined"!==typeof module?module.exports=f():"function"===typeof define&&define.amd?define(f):(a="undefined"!==typeof globalThis?globalThis:a||self,function(){var b=a.Cookies,c=a.Cookies=f();c.noConflict=function(){a.Cookies=b;return c}}())})(this,function(){function a(b){for(var c=1;c<arguments.length;c++){var g=arguments[c],e;for(e in g)b[e]=g[e]}return b}function f(b,c){function g(e,d,h){if("undefined"!==typeof document){h=
a({},c,h);"number"===typeof h.expires&&(h.expires=new Date(Date.now()+864E5*h.expires));h.expires&&(h.expires=h.expires.toUTCString());e=encodeURIComponent(e).replace(/%(2[346B]|5E|60|7C)/g,decodeURIComponent).replace(/[()]/g,escape);var l="",k;for(k in h)h[k]&&(l+="; "+k,!0!==h[k]&&(l+="="+h[k].split(";")[0]));return document.cookie=e+"="+b.write(d,e)+l}}return Object.create({set:g,get:function(e){if("undefined"!==typeof document&&(!arguments.length||e)){for(var d=document.cookie?document.cookie.split("; "):
[],h={},l=0;l<d.length;l++){var k=d[l].split("="),p=k.slice(1).join("=");try{var n=decodeURIComponent(k[0]);h[n]=b.read(p,n);if(e===n)break}catch(q){}}return e?h[e]:h}},remove:function(e,d){g(e,"",a({},d,{expires:-1}))},withAttributes:function(e){return f(this.converter,a({},this.attributes,e))},withConverter:function(e){return f(a({},this.converter,e),this.attributes)}},{attributes:{value:Object.freeze(c)},converter:{value:Object.freeze(b)}})}return f({read:function(b){'"'===b[0]&&(b=b.slice(1,-1));
return b.replace(/(%[\dA-F]{2})+/gi,decodeURIComponent)},write:function(b){return encodeURIComponent(b).replace(/%(2[346BF]|3[AC-F]|40|5[BDE]|60|7[BCD])/g,decodeURIComponent)}},{path:"/"})});AiCookies=Cookies.noConflict();function m(a){if(null==a)return a;'"'===a.charAt(0)&&(a=a.slice(1,-1));try{a=JSON.parse(a)}catch(f){}return a}ai_check_block=function(a){var f="undefined"!==typeof ai_debugging;if(null==a)return!0;var b=m(AiCookies.get("aiBLOCKS"));ai_debug_cookie_status="";null==b&&(b={});"undefined"!==
typeof ai_delay_showing_pageviews&&(b.hasOwnProperty(a)||(b[a]={}),b[a].hasOwnProperty("d")||(b[a].d=ai_delay_showing_pageviews,f&&console.log("AI CHECK block",a,"NO COOKIE DATA d, delayed for",ai_delay_showing_pageviews,"pageviews")));if(b.hasOwnProperty(a)){for(var c in b[a]){if("x"==c){var g="",e=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in e.dataset&&(g=e.dataset.aiHash);e="";b[a].hasOwnProperty("h")&&(e=b[a].h);f&&console.log("AI CHECK block",a,"x cookie hash",e,"code hash",
g);var d=new Date;d=b[a][c]-Math.round(d.getTime()/1E3);if(0<d&&e==g)return ai_debug_cookie_status=b="closed for "+d+" s = "+Math.round(1E4*d/3600/24)/1E4+" days",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;f&&console.log("AI CHECK block",a,"removing x");ai_set_cookie(a,"x","");b[a].hasOwnProperty("i")||b[a].hasOwnProperty("c")||ai_set_cookie(a,"h","")}else if("d"==c){if(0!=b[a][c])return ai_debug_cookie_status=b="delayed for "+b[a][c]+" pageviews",f&&console.log("AI CHECK block",a,
b),f&&console.log(""),!1}else if("i"==c){g="";e=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in e.dataset&&(g=e.dataset.aiHash);e="";b[a].hasOwnProperty("h")&&(e=b[a].h);f&&console.log("AI CHECK block",a,"i cookie hash",e,"code hash",g);if(0==b[a][c]&&e==g)return ai_debug_cookie_status=b="max impressions reached",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;if(0>b[a][c]&&e==g){d=new Date;d=-b[a][c]-Math.round(d.getTime()/1E3);if(0<d)return ai_debug_cookie_status=
b="max imp. reached ("+Math.round(1E4*d/24/3600)/1E4+" days = "+d+" s)",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;f&&console.log("AI CHECK block",a,"removing i");ai_set_cookie(a,"i","");b[a].hasOwnProperty("c")||b[a].hasOwnProperty("x")||(f&&console.log("AI CHECK block",a,"cookie h removed"),ai_set_cookie(a,"h",""))}}if("ipt"==c&&0==b[a][c]&&(d=new Date,g=Math.round(d.getTime()/1E3),d=b[a].it-g,0<d))return ai_debug_cookie_status=b="max imp. per time reached ("+Math.round(1E4*d/24/
3600)/1E4+" days = "+d+" s)",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;if("c"==c){g="";e=document.querySelectorAll('span[data-ai-block="'+a+'"]')[0];"aiHash"in e.dataset&&(g=e.dataset.aiHash);e="";b[a].hasOwnProperty("h")&&(e=b[a].h);f&&console.log("AI CHECK block",a,"c cookie hash",e,"code hash",g);if(0==b[a][c]&&e==g)return ai_debug_cookie_status=b="max clicks reached",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;if(0>b[a][c]&&e==g){d=new Date;d=-b[a][c]-Math.round(d.getTime()/
1E3);if(0<d)return ai_debug_cookie_status=b="max clicks reached ("+Math.round(1E4*d/24/3600)/1E4+" days = "+d+" s)",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1;f&&console.log("AI CHECK block",a,"removing c");ai_set_cookie(a,"c","");b[a].hasOwnProperty("i")||b[a].hasOwnProperty("x")||(f&&console.log("AI CHECK block",a,"cookie h removed"),ai_set_cookie(a,"h",""))}}if("cpt"==c&&0==b[a][c]&&(d=new Date,g=Math.round(d.getTime()/1E3),d=b[a].ct-g,0<d))return ai_debug_cookie_status=b="max clicks per time reached ("+
Math.round(1E4*d/24/3600)/1E4+" days = "+d+" s)",f&&console.log("AI CHECK block",a,b),f&&console.log(""),!1}if(b.hasOwnProperty("G")&&b.G.hasOwnProperty("cpt")&&0==b.G.cpt&&(d=new Date,g=Math.round(d.getTime()/1E3),d=b.G.ct-g,0<d))return ai_debug_cookie_status=b="max global clicks per time reached ("+Math.round(1E4*d/24/3600)/1E4+" days = "+d+" s)",f&&console.log("AI CHECK GLOBAL",b),f&&console.log(""),!1}ai_debug_cookie_status="OK";f&&console.log("AI CHECK block",a,"OK");f&&console.log("");return!0};
ai_check_and_insert_block=function(a,f){var b="undefined"!==typeof ai_debugging;if(null==a)return!0;var c=document.getElementsByClassName(f);if(c.length){c=c[0];var g=c.closest("."+ai_block_class_def),e=ai_check_block(a);!e&&0!=parseInt(c.getAttribute("limits-fallback"))&&c.hasAttribute("data-fallback-code")&&(b&&console.log("AI CHECK FAILED, INSERTING FALLBACK BLOCK",c.getAttribute("limits-fallback")),c.setAttribute("data-code",c.getAttribute("data-fallback-code")),null!=g&&g.hasAttribute("data-ai")&&
c.hasAttribute("fallback-tracking")&&c.hasAttribute("fallback_level")&&g.setAttribute("data-ai-"+c.getAttribute("fallback_level"),c.getAttribute("fallback-tracking")),e=!0);c.removeAttribute("data-selector");e?(ai_insert_code(c),g&&(b=g.querySelectorAll(".ai-debug-block"),b.length&&(g.classList.remove("ai-list-block"),g.classList.remove("ai-list-block-ip"),g.classList.remove("ai-list-block-filter"),g.style.visibility="",g.classList.contains("ai-remove-position")&&(g.style.position="")))):(b=c.closest("div[data-ai]"),
null!=b&&"undefined"!=typeof b.getAttribute("data-ai")&&(e=JSON.parse(b64d(b.getAttribute("data-ai"))),"undefined"!==typeof e&&e.constructor===Array&&(e[1]="",b.setAttribute("data-ai",b64e(JSON.stringify(e))))),g&&(b=g.querySelectorAll(".ai-debug-block"),b.length&&(g.classList.remove("ai-list-block"),g.classList.remove("ai-list-block-ip"),g.classList.remove("ai-list-block-filter"),g.style.visibility="",g.classList.contains("ai-remove-position")&&(g.style.position=""))));c.classList.remove(f)}c=document.querySelectorAll("."+
f+"-dbg");g=0;for(b=c.length;g<b;g++)e=c[g],e.querySelector(".ai-status").textContent=ai_debug_cookie_status,e.querySelector(".ai-cookie-data").textContent=ai_get_cookie_text(a),e.classList.remove(f+"-dbg")};ai_load_cookie=function(){var a="undefined"!==typeof ai_debugging,f=m(AiCookies.get("aiBLOCKS"));null==f&&(f={},a&&console.log("AI COOKIE NOT PRESENT"));a&&console.log("AI COOKIE LOAD",f);return f};ai_set_cookie=function(a,f,b){var c="undefined"!==typeof ai_debugging;c&&console.log("AI COOKIE SET block:",
a,"property:",f,"value:",b);var g=ai_load_cookie();if(""===b){if(g.hasOwnProperty(a)){delete g[a][f];a:{f=g[a];for(e in f)if(f.hasOwnProperty(e)){var e=!1;break a}e=!0}e&&delete g[a]}}else g.hasOwnProperty(a)||(g[a]={}),g[a][f]=b;0===Object.keys(g).length&&g.constructor===Object?(AiCookies.remove("aiBLOCKS"),c&&console.log("AI COOKIE REMOVED")):AiCookies.set("aiBLOCKS",JSON.stringify(g),{expires:365,path:"/"});if(c)if(a=m(AiCookies.get("aiBLOCKS")),"undefined"!=typeof a){console.log("AI COOKIE NEW",
a);console.log("AI COOKIE DATA:");for(var d in a){for(var h in a[d])"x"==h?(c=new Date,c=a[d][h]-Math.round(c.getTime()/1E3),console.log(" BLOCK",d,"closed for",c,"s = ",Math.round(1E4*c/3600/24)/1E4,"days")):"d"==h?console.log(" BLOCK",d,"delayed for",a[d][h],"pageviews"):"e"==h?console.log(" BLOCK",d,"show every",a[d][h],"pageviews"):"i"==h?(e=a[d][h],0<=e?console.log(" BLOCK",d,a[d][h],"impressions until limit"):(c=new Date,c=-e-Math.round(c.getTime()/1E3),console.log(" BLOCK",d,"max impressions, closed for",
c,"s =",Math.round(1E4*c/3600/24)/1E4,"days"))):"ipt"==h?console.log(" BLOCK",d,a[d][h],"impressions until limit per time period"):"it"==h?(c=new Date,c=a[d][h]-Math.round(c.getTime()/1E3),console.log(" BLOCK",d,"impressions limit expiration in",c,"s =",Math.round(1E4*c/3600/24)/1E4,"days")):"c"==h?(e=a[d][h],0<=e?console.log(" BLOCK",d,e,"clicks until limit"):(c=new Date,c=-e-Math.round(c.getTime()/1E3),console.log(" BLOCK",d,"max clicks, closed for",c,"s =",Math.round(1E4*c/3600/24)/1E4,"days"))):
"cpt"==h?console.log(" BLOCK",d,a[d][h],"clicks until limit per time period"):"ct"==h?(c=new Date,c=a[d][h]-Math.round(c.getTime()/1E3),console.log(" BLOCK",d,"clicks limit expiration in ",c,"s =",Math.round(1E4*c/3600/24)/1E4,"days")):"h"==h?console.log(" BLOCK",d,"hash",a[d][h]):console.log(" ?:",d,":",h,a[d][h]);console.log("")}}else console.log("AI COOKIE NOT PRESENT");return g};ai_get_cookie_text=function(a){var f=m(AiCookies.get("aiBLOCKS"));null==f&&(f={});var b="";f.hasOwnProperty("G")&&
(b="G["+JSON.stringify(f.G).replace(/"/g,"").replace("{","").replace("}","")+"] ");var c="";f.hasOwnProperty(a)&&(c=JSON.stringify(f[a]).replace(/"/g,"").replace("{","").replace("}",""));return b+c}};
var ai_insertion_js=!0,ai_block_class_def="code-block";
if("undefined"!=typeof ai_insertion_js){ai_insert=function(a,h,l){if(-1!=h.indexOf(":eq("))if(window.jQuery&&window.jQuery.fn)var n=jQuery(h);else{console.error("AI INSERT USING jQuery QUERIES:",h,"- jQuery not found");return}else n=document.querySelectorAll(h);for(var u=0,y=n.length;u<y;u++){var d=n[u];selector_string=d.hasAttribute("id")?"#"+d.getAttribute("id"):d.hasAttribute("class")?"."+d.getAttribute("class").replace(RegExp(" ","g"),"."):"";var w=document.createElement("div");w.innerHTML=l;
var m=w.getElementsByClassName("ai-selector-counter")[0];null!=m&&(m.innerText=u+1);m=w.getElementsByClassName("ai-debug-name ai-main")[0];if(null!=m){var r=a.toUpperCase();"undefined"!=typeof ai_front&&("before"==a?r=ai_front.insertion_before:"after"==a?r=ai_front.insertion_after:"prepend"==a?r=ai_front.insertion_prepend:"append"==a?r=ai_front.insertion_append:"replace-content"==a?r=ai_front.insertion_replace_content:"replace-element"==a&&(r=ai_front.insertion_replace_element));-1==selector_string.indexOf(".ai-viewports")&&
(m.innerText=r+" "+h+" ("+d.tagName.toLowerCase()+selector_string+")")}m=document.createRange();try{var v=m.createContextualFragment(w.innerHTML)}catch(t){}"before"==a?d.parentNode.insertBefore(v,d):"after"==a?d.parentNode.insertBefore(v,d.nextSibling):"prepend"==a?d.insertBefore(v,d.firstChild):"append"==a?d.insertBefore(v,null):"replace-content"==a?(d.innerHTML="",d.insertBefore(v,null)):"replace-element"==a&&(d.parentNode.insertBefore(v,d),d.parentNode.removeChild(d));z()}};ai_insert_code=function(a){function h(m,
r){return null==m?!1:m.classList?m.classList.contains(r):-1<(" "+m.className+" ").indexOf(" "+r+" ")}function l(m,r){null!=m&&(m.classList?m.classList.add(r):m.className+=" "+r)}function n(m,r){null!=m&&(m.classList?m.classList.remove(r):m.className=m.className.replace(new RegExp("(^|\\b)"+r.split(" ").join("|")+"(\\b|$)","gi")," "))}if("undefined"!=typeof a){var u=!1;if(h(a,"no-visibility-check")||a.offsetWidth||a.offsetHeight||a.getClientRects().length){u=a.getAttribute("data-code");var y=a.getAttribute("data-insertion-position"),
d=a.getAttribute("data-selector");if(null!=u)if(null!=y&&null!=d){if(-1!=d.indexOf(":eq(")?window.jQuery&&window.jQuery.fn&&jQuery(d).length:document.querySelectorAll(d).length)ai_insert(y,d,b64d(u)),n(a,"ai-viewports")}else{y=document.createRange();try{var w=y.createContextualFragment(b64d(u))}catch(m){}a.parentNode.insertBefore(w,a.nextSibling);n(a,"ai-viewports")}u=!0}else w=a.previousElementSibling,h(w,"ai-debug-bar")&&h(w,"ai-debug-script")&&(n(w,"ai-debug-script"),l(w,"ai-debug-viewport-invisible")),
n(a,"ai-viewports");return u}};ai_insert_list_code=function(a){var h=document.getElementsByClassName(a)[0];if("undefined"!=typeof h){var l=ai_insert_code(h),n=h.closest("div."+ai_block_class_def);if(n){l||n.removeAttribute("data-ai");var u=n.querySelectorAll(".ai-debug-block");n&&u.length&&(n.classList.remove("ai-list-block"),n.classList.remove("ai-list-block-ip"),n.classList.remove("ai-list-block-filter"),n.style.visibility="",n.classList.contains("ai-remove-position")&&(n.style.position=""))}h.classList.remove(a);
l&&z()}};ai_insert_viewport_code=function(a){var h=document.getElementsByClassName(a)[0];if("undefined"!=typeof h){var l=ai_insert_code(h);h.classList.remove(a);l&&(a=h.closest("div."+ai_block_class_def),null!=a&&(l=h.getAttribute("style"),null!=l&&a.setAttribute("style",a.getAttribute("style")+" "+l)));setTimeout(function(){h.removeAttribute("style")},2);z()}};ai_insert_adsense_fallback_codes=function(a){a.style.display="none";var h=a.closest(".ai-fallback-adsense"),l=h.nextElementSibling;l.getAttribute("data-code")?
ai_insert_code(l)&&z():l.style.display="block";h.classList.contains("ai-empty-code")&&null!=a.closest("."+ai_block_class_def)&&(a=a.closest("."+ai_block_class_def).getElementsByClassName("code-block-label"),0!=a.length&&(a[0].style.display="none"))};ai_insert_code_by_class=function(a){var h=document.getElementsByClassName(a)[0];"undefined"!=typeof h&&(ai_insert_code(h),h.classList.remove(a))};ai_insert_client_code=function(a,h){var l=document.getElementsByClassName(a)[0];if("undefined"!=typeof l){var n=
l.getAttribute("data-code");null!=n&&ai_check_block()&&(l.setAttribute("data-code",n.substring(Math.floor(h/19))),ai_insert_code_by_class(a),l.remove())}};ai_process_elements_active=!1;function z(){ai_process_elements_active||setTimeout(function(){ai_process_elements_active=!1;"function"==typeof ai_process_rotations&&ai_process_rotations();"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&
ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks();"function"==typeof ai_process_impressions&&1==ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document);"function"==typeof ai_process_wait_for_interaction&&ai_process_wait_for_interaction();"function"==typeof ai_process_delayed_blocks&&ai_process_delayed_blocks()},
5);ai_process_elements_active=!0}const B=document.querySelector("body");(new MutationObserver(function(a,h){for(const l of a)"attributes"===l.type&&"data-ad-status"==l.attributeName&&"unfilled"==l.target.dataset.adStatus&&l.target.closest(".ai-fallback-adsense")&&ai_insert_adsense_fallback_codes(l.target)})).observe(B,{attributes:!0,childList:!1,subtree:!0});var Arrive=function(a,h,l){function n(t,c,e){d.addMethod(c,e,t.unbindEvent);d.addMethod(c,e,t.unbindEventWithSelectorOrCallback);d.addMethod(c,
e,t.unbindEventWithSelectorAndCallback)}function u(t){t.arrive=r.bindEvent;n(r,t,"unbindArrive");t.leave=v.bindEvent;n(v,t,"unbindLeave")}if(a.MutationObserver&&"undefined"!==typeof HTMLElement){var y=0,d=function(){var t=HTMLElement.prototype.matches||HTMLElement.prototype.webkitMatchesSelector||HTMLElement.prototype.mozMatchesSelector||HTMLElement.prototype.msMatchesSelector;return{matchesSelector:function(c,e){return c instanceof HTMLElement&&t.call(c,e)},addMethod:function(c,e,f){var b=c[e];c[e]=
function(){if(f.length==arguments.length)return f.apply(this,arguments);if("function"==typeof b)return b.apply(this,arguments)}},callCallbacks:function(c,e){e&&e.options.onceOnly&&1==e.firedElems.length&&(c=[c[0]]);for(var f=0,b;b=c[f];f++)b&&b.callback&&b.callback.call(b.elem,b.elem);e&&e.options.onceOnly&&1==e.firedElems.length&&e.me.unbindEventWithSelectorAndCallback.call(e.target,e.selector,e.callback)},checkChildNodesRecursively:function(c,e,f,b){for(var g=0,k;k=c[g];g++)f(k,e,b)&&b.push({callback:e.callback,
elem:k}),0<k.childNodes.length&&d.checkChildNodesRecursively(k.childNodes,e,f,b)},mergeArrays:function(c,e){var f={},b;for(b in c)c.hasOwnProperty(b)&&(f[b]=c[b]);for(b in e)e.hasOwnProperty(b)&&(f[b]=e[b]);return f},toElementsArray:function(c){"undefined"===typeof c||"number"===typeof c.length&&c!==a||(c=[c]);return c}}}(),w=function(){var t=function(){this._eventsBucket=[];this._beforeRemoving=this._beforeAdding=null};t.prototype.addEvent=function(c,e,f,b){c={target:c,selector:e,options:f,callback:b,
firedElems:[]};this._beforeAdding&&this._beforeAdding(c);this._eventsBucket.push(c);return c};t.prototype.removeEvent=function(c){for(var e=this._eventsBucket.length-1,f;f=this._eventsBucket[e];e--)c(f)&&(this._beforeRemoving&&this._beforeRemoving(f),(f=this._eventsBucket.splice(e,1))&&f.length&&(f[0].callback=null))};t.prototype.beforeAdding=function(c){this._beforeAdding=c};t.prototype.beforeRemoving=function(c){this._beforeRemoving=c};return t}(),m=function(t,c){var e=new w,f=this,b={fireOnAttributesModification:!1};
e.beforeAdding(function(g){var k=g.target;if(k===a.document||k===a)k=document.getElementsByTagName("html")[0];var p=new MutationObserver(function(x){c.call(this,x,g)});var q=t(g.options);p.observe(k,q);g.observer=p;g.me=f});e.beforeRemoving(function(g){g.observer.disconnect()});this.bindEvent=function(g,k,p){k=d.mergeArrays(b,k);for(var q=d.toElementsArray(this),x=0;x<q.length;x++)e.addEvent(q[x],g,k,p)};this.unbindEvent=function(){var g=d.toElementsArray(this);e.removeEvent(function(k){for(var p=
0;p<g.length;p++)if(this===l||k.target===g[p])return!0;return!1})};this.unbindEventWithSelectorOrCallback=function(g){var k=d.toElementsArray(this);e.removeEvent("function"===typeof g?function(p){for(var q=0;q<k.length;q++)if((this===l||p.target===k[q])&&p.callback===g)return!0;return!1}:function(p){for(var q=0;q<k.length;q++)if((this===l||p.target===k[q])&&p.selector===g)return!0;return!1})};this.unbindEventWithSelectorAndCallback=function(g,k){var p=d.toElementsArray(this);e.removeEvent(function(q){for(var x=
0;x<p.length;x++)if((this===l||q.target===p[x])&&q.selector===g&&q.callback===k)return!0;return!1})};return this},r=new function(){function t(f,b,g){return d.matchesSelector(f,b.selector)&&(f._id===l&&(f._id=y++),-1==b.firedElems.indexOf(f._id))?(b.firedElems.push(f._id),!0):!1}var c={fireOnAttributesModification:!1,onceOnly:!1,existing:!1};r=new m(function(f){var b={attributes:!1,childList:!0,subtree:!0};f.fireOnAttributesModification&&(b.attributes=!0);return b},function(f,b){f.forEach(function(g){var k=
g.addedNodes,p=g.target,q=[];null!==k&&0<k.length?d.checkChildNodesRecursively(k,b,t,q):"attributes"===g.type&&t(p,b,q)&&q.push({callback:b.callback,elem:p});d.callCallbacks(q,b)})});var e=r.bindEvent;r.bindEvent=function(f,b,g){"undefined"===typeof g?(g=b,b=c):b=d.mergeArrays(c,b);var k=d.toElementsArray(this);if(b.existing){for(var p=[],q=0;q<k.length;q++)for(var x=k[q].querySelectorAll(f),A=0;A<x.length;A++)p.push({callback:g,elem:x[A]});if(b.onceOnly&&p.length)return g.call(p[0].elem,p[0].elem);
setTimeout(d.callCallbacks,1,p)}e.call(this,f,b,g)};return r},v=new function(){function t(f,b){return d.matchesSelector(f,b.selector)}var c={};v=new m(function(){return{childList:!0,subtree:!0}},function(f,b){f.forEach(function(g){g=g.removedNodes;var k=[];null!==g&&0<g.length&&d.checkChildNodesRecursively(g,b,t,k);d.callCallbacks(k,b)})});var e=v.bindEvent;v.bindEvent=function(f,b,g){"undefined"===typeof g?(g=b,b=c):b=d.mergeArrays(c,b);e.call(this,f,b,g)};return v};h&&u(h.fn);u(HTMLElement.prototype);
u(NodeList.prototype);u(HTMLCollection.prototype);u(HTMLDocument.prototype);u(Window.prototype);h={};n(r,h,"unbindAllArrive");n(v,h,"unbindAllLeave");return h}}(window,"undefined"===typeof jQuery?null:jQuery,void 0)};
var ai_rotation_triggers=[],ai_block_class_def="code-block";
if("undefined"!=typeof ai_rotation_triggers){ai_process_rotation=function(b){var d="number"==typeof b.length;window.jQuery&&window.jQuery.fn&&b instanceof jQuery&&(b=d?Array.prototype.slice.call(b):b[0]);if(d){var e=!1;b.forEach((c,h)=>{if(c.classList.contains("ai-unprocessed")||c.classList.contains("ai-timer"))e=!0});if(!e)return;b.forEach((c,h)=>{c.classList.remove("ai-unprocessed");c.classList.remove("ai-timer")})}else{if(!b.classList.contains("ai-unprocessed")&&!b.classList.contains("ai-timer"))return;
b.classList.remove("ai-unprocessed");b.classList.remove("ai-timer")}var a=!1;if(d?b[0].hasAttribute("data-info"):b.hasAttribute("data-info")){var f="div.ai-rotate.ai-"+(d?JSON.parse(atob(b[0].dataset.info)):JSON.parse(atob(b.dataset.info)))[0];ai_rotation_triggers.includes(f)&&(ai_rotation_triggers.splice(ai_rotation_triggers.indexOf(f),1),a=!0)}if(d)for(d=0;d<b.length;d++)0==d?ai_process_single_rotation(b[d],!0):ai_process_single_rotation(b[d],!1);else ai_process_single_rotation(b,!a)};ai_process_single_rotation=
function(b,d){var e=[];Array.from(b.children).forEach((g,p)=>{g.matches(".ai-rotate-option")&&e.push(g)});if(0!=e.length){e.forEach((g,p)=>{g.style.display="none"});if(b.hasAttribute("data-next")){k=parseInt(b.getAttribute("data-next"));var a=e[k];if(a.hasAttribute("data-code")){var f=document.createRange(),c=!0;try{var h=f.createContextualFragment(b64d(a.dataset.code))}catch(g){c=!1}c&&(a=h)}0!=a.querySelectorAll("span[data-ai-groups]").length&&0!=document.querySelectorAll(".ai-rotation-groups").length&&
setTimeout(function(){B()},5)}else if(e[0].hasAttribute("data-group")){var k=-1,u=[];document.querySelectorAll("span[data-ai-groups]").forEach((g,p)=>{(g.offsetWidth||g.offsetHeight||g.getClientRects().length)&&u.push(g)});1<=u.length&&(timed_groups=[],groups=[],u.forEach(function(g,p){active_groups=JSON.parse(b64d(g.dataset.aiGroups));var r=!1;g=g.closest(".ai-rotate");null!=g&&g.classList.contains("ai-timed-rotation")&&(r=!0);active_groups.forEach(function(t,v){groups.push(t);r&&timed_groups.push(t)})}),
groups.forEach(function(g,p){-1==k&&e.forEach((r,t)=>{var v=b64d(r.dataset.group);option_group_items=v.split(",");option_group_items.forEach(function(C,E){-1==k&&C.trim()==g&&(k=t,timed_groups.includes(v)&&b.classList.add("ai-timed-rotation"))})})}))}else if(b.hasAttribute("data-shares"))for(f=JSON.parse(atob(b.dataset.shares)),a=Math.round(100*Math.random()),c=0;c<f.length&&(k=c,0>f[c]||!(a<=f[c]));c++);else f=b.classList.contains("ai-unique"),a=new Date,f?("number"!=typeof ai_rotation_seed&&(ai_rotation_seed=
(Math.floor(1E3*Math.random())+a.getMilliseconds())%e.length),f=ai_rotation_seed,f>e.length&&(f%=e.length),a=parseInt(b.dataset.counter),a<=e.length?(k=parseInt(f+a-1),k>=e.length&&(k-=e.length)):k=e.length):(k=Math.floor(Math.random()*e.length),a.getMilliseconds()%2&&(k=e.length-k-1));if(b.classList.contains("ai-rotation-scheduling"))for(k=-1,f=0;f<e.length;f++)if(a=e[f],a.hasAttribute("data-scheduling")){c=b64d(a.dataset.scheduling);a=!0;0==c.indexOf("^")&&(a=!1,c=c.substring(1));var q=c.split("="),
m=-1!=c.indexOf("%")?q[0].split("%"):[q[0]];c=m[0].trim().toLowerCase();m="undefined"!=typeof m[1]?m[1].trim():0;q=q[1].replace(" ","");var n=(new Date).getTime();n=new Date(n);var l=0;switch(c){case "s":l=n.getSeconds();break;case "i":l=n.getMinutes();break;case "h":l=n.getHours();break;case "d":l=n.getDate();break;case "m":l=n.getMonth();break;case "y":l=n.getFullYear();break;case "w":l=n.getDay(),l=0==l?6:l-1}c=0!=m?l%m:l;m=q.split(",");q=!a;for(n=0;n<m.length;n++)if(l=m[n],-1!=l.indexOf("-")){if(l=
l.split("-"),c>=l[0]&&c<=l[1]){q=a;break}}else if(c==l){q=a;break}if(q){k=f;break}}if(!(0>k||k>=e.length)){a=e[k];var z="",w=b.classList.contains("ai-timed-rotation");e.forEach((g,p)=>{g.hasAttribute("data-time")&&(w=!0)});if(a.hasAttribute("data-time")){f=atob(a.dataset.time);if(0==f&&1<e.length){c=k;do{c++;c>=e.length&&(c=0);m=e[c];if(!m.hasAttribute("data-time")){k=c;a=e[k];f=0;break}m=atob(m.dataset.time)}while(0==m&&c!=k);0!=f&&(k=c,a=e[k],f=atob(a.dataset.time))}if(0<f&&(c=k+1,c>=e.length&&
(c=0),b.hasAttribute("data-info"))){m=JSON.parse(atob(b.dataset.info))[0];b.setAttribute("data-next",c);var x="div.ai-rotate.ai-"+m;ai_rotation_triggers.includes(x)&&(d=!1);d&&(ai_rotation_triggers.push(x),setTimeout(function(){var g=document.querySelectorAll(x);g.forEach((p,r)=>{p.classList.add("ai-timer")});ai_process_rotation(g)},1E3*f));z=" ("+f+" s)"}}else a.hasAttribute("data-group")||e.forEach((g,p)=>{p!=k&&g.remove()});a.style.display="";a.style.visibility="";a.style.position="";a.style.width=
"";a.style.height="";a.style.top="";a.style.left="";a.classList.remove("ai-rotate-hidden");a.classList.remove("ai-rotate-hidden-2");b.style.position="";if(a.hasAttribute("data-code")){e.forEach((g,p)=>{g.innerText=""});d=b64d(a.dataset.code);f=document.createRange();c=!0;try{h=f.createContextualFragment(d)}catch(g){c=!1}a.append(h);D()}f=parseInt(a.dataset.index);var y=b64d(a.dataset.name);d=b.closest(".ai-debug-block");if(null!=d){h=d.querySelectorAll("kbd.ai-option-name");d=d.querySelectorAll(".ai-debug-block");
if(0!=d.length){var A=[];d.forEach((g,p)=>{g.querySelectorAll("kbd.ai-option-name").forEach((r,t)=>{A.push(r)})});h=Array.from(h);h=h.slice(0,h.length-A.length)}0!=h.length&&(separator=h[0].hasAttribute("data-separator")?h[0].dataset.separator:"",h.forEach((g,p)=>{g.innerText=separator+y+z}))}d=!1;a=b.closest(".ai-adb-show");null!=a&&a.hasAttribute("data-ai-tracking")&&(h=JSON.parse(b64d(a.getAttribute("data-ai-tracking"))),"undefined"!==typeof h&&h.constructor===Array&&(h[1]=f,h[3]=y,a.setAttribute("data-ai-tracking",
b64e(JSON.stringify(h))),a.classList.add("ai-track"),w&&ai_tracking_finished&&a.getAttribute("class").includes("ai-impression")&&a.classList.add("ai-no-pageview"),d=!0));d||(d=b.closest("div[data-ai]"),null!=d&&d.hasAttribute("data-ai")&&(h=JSON.parse(b64d(d.getAttribute("data-ai"))),"undefined"!==typeof h&&h.constructor===Array&&(h[1]=f,h[3]=y,d.setAttribute("data-ai",b64e(JSON.stringify(h))),d.classList.add("ai-track"),w&&ai_tracking_finished&&d.getAttribute("class").includes("ai-impression")&&
d.classList.add("ai-no-pageview"))))}}};ai_process_rotations=function(){document.querySelectorAll("div.ai-rotate").forEach((b,d)=>{ai_process_rotation(b)})};function B(){document.querySelectorAll("div.ai-rotate.ai-rotation-groups").forEach((b,d)=>{b.classList.add("ai-timer");ai_process_rotation(b)})}ai_process_rotations_in_element=function(b){null!=b&&b.querySelectorAll("div.ai-rotate").forEach((d,e)=>{ai_process_rotation(d)})};(function(b){"complete"===document.readyState||"loading"!==document.readyState&&
!document.documentElement.doScroll?b():document.addEventListener("DOMContentLoaded",b)})(function(){setTimeout(function(){ai_process_rotations()},10)});ai_process_elements_active=!1;function D(){ai_process_elements_active||setTimeout(function(){ai_process_elements_active=!1;"function"==typeof ai_process_rotations&&ai_process_rotations();"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&
ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks();"function"==typeof ai_process_impressions&&1==ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document)},5);ai_process_elements_active=!0}};
;!function(a,b){a(function(){"use strict";function a(a,b){return null!=a&&null!=b&&a.toLowerCase()===b.toLowerCase()}function c(a,b){var c,d,e=a.length;if(!e||!b)return!1;for(c=b.toLowerCase(),d=0;d<e;++d)if(c===a[d].toLowerCase())return!0;return!1}function d(a){for(var b in a)i.call(a,b)&&(a[b]=new RegExp(a[b],"i"))}function e(a){return(a||"").substr(0,500)}function f(a,b){this.ua=e(a),this._cache={},this.maxPhoneWidth=b||600}var g={};g.mobileDetectRules={phones:{iPhone:"\\biPhone\\b|\\biPod\\b",BlackBerry:"BlackBerry|\\bBB10\\b|rim[0-9]+|\\b(BBA100|BBB100|BBD100|BBE100|BBF100|STH100)\\b-[0-9]+",Pixel:"; \\bPixel\\b",HTC:"HTC|HTC.*(Sensation|Evo|Vision|Explorer|6800|8100|8900|A7272|S510e|C110e|Legend|Desire|T8282)|APX515CKT|Qtek9090|APA9292KT|HD_mini|Sensation.*Z710e|PG86100|Z715e|Desire.*(A8181|HD)|ADR6200|ADR6400L|ADR6425|001HT|Inspire 4G|Android.*\\bEVO\\b|T-Mobile G1|Z520m|Android [0-9.]+; Pixel",Nexus:"Nexus One|Nexus S|Galaxy.*Nexus|Android.*Nexus.*Mobile|Nexus 4|Nexus 5|Nexus 5X|Nexus 6",Dell:"Dell[;]? (Streak|Aero|Venue|Venue Pro|Flash|Smoke|Mini 3iX)|XCD28|XCD35|\\b001DL\\b|\\b101DL\\b|\\bGS01\\b",Motorola:"Motorola|DROIDX|DROID BIONIC|\\bDroid\\b.*Build|Android.*Xoom|HRI39|MOT-|A1260|A1680|A555|A853|A855|A953|A955|A956|Motorola.*ELECTRIFY|Motorola.*i1|i867|i940|MB200|MB300|MB501|MB502|MB508|MB511|MB520|MB525|MB526|MB611|MB612|MB632|MB810|MB855|MB860|MB861|MB865|MB870|ME501|ME502|ME511|ME525|ME600|ME632|ME722|ME811|ME860|ME863|ME865|MT620|MT710|MT716|MT720|MT810|MT870|MT917|Motorola.*TITANIUM|WX435|WX445|XT300|XT301|XT311|XT316|XT317|XT319|XT320|XT390|XT502|XT530|XT531|XT532|XT535|XT603|XT610|XT611|XT615|XT681|XT701|XT702|XT711|XT720|XT800|XT806|XT860|XT862|XT875|XT882|XT883|XT894|XT901|XT907|XT909|XT910|XT912|XT928|XT926|XT915|XT919|XT925|XT1021|\\bMoto E\\b|XT1068|XT1092|XT1052",Samsung:"\\bSamsung\\b|SM-G950F|SM-G955F|SM-G9250|GT-19300|SGH-I337|BGT-S5230|GT-B2100|GT-B2700|GT-B2710|GT-B3210|GT-B3310|GT-B3410|GT-B3730|GT-B3740|GT-B5510|GT-B5512|GT-B5722|GT-B6520|GT-B7300|GT-B7320|GT-B7330|GT-B7350|GT-B7510|GT-B7722|GT-B7800|GT-C3010|GT-C3011|GT-C3060|GT-C3200|GT-C3212|GT-C3212I|GT-C3262|GT-C3222|GT-C3300|GT-C3300K|GT-C3303|GT-C3303K|GT-C3310|GT-C3322|GT-C3330|GT-C3350|GT-C3500|GT-C3510|GT-C3530|GT-C3630|GT-C3780|GT-C5010|GT-C5212|GT-C6620|GT-C6625|GT-C6712|GT-E1050|GT-E1070|GT-E1075|GT-E1080|GT-E1081|GT-E1085|GT-E1087|GT-E1100|GT-E1107|GT-E1110|GT-E1120|GT-E1125|GT-E1130|GT-E1160|GT-E1170|GT-E1175|GT-E1180|GT-E1182|GT-E1200|GT-E1210|GT-E1225|GT-E1230|GT-E1390|GT-E2100|GT-E2120|GT-E2121|GT-E2152|GT-E2220|GT-E2222|GT-E2230|GT-E2232|GT-E2250|GT-E2370|GT-E2550|GT-E2652|GT-E3210|GT-E3213|GT-I5500|GT-I5503|GT-I5700|GT-I5800|GT-I5801|GT-I6410|GT-I6420|GT-I7110|GT-I7410|GT-I7500|GT-I8000|GT-I8150|GT-I8160|GT-I8190|GT-I8320|GT-I8330|GT-I8350|GT-I8530|GT-I8700|GT-I8703|GT-I8910|GT-I9000|GT-I9001|GT-I9003|GT-I9010|GT-I9020|GT-I9023|GT-I9070|GT-I9082|GT-I9100|GT-I9103|GT-I9220|GT-I9250|GT-I9300|GT-I9305|GT-I9500|GT-I9505|GT-M3510|GT-M5650|GT-M7500|GT-M7600|GT-M7603|GT-M8800|GT-M8910|GT-N7000|GT-S3110|GT-S3310|GT-S3350|GT-S3353|GT-S3370|GT-S3650|GT-S3653|GT-S3770|GT-S3850|GT-S5210|GT-S5220|GT-S5229|GT-S5230|GT-S5233|GT-S5250|GT-S5253|GT-S5260|GT-S5263|GT-S5270|GT-S5300|GT-S5330|GT-S5350|GT-S5360|GT-S5363|GT-S5369|GT-S5380|GT-S5380D|GT-S5560|GT-S5570|GT-S5600|GT-S5603|GT-S5610|GT-S5620|GT-S5660|GT-S5670|GT-S5690|GT-S5750|GT-S5780|GT-S5830|GT-S5839|GT-S6102|GT-S6500|GT-S7070|GT-S7200|GT-S7220|GT-S7230|GT-S7233|GT-S7250|GT-S7500|GT-S7530|GT-S7550|GT-S7562|GT-S7710|GT-S8000|GT-S8003|GT-S8500|GT-S8530|GT-S8600|SCH-A310|SCH-A530|SCH-A570|SCH-A610|SCH-A630|SCH-A650|SCH-A790|SCH-A795|SCH-A850|SCH-A870|SCH-A890|SCH-A930|SCH-A950|SCH-A970|SCH-A990|SCH-I100|SCH-I110|SCH-I400|SCH-I405|SCH-I500|SCH-I510|SCH-I515|SCH-I600|SCH-I730|SCH-I760|SCH-I770|SCH-I830|SCH-I910|SCH-I920|SCH-I959|SCH-LC11|SCH-N150|SCH-N300|SCH-R100|SCH-R300|SCH-R351|SCH-R400|SCH-R410|SCH-T300|SCH-U310|SCH-U320|SCH-U350|SCH-U360|SCH-U365|SCH-U370|SCH-U380|SCH-U410|SCH-U430|SCH-U450|SCH-U460|SCH-U470|SCH-U490|SCH-U540|SCH-U550|SCH-U620|SCH-U640|SCH-U650|SCH-U660|SCH-U700|SCH-U740|SCH-U750|SCH-U810|SCH-U820|SCH-U900|SCH-U940|SCH-U960|SCS-26UC|SGH-A107|SGH-A117|SGH-A127|SGH-A137|SGH-A157|SGH-A167|SGH-A177|SGH-A187|SGH-A197|SGH-A227|SGH-A237|SGH-A257|SGH-A437|SGH-A517|SGH-A597|SGH-A637|SGH-A657|SGH-A667|SGH-A687|SGH-A697|SGH-A707|SGH-A717|SGH-A727|SGH-A737|SGH-A747|SGH-A767|SGH-A777|SGH-A797|SGH-A817|SGH-A827|SGH-A837|SGH-A847|SGH-A867|SGH-A877|SGH-A887|SGH-A897|SGH-A927|SGH-B100|SGH-B130|SGH-B200|SGH-B220|SGH-C100|SGH-C110|SGH-C120|SGH-C130|SGH-C140|SGH-C160|SGH-C170|SGH-C180|SGH-C200|SGH-C207|SGH-C210|SGH-C225|SGH-C230|SGH-C417|SGH-C450|SGH-D307|SGH-D347|SGH-D357|SGH-D407|SGH-D415|SGH-D780|SGH-D807|SGH-D980|SGH-E105|SGH-E200|SGH-E315|SGH-E316|SGH-E317|SGH-E335|SGH-E590|SGH-E635|SGH-E715|SGH-E890|SGH-F300|SGH-F480|SGH-I200|SGH-I300|SGH-I320|SGH-I550|SGH-I577|SGH-I600|SGH-I607|SGH-I617|SGH-I627|SGH-I637|SGH-I677|SGH-I700|SGH-I717|SGH-I727|SGH-i747M|SGH-I777|SGH-I780|SGH-I827|SGH-I847|SGH-I857|SGH-I896|SGH-I897|SGH-I900|SGH-I907|SGH-I917|SGH-I927|SGH-I937|SGH-I997|SGH-J150|SGH-J200|SGH-L170|SGH-L700|SGH-M110|SGH-M150|SGH-M200|SGH-N105|SGH-N500|SGH-N600|SGH-N620|SGH-N625|SGH-N700|SGH-N710|SGH-P107|SGH-P207|SGH-P300|SGH-P310|SGH-P520|SGH-P735|SGH-P777|SGH-Q105|SGH-R210|SGH-R220|SGH-R225|SGH-S105|SGH-S307|SGH-T109|SGH-T119|SGH-T139|SGH-T209|SGH-T219|SGH-T229|SGH-T239|SGH-T249|SGH-T259|SGH-T309|SGH-T319|SGH-T329|SGH-T339|SGH-T349|SGH-T359|SGH-T369|SGH-T379|SGH-T409|SGH-T429|SGH-T439|SGH-T459|SGH-T469|SGH-T479|SGH-T499|SGH-T509|SGH-T519|SGH-T539|SGH-T559|SGH-T589|SGH-T609|SGH-T619|SGH-T629|SGH-T639|SGH-T659|SGH-T669|SGH-T679|SGH-T709|SGH-T719|SGH-T729|SGH-T739|SGH-T746|SGH-T749|SGH-T759|SGH-T769|SGH-T809|SGH-T819|SGH-T839|SGH-T919|SGH-T929|SGH-T939|SGH-T959|SGH-T989|SGH-U100|SGH-U200|SGH-U800|SGH-V205|SGH-V206|SGH-X100|SGH-X105|SGH-X120|SGH-X140|SGH-X426|SGH-X427|SGH-X475|SGH-X495|SGH-X497|SGH-X507|SGH-X600|SGH-X610|SGH-X620|SGH-X630|SGH-X700|SGH-X820|SGH-X890|SGH-Z130|SGH-Z150|SGH-Z170|SGH-ZX10|SGH-ZX20|SHW-M110|SPH-A120|SPH-A400|SPH-A420|SPH-A460|SPH-A500|SPH-A560|SPH-A600|SPH-A620|SPH-A660|SPH-A700|SPH-A740|SPH-A760|SPH-A790|SPH-A800|SPH-A820|SPH-A840|SPH-A880|SPH-A900|SPH-A940|SPH-A960|SPH-D600|SPH-D700|SPH-D710|SPH-D720|SPH-I300|SPH-I325|SPH-I330|SPH-I350|SPH-I500|SPH-I600|SPH-I700|SPH-L700|SPH-M100|SPH-M220|SPH-M240|SPH-M300|SPH-M305|SPH-M320|SPH-M330|SPH-M350|SPH-M360|SPH-M370|SPH-M380|SPH-M510|SPH-M540|SPH-M550|SPH-M560|SPH-M570|SPH-M580|SPH-M610|SPH-M620|SPH-M630|SPH-M800|SPH-M810|SPH-M850|SPH-M900|SPH-M910|SPH-M920|SPH-M930|SPH-N100|SPH-N200|SPH-N240|SPH-N300|SPH-N400|SPH-Z400|SWC-E100|SCH-i909|GT-N7100|GT-N7105|SCH-I535|SM-N900A|SGH-I317|SGH-T999L|GT-S5360B|GT-I8262|GT-S6802|GT-S6312|GT-S6310|GT-S5312|GT-S5310|GT-I9105|GT-I8510|GT-S6790N|SM-G7105|SM-N9005|GT-S5301|GT-I9295|GT-I9195|SM-C101|GT-S7392|GT-S7560|GT-B7610|GT-I5510|GT-S7582|GT-S7530E|GT-I8750|SM-G9006V|SM-G9008V|SM-G9009D|SM-G900A|SM-G900D|SM-G900F|SM-G900H|SM-G900I|SM-G900J|SM-G900K|SM-G900L|SM-G900M|SM-G900P|SM-G900R4|SM-G900S|SM-G900T|SM-G900V|SM-G900W8|SHV-E160K|SCH-P709|SCH-P729|SM-T2558|GT-I9205|SM-G9350|SM-J120F|SM-G920F|SM-G920V|SM-G930F|SM-N910C|SM-A310F|GT-I9190|SM-J500FN|SM-G903F|SM-J330F|SM-G610F|SM-G981B|SM-G892A|SM-A530F",LG:"\\bLG\\b;|LG[- ]?(C800|C900|E400|E610|E900|E-900|F160|F180K|F180L|F180S|730|855|L160|LS740|LS840|LS970|LU6200|MS690|MS695|MS770|MS840|MS870|MS910|P500|P700|P705|VM696|AS680|AS695|AX840|C729|E970|GS505|272|C395|E739BK|E960|L55C|L75C|LS696|LS860|P769BK|P350|P500|P509|P870|UN272|US730|VS840|VS950|LN272|LN510|LS670|LS855|LW690|MN270|MN510|P509|P769|P930|UN200|UN270|UN510|UN610|US670|US740|US760|UX265|UX840|VN271|VN530|VS660|VS700|VS740|VS750|VS910|VS920|VS930|VX9200|VX11000|AX840A|LW770|P506|P925|P999|E612|D955|D802|MS323|M257)|LM-G710",Sony:"SonyST|SonyLT|SonyEricsson|SonyEricssonLT15iv|LT18i|E10i|LT28h|LT26w|SonyEricssonMT27i|C5303|C6902|C6903|C6906|C6943|D2533|SOV34|601SO|F8332",Asus:"Asus.*Galaxy|PadFone.*Mobile",Xiaomi:"^(?!.*\\bx11\\b).*xiaomi.*$|POCOPHONE F1|MI 8|Redmi Note 9S|Redmi Note 5A Prime|N2G47H|M2001J2G|M2001J2I|M1805E10A|M2004J11G|M1902F1G|M2002J9G|M2004J19G|M2003J6A1G",NokiaLumia:"Lumia [0-9]{3,4}",Micromax:"Micromax.*\\b(A210|A92|A88|A72|A111|A110Q|A115|A116|A110|A90S|A26|A51|A35|A54|A25|A27|A89|A68|A65|A57|A90)\\b",Palm:"PalmSource|Palm",Vertu:"Vertu|Vertu.*Ltd|Vertu.*Ascent|Vertu.*Ayxta|Vertu.*Constellation(F|Quest)?|Vertu.*Monika|Vertu.*Signature",Pantech:"PANTECH|IM-A850S|IM-A840S|IM-A830L|IM-A830K|IM-A830S|IM-A820L|IM-A810K|IM-A810S|IM-A800S|IM-T100K|IM-A725L|IM-A780L|IM-A775C|IM-A770K|IM-A760S|IM-A750K|IM-A740S|IM-A730S|IM-A720L|IM-A710K|IM-A690L|IM-A690S|IM-A650S|IM-A630K|IM-A600S|VEGA PTL21|PT003|P8010|ADR910L|P6030|P6020|P9070|P4100|P9060|P5000|CDM8992|TXT8045|ADR8995|IS11PT|P2030|P6010|P8000|PT002|IS06|CDM8999|P9050|PT001|TXT8040|P2020|P9020|P2000|P7040|P7000|C790",Fly:"IQ230|IQ444|IQ450|IQ440|IQ442|IQ441|IQ245|IQ256|IQ236|IQ255|IQ235|IQ245|IQ275|IQ240|IQ285|IQ280|IQ270|IQ260|IQ250",Wiko:"KITE 4G|HIGHWAY|GETAWAY|STAIRWAY|DARKSIDE|DARKFULL|DARKNIGHT|DARKMOON|SLIDE|WAX 4G|RAINBOW|BLOOM|SUNSET|GOA(?!nna)|LENNY|BARRY|IGGY|OZZY|CINK FIVE|CINK PEAX|CINK PEAX 2|CINK SLIM|CINK SLIM 2|CINK +|CINK KING|CINK PEAX|CINK SLIM|SUBLIM",iMobile:"i-mobile (IQ|i-STYLE|idea|ZAA|Hitz)",SimValley:"\\b(SP-80|XT-930|SX-340|XT-930|SX-310|SP-360|SP60|SPT-800|SP-120|SPT-800|SP-140|SPX-5|SPX-8|SP-100|SPX-8|SPX-12)\\b",Wolfgang:"AT-B24D|AT-AS50HD|AT-AS40W|AT-AS55HD|AT-AS45q2|AT-B26D|AT-AS50Q",Alcatel:"Alcatel",Nintendo:"Nintendo (3DS|Switch)",Amoi:"Amoi",INQ:"INQ",OnePlus:"ONEPLUS",GenericPhone:"Tapatalk|PDA;|SAGEM|\\bmmp\\b|pocket|\\bpsp\\b|symbian|Smartphone|smartfon|treo|up.browser|up.link|vodafone|\\bwap\\b|nokia|Series40|Series60|S60|SonyEricsson|N900|MAUI.*WAP.*Browser"},tablets:{iPad:"iPad|iPad.*Mobile",NexusTablet:"Android.*Nexus[\\s]+(7|9|10)",GoogleTablet:"Android.*Pixel C",SamsungTablet:"SAMSUNG.*Tablet|Galaxy.*Tab|SC-01C|GT-P1000|GT-P1003|GT-P1010|GT-P3105|GT-P6210|GT-P6800|GT-P6810|GT-P7100|GT-P7300|GT-P7310|GT-P7500|GT-P7510|SCH-I800|SCH-I815|SCH-I905|SGH-I957|SGH-I987|SGH-T849|SGH-T859|SGH-T869|SPH-P100|GT-P3100|GT-P3108|GT-P3110|GT-P5100|GT-P5110|GT-P6200|GT-P7320|GT-P7511|GT-N8000|GT-P8510|SGH-I497|SPH-P500|SGH-T779|SCH-I705|SCH-I915|GT-N8013|GT-P3113|GT-P5113|GT-P8110|GT-N8010|GT-N8005|GT-N8020|GT-P1013|GT-P6201|GT-P7501|GT-N5100|GT-N5105|GT-N5110|SHV-E140K|SHV-E140L|SHV-E140S|SHV-E150S|SHV-E230K|SHV-E230L|SHV-E230S|SHW-M180K|SHW-M180L|SHW-M180S|SHW-M180W|SHW-M300W|SHW-M305W|SHW-M380K|SHW-M380S|SHW-M380W|SHW-M430W|SHW-M480K|SHW-M480S|SHW-M480W|SHW-M485W|SHW-M486W|SHW-M500W|GT-I9228|SCH-P739|SCH-I925|GT-I9200|GT-P5200|GT-P5210|GT-P5210X|SM-T311|SM-T310|SM-T310X|SM-T210|SM-T210R|SM-T211|SM-P600|SM-P601|SM-P605|SM-P900|SM-P901|SM-T217|SM-T217A|SM-T217S|SM-P6000|SM-T3100|SGH-I467|XE500|SM-T110|GT-P5220|GT-I9200X|GT-N5110X|GT-N5120|SM-P905|SM-T111|SM-T2105|SM-T315|SM-T320|SM-T320X|SM-T321|SM-T520|SM-T525|SM-T530NU|SM-T230NU|SM-T330NU|SM-T900|XE500T1C|SM-P605V|SM-P905V|SM-T337V|SM-T537V|SM-T707V|SM-T807V|SM-P600X|SM-P900X|SM-T210X|SM-T230|SM-T230X|SM-T325|GT-P7503|SM-T531|SM-T330|SM-T530|SM-T705|SM-T705C|SM-T535|SM-T331|SM-T800|SM-T700|SM-T537|SM-T807|SM-P907A|SM-T337A|SM-T537A|SM-T707A|SM-T807A|SM-T237|SM-T807P|SM-P607T|SM-T217T|SM-T337T|SM-T807T|SM-T116NQ|SM-T116BU|SM-P550|SM-T350|SM-T550|SM-T9000|SM-P9000|SM-T705Y|SM-T805|GT-P3113|SM-T710|SM-T810|SM-T815|SM-T360|SM-T533|SM-T113|SM-T335|SM-T715|SM-T560|SM-T670|SM-T677|SM-T377|SM-T567|SM-T357T|SM-T555|SM-T561|SM-T713|SM-T719|SM-T813|SM-T819|SM-T580|SM-T355Y?|SM-T280|SM-T817A|SM-T820|SM-W700|SM-P580|SM-T587|SM-P350|SM-P555M|SM-P355M|SM-T113NU|SM-T815Y|SM-T585|SM-T285|SM-T825|SM-W708|SM-T835|SM-T830|SM-T837V|SM-T720|SM-T510|SM-T387V|SM-P610|SM-T290|SM-T515|SM-T590|SM-T595|SM-T725|SM-T817P|SM-P585N0|SM-T395|SM-T295|SM-T865|SM-P610N|SM-P615|SM-T970|SM-T380|SM-T5950|SM-T905|SM-T231|SM-T500|SM-T860",Kindle:"Kindle|Silk.*Accelerated|Android.*\\b(KFOT|KFTT|KFJWI|KFJWA|KFOTE|KFSOWI|KFTHWI|KFTHWA|KFAPWI|KFAPWA|WFJWAE|KFSAWA|KFSAWI|KFASWI|KFARWI|KFFOWI|KFGIWI|KFMEWI)\\b|Android.*Silk/[0-9.]+ like Chrome/[0-9.]+ (?!Mobile)",SurfaceTablet:"Windows NT [0-9.]+; ARM;.*(Tablet|ARMBJS)",HPTablet:"HP Slate (7|8|10)|HP ElitePad 900|hp-tablet|EliteBook.*Touch|HP 8|Slate 21|HP SlateBook 10",AsusTablet:"^.*PadFone((?!Mobile).)*$|Transformer|TF101|TF101G|TF300T|TF300TG|TF300TL|TF700T|TF700KL|TF701T|TF810C|ME171|ME301T|ME302C|ME371MG|ME370T|ME372MG|ME172V|ME173X|ME400C|Slider SL101|\\bK00F\\b|\\bK00C\\b|\\bK00E\\b|\\bK00L\\b|TX201LA|ME176C|ME102A|\\bM80TA\\b|ME372CL|ME560CG|ME372CG|ME302KL| K010 | K011 | K017 | K01E |ME572C|ME103K|ME170C|ME171C|\\bME70C\\b|ME581C|ME581CL|ME8510C|ME181C|P01Y|PO1MA|P01Z|\\bP027\\b|\\bP024\\b|\\bP00C\\b",BlackBerryTablet:"PlayBook|RIM Tablet",HTCtablet:"HTC_Flyer_P512|HTC Flyer|HTC Jetstream|HTC-P715a|HTC EVO View 4G|PG41200|PG09410",MotorolaTablet:"xoom|sholest|MZ615|MZ605|MZ505|MZ601|MZ602|MZ603|MZ604|MZ606|MZ607|MZ608|MZ609|MZ615|MZ616|MZ617",NookTablet:"Android.*Nook|NookColor|nook browser|BNRV200|BNRV200A|BNTV250|BNTV250A|BNTV400|BNTV600|LogicPD Zoom2",AcerTablet:"Android.*; \\b(A100|A101|A110|A200|A210|A211|A500|A501|A510|A511|A700|A701|W500|W500P|W501|W501P|W510|W511|W700|G100|G100W|B1-A71|B1-710|B1-711|A1-810|A1-811|A1-830)\\b|W3-810|\\bA3-A10\\b|\\bA3-A11\\b|\\bA3-A20\\b|\\bA3-A30|A3-A40",ToshibaTablet:"Android.*(AT100|AT105|AT200|AT205|AT270|AT275|AT300|AT305|AT1S5|AT500|AT570|AT700|AT830)|TOSHIBA.*FOLIO",LGTablet:"\\bL-06C|LG-V909|LG-V900|LG-V700|LG-V510|LG-V500|LG-V410|LG-V400|LG-VK810\\b",FujitsuTablet:"Android.*\\b(F-01D|F-02F|F-05E|F-10D|M532|Q572)\\b",PrestigioTablet:"PMP3170B|PMP3270B|PMP3470B|PMP7170B|PMP3370B|PMP3570C|PMP5870C|PMP3670B|PMP5570C|PMP5770D|PMP3970B|PMP3870C|PMP5580C|PMP5880D|PMP5780D|PMP5588C|PMP7280C|PMP7280C3G|PMP7280|PMP7880D|PMP5597D|PMP5597|PMP7100D|PER3464|PER3274|PER3574|PER3884|PER5274|PER5474|PMP5097CPRO|PMP5097|PMP7380D|PMP5297C|PMP5297C_QUAD|PMP812E|PMP812E3G|PMP812F|PMP810E|PMP880TD|PMT3017|PMT3037|PMT3047|PMT3057|PMT7008|PMT5887|PMT5001|PMT5002",LenovoTablet:"Lenovo TAB|Idea(Tab|Pad)( A1|A10| K1|)|ThinkPad([ ]+)?Tablet|YT3-850M|YT3-X90L|YT3-X90F|YT3-X90X|Lenovo.*(S2109|S2110|S5000|S6000|K3011|A3000|A3500|A1000|A2107|A2109|A1107|A5500|A7600|B6000|B8000|B8080)(-|)(FL|F|HV|H|)|TB-X103F|TB-X304X|TB-X304F|TB-X304L|TB-X505F|TB-X505L|TB-X505X|TB-X605F|TB-X605L|TB-8703F|TB-8703X|TB-8703N|TB-8704N|TB-8704F|TB-8704X|TB-8704V|TB-7304F|TB-7304I|TB-7304X|Tab2A7-10F|Tab2A7-20F|TB2-X30L|YT3-X50L|YT3-X50F|YT3-X50M|YT-X705F|YT-X703F|YT-X703L|YT-X705L|YT-X705X|TB2-X30F|TB2-X30L|TB2-X30M|A2107A-F|A2107A-H|TB3-730F|TB3-730M|TB3-730X|TB-7504F|TB-7504X|TB-X704F|TB-X104F|TB3-X70F|TB-X705F|TB-8504F|TB3-X70L|TB3-710F|TB-X704L",DellTablet:"Venue 11|Venue 8|Venue 7|Dell Streak 10|Dell Streak 7",YarvikTablet:"Android.*\\b(TAB210|TAB211|TAB224|TAB250|TAB260|TAB264|TAB310|TAB360|TAB364|TAB410|TAB411|TAB420|TAB424|TAB450|TAB460|TAB461|TAB464|TAB465|TAB467|TAB468|TAB07-100|TAB07-101|TAB07-150|TAB07-151|TAB07-152|TAB07-200|TAB07-201-3G|TAB07-210|TAB07-211|TAB07-212|TAB07-214|TAB07-220|TAB07-400|TAB07-485|TAB08-150|TAB08-200|TAB08-201-3G|TAB08-201-30|TAB09-100|TAB09-211|TAB09-410|TAB10-150|TAB10-201|TAB10-211|TAB10-400|TAB10-410|TAB13-201|TAB274EUK|TAB275EUK|TAB374EUK|TAB462EUK|TAB474EUK|TAB9-200)\\b",MedionTablet:"Android.*\\bOYO\\b|LIFE.*(P9212|P9514|P9516|S9512)|LIFETAB",ArnovaTablet:"97G4|AN10G2|AN7bG3|AN7fG3|AN8G3|AN8cG3|AN7G3|AN9G3|AN7dG3|AN7dG3ST|AN7dG3ChildPad|AN10bG3|AN10bG3DT|AN9G2",IntensoTablet:"INM8002KP|INM1010FP|INM805ND|Intenso Tab|TAB1004",IRUTablet:"M702pro",MegafonTablet:"MegaFon V9|\\bZTE V9\\b|Android.*\\bMT7A\\b",EbodaTablet:"E-Boda (Supreme|Impresspeed|Izzycomm|Essential)",AllViewTablet:"Allview.*(Viva|Alldro|City|Speed|All TV|Frenzy|Quasar|Shine|TX1|AX1|AX2)",ArchosTablet:"\\b(101G9|80G9|A101IT)\\b|Qilive 97R|Archos5|\\bARCHOS (70|79|80|90|97|101|FAMILYPAD|)(b|c|)(G10| Cobalt| TITANIUM(HD|)| Xenon| Neon|XSK| 2| XS 2| PLATINUM| CARBON|GAMEPAD)\\b",AinolTablet:"NOVO7|NOVO8|NOVO10|Novo7Aurora|Novo7Basic|NOVO7PALADIN|novo9-Spark",NokiaLumiaTablet:"Lumia 2520",SonyTablet:"Sony.*Tablet|Xperia Tablet|Sony Tablet S|SO-03E|SGPT12|SGPT13|SGPT114|SGPT121|SGPT122|SGPT123|SGPT111|SGPT112|SGPT113|SGPT131|SGPT132|SGPT133|SGPT211|SGPT212|SGPT213|SGP311|SGP312|SGP321|EBRD1101|EBRD1102|EBRD1201|SGP351|SGP341|SGP511|SGP512|SGP521|SGP541|SGP551|SGP621|SGP641|SGP612|SOT31|SGP771|SGP611|SGP612|SGP712",PhilipsTablet:"\\b(PI2010|PI3000|PI3100|PI3105|PI3110|PI3205|PI3210|PI3900|PI4010|PI7000|PI7100)\\b",CubeTablet:"Android.*(K8GT|U9GT|U10GT|U16GT|U17GT|U18GT|U19GT|U20GT|U23GT|U30GT)|CUBE U8GT",CobyTablet:"MID1042|MID1045|MID1125|MID1126|MID7012|MID7014|MID7015|MID7034|MID7035|MID7036|MID7042|MID7048|MID7127|MID8042|MID8048|MID8127|MID9042|MID9740|MID9742|MID7022|MID7010",MIDTablet:"M9701|M9000|M9100|M806|M1052|M806|T703|MID701|MID713|MID710|MID727|MID760|MID830|MID728|MID933|MID125|MID810|MID732|MID120|MID930|MID800|MID731|MID900|MID100|MID820|MID735|MID980|MID130|MID833|MID737|MID960|MID135|MID860|MID736|MID140|MID930|MID835|MID733|MID4X10",MSITablet:"MSI \\b(Primo 73K|Primo 73L|Primo 81L|Primo 77|Primo 93|Primo 75|Primo 76|Primo 73|Primo 81|Primo 91|Primo 90|Enjoy 71|Enjoy 7|Enjoy 10)\\b",SMiTTablet:"Android.*(\\bMID\\b|MID-560|MTV-T1200|MTV-PND531|MTV-P1101|MTV-PND530)",RockChipTablet:"Android.*(RK2818|RK2808A|RK2918|RK3066)|RK2738|RK2808A",FlyTablet:"IQ310|Fly Vision",bqTablet:"Android.*(bq)?.*\\b(Elcano|Curie|Edison|Maxwell|Kepler|Pascal|Tesla|Hypatia|Platon|Newton|Livingstone|Cervantes|Avant|Aquaris ([E|M]10|M8))\\b|Maxwell.*Lite|Maxwell.*Plus",HuaweiTablet:"MediaPad|MediaPad 7 Youth|IDEOS S7|S7-201c|S7-202u|S7-101|S7-103|S7-104|S7-105|S7-106|S7-201|S7-Slim|M2-A01L|BAH-L09|BAH-W09|AGS-L09|CMR-AL19",NecTablet:"\\bN-06D|\\bN-08D",PantechTablet:"Pantech.*P4100",BronchoTablet:"Broncho.*(N701|N708|N802|a710)",VersusTablet:"TOUCHPAD.*[78910]|\\bTOUCHTAB\\b",ZyncTablet:"z1000|Z99 2G|z930|z990|z909|Z919|z900",PositivoTablet:"TB07STA|TB10STA|TB07FTA|TB10FTA",NabiTablet:"Android.*\\bNabi",KoboTablet:"Kobo Touch|\\bK080\\b|\\bVox\\b Build|\\bArc\\b Build",DanewTablet:"DSlide.*\\b(700|701R|702|703R|704|802|970|971|972|973|974|1010|1012)\\b",TexetTablet:"NaviPad|TB-772A|TM-7045|TM-7055|TM-9750|TM-7016|TM-7024|TM-7026|TM-7041|TM-7043|TM-7047|TM-8041|TM-9741|TM-9747|TM-9748|TM-9751|TM-7022|TM-7021|TM-7020|TM-7011|TM-7010|TM-7023|TM-7025|TM-7037W|TM-7038W|TM-7027W|TM-9720|TM-9725|TM-9737W|TM-1020|TM-9738W|TM-9740|TM-9743W|TB-807A|TB-771A|TB-727A|TB-725A|TB-719A|TB-823A|TB-805A|TB-723A|TB-715A|TB-707A|TB-705A|TB-709A|TB-711A|TB-890HD|TB-880HD|TB-790HD|TB-780HD|TB-770HD|TB-721HD|TB-710HD|TB-434HD|TB-860HD|TB-840HD|TB-760HD|TB-750HD|TB-740HD|TB-730HD|TB-722HD|TB-720HD|TB-700HD|TB-500HD|TB-470HD|TB-431HD|TB-430HD|TB-506|TB-504|TB-446|TB-436|TB-416|TB-146SE|TB-126SE",PlaystationTablet:"Playstation.*(Portable|Vita)",TrekstorTablet:"ST10416-1|VT10416-1|ST70408-1|ST702xx-1|ST702xx-2|ST80208|ST97216|ST70104-2|VT10416-2|ST10216-2A|SurfTab",PyleAudioTablet:"\\b(PTBL10CEU|PTBL10C|PTBL72BC|PTBL72BCEU|PTBL7CEU|PTBL7C|PTBL92BC|PTBL92BCEU|PTBL9CEU|PTBL9CUK|PTBL9C)\\b",AdvanTablet:"Android.* \\b(E3A|T3X|T5C|T5B|T3E|T3C|T3B|T1J|T1F|T2A|T1H|T1i|E1C|T1-E|T5-A|T4|E1-B|T2Ci|T1-B|T1-D|O1-A|E1-A|T1-A|T3A|T4i)\\b ",DanyTechTablet:"Genius Tab G3|Genius Tab S2|Genius Tab Q3|Genius Tab G4|Genius Tab Q4|Genius Tab G-II|Genius TAB GII|Genius TAB GIII|Genius Tab S1",GalapadTablet:"Android [0-9.]+; [a-z-]+; \\bG1\\b",MicromaxTablet:"Funbook|Micromax.*\\b(P250|P560|P360|P362|P600|P300|P350|P500|P275)\\b",KarbonnTablet:"Android.*\\b(A39|A37|A34|ST8|ST10|ST7|Smart Tab3|Smart Tab2)\\b",AllFineTablet:"Fine7 Genius|Fine7 Shine|Fine7 Air|Fine8 Style|Fine9 More|Fine10 Joy|Fine11 Wide",PROSCANTablet:"\\b(PEM63|PLT1023G|PLT1041|PLT1044|PLT1044G|PLT1091|PLT4311|PLT4311PL|PLT4315|PLT7030|PLT7033|PLT7033D|PLT7035|PLT7035D|PLT7044K|PLT7045K|PLT7045KB|PLT7071KG|PLT7072|PLT7223G|PLT7225G|PLT7777G|PLT7810K|PLT7849G|PLT7851G|PLT7852G|PLT8015|PLT8031|PLT8034|PLT8036|PLT8080K|PLT8082|PLT8088|PLT8223G|PLT8234G|PLT8235G|PLT8816K|PLT9011|PLT9045K|PLT9233G|PLT9735|PLT9760G|PLT9770G)\\b",YONESTablet:"BQ1078|BC1003|BC1077|RK9702|BC9730|BC9001|IT9001|BC7008|BC7010|BC708|BC728|BC7012|BC7030|BC7027|BC7026",ChangJiaTablet:"TPC7102|TPC7103|TPC7105|TPC7106|TPC7107|TPC7201|TPC7203|TPC7205|TPC7210|TPC7708|TPC7709|TPC7712|TPC7110|TPC8101|TPC8103|TPC8105|TPC8106|TPC8203|TPC8205|TPC8503|TPC9106|TPC9701|TPC97101|TPC97103|TPC97105|TPC97106|TPC97111|TPC97113|TPC97203|TPC97603|TPC97809|TPC97205|TPC10101|TPC10103|TPC10106|TPC10111|TPC10203|TPC10205|TPC10503",GUTablet:"TX-A1301|TX-M9002|Q702|kf026",PointOfViewTablet:"TAB-P506|TAB-navi-7-3G-M|TAB-P517|TAB-P-527|TAB-P701|TAB-P703|TAB-P721|TAB-P731N|TAB-P741|TAB-P825|TAB-P905|TAB-P925|TAB-PR945|TAB-PL1015|TAB-P1025|TAB-PI1045|TAB-P1325|TAB-PROTAB[0-9]+|TAB-PROTAB25|TAB-PROTAB26|TAB-PROTAB27|TAB-PROTAB26XL|TAB-PROTAB2-IPS9|TAB-PROTAB30-IPS9|TAB-PROTAB25XXL|TAB-PROTAB26-IPS10|TAB-PROTAB30-IPS10",OvermaxTablet:"OV-(SteelCore|NewBase|Basecore|Baseone|Exellen|Quattor|EduTab|Solution|ACTION|BasicTab|TeddyTab|MagicTab|Stream|TB-08|TB-09)|Qualcore 1027",HCLTablet:"HCL.*Tablet|Connect-3G-2.0|Connect-2G-2.0|ME Tablet U1|ME Tablet U2|ME Tablet G1|ME Tablet X1|ME Tablet Y2|ME Tablet Sync",DPSTablet:"DPS Dream 9|DPS Dual 7",VistureTablet:"V97 HD|i75 3G|Visture V4( HD)?|Visture V5( HD)?|Visture V10",CrestaTablet:"CTP(-)?810|CTP(-)?818|CTP(-)?828|CTP(-)?838|CTP(-)?888|CTP(-)?978|CTP(-)?980|CTP(-)?987|CTP(-)?988|CTP(-)?989",MediatekTablet:"\\bMT8125|MT8389|MT8135|MT8377\\b",ConcordeTablet:"Concorde([ ]+)?Tab|ConCorde ReadMan",GoCleverTablet:"GOCLEVER TAB|A7GOCLEVER|M1042|M7841|M742|R1042BK|R1041|TAB A975|TAB A7842|TAB A741|TAB A741L|TAB M723G|TAB M721|TAB A1021|TAB I921|TAB R721|TAB I720|TAB T76|TAB R70|TAB R76.2|TAB R106|TAB R83.2|TAB M813G|TAB I721|GCTA722|TAB I70|TAB I71|TAB S73|TAB R73|TAB R74|TAB R93|TAB R75|TAB R76.1|TAB A73|TAB A93|TAB A93.2|TAB T72|TAB R83|TAB R974|TAB R973|TAB A101|TAB A103|TAB A104|TAB A104.2|R105BK|M713G|A972BK|TAB A971|TAB R974.2|TAB R104|TAB R83.3|TAB A1042",ModecomTablet:"FreeTAB 9000|FreeTAB 7.4|FreeTAB 7004|FreeTAB 7800|FreeTAB 2096|FreeTAB 7.5|FreeTAB 1014|FreeTAB 1001 |FreeTAB 8001|FreeTAB 9706|FreeTAB 9702|FreeTAB 7003|FreeTAB 7002|FreeTAB 1002|FreeTAB 7801|FreeTAB 1331|FreeTAB 1004|FreeTAB 8002|FreeTAB 8014|FreeTAB 9704|FreeTAB 1003",VoninoTablet:"\\b(Argus[ _]?S|Diamond[ _]?79HD|Emerald[ _]?78E|Luna[ _]?70C|Onyx[ _]?S|Onyx[ _]?Z|Orin[ _]?HD|Orin[ _]?S|Otis[ _]?S|SpeedStar[ _]?S|Magnet[ _]?M9|Primus[ _]?94[ _]?3G|Primus[ _]?94HD|Primus[ _]?QS|Android.*\\bQ8\\b|Sirius[ _]?EVO[ _]?QS|Sirius[ _]?QS|Spirit[ _]?S)\\b",ECSTablet:"V07OT2|TM105A|S10OT1|TR10CS1",StorexTablet:"eZee[_']?(Tab|Go)[0-9]+|TabLC7|Looney Tunes Tab",VodafoneTablet:"SmartTab([ ]+)?[0-9]+|SmartTabII10|SmartTabII7|VF-1497|VFD 1400",EssentielBTablet:"Smart[ ']?TAB[ ]+?[0-9]+|Family[ ']?TAB2",RossMoorTablet:"RM-790|RM-997|RMD-878G|RMD-974R|RMT-705A|RMT-701|RME-601|RMT-501|RMT-711",iMobileTablet:"i-mobile i-note",TolinoTablet:"tolino tab [0-9.]+|tolino shine",AudioSonicTablet:"\\bC-22Q|T7-QC|T-17B|T-17P\\b",AMPETablet:"Android.* A78 ",SkkTablet:"Android.* (SKYPAD|PHOENIX|CYCLOPS)",TecnoTablet:"TECNO P9|TECNO DP8D",JXDTablet:"Android.* \\b(F3000|A3300|JXD5000|JXD3000|JXD2000|JXD300B|JXD300|S5800|S7800|S602b|S5110b|S7300|S5300|S602|S603|S5100|S5110|S601|S7100a|P3000F|P3000s|P101|P200s|P1000m|P200m|P9100|P1000s|S6600b|S908|P1000|P300|S18|S6600|S9100)\\b",iJoyTablet:"Tablet (Spirit 7|Essentia|Galatea|Fusion|Onix 7|Landa|Titan|Scooby|Deox|Stella|Themis|Argon|Unique 7|Sygnus|Hexen|Finity 7|Cream|Cream X2|Jade|Neon 7|Neron 7|Kandy|Scape|Saphyr 7|Rebel|Biox|Rebel|Rebel 8GB|Myst|Draco 7|Myst|Tab7-004|Myst|Tadeo Jones|Tablet Boing|Arrow|Draco Dual Cam|Aurix|Mint|Amity|Revolution|Finity 9|Neon 9|T9w|Amity 4GB Dual Cam|Stone 4GB|Stone 8GB|Andromeda|Silken|X2|Andromeda II|Halley|Flame|Saphyr 9,7|Touch 8|Planet|Triton|Unique 10|Hexen 10|Memphis 4GB|Memphis 8GB|Onix 10)",FX2Tablet:"FX2 PAD7|FX2 PAD10",XoroTablet:"KidsPAD 701|PAD[ ]?712|PAD[ ]?714|PAD[ ]?716|PAD[ ]?717|PAD[ ]?718|PAD[ ]?720|PAD[ ]?721|PAD[ ]?722|PAD[ ]?790|PAD[ ]?792|PAD[ ]?900|PAD[ ]?9715D|PAD[ ]?9716DR|PAD[ ]?9718DR|PAD[ ]?9719QR|PAD[ ]?9720QR|TelePAD1030|Telepad1032|TelePAD730|TelePAD731|TelePAD732|TelePAD735Q|TelePAD830|TelePAD9730|TelePAD795|MegaPAD 1331|MegaPAD 1851|MegaPAD 2151",ViewsonicTablet:"ViewPad 10pi|ViewPad 10e|ViewPad 10s|ViewPad E72|ViewPad7|ViewPad E100|ViewPad 7e|ViewSonic VB733|VB100a",VerizonTablet:"QTAQZ3|QTAIR7|QTAQTZ3|QTASUN1|QTASUN2|QTAXIA1",OdysTablet:"LOOX|XENO10|ODYS[ -](Space|EVO|Xpress|NOON)|\\bXELIO\\b|Xelio10Pro|XELIO7PHONETAB|XELIO10EXTREME|XELIOPT2|NEO_QUAD10",CaptivaTablet:"CAPTIVA PAD",IconbitTablet:"NetTAB|NT-3702|NT-3702S|NT-3702S|NT-3603P|NT-3603P|NT-0704S|NT-0704S|NT-3805C|NT-3805C|NT-0806C|NT-0806C|NT-0909T|NT-0909T|NT-0907S|NT-0907S|NT-0902S|NT-0902S",TeclastTablet:"T98 4G|\\bP80\\b|\\bX90HD\\b|X98 Air|X98 Air 3G|\\bX89\\b|P80 3G|\\bX80h\\b|P98 Air|\\bX89HD\\b|P98 3G|\\bP90HD\\b|P89 3G|X98 3G|\\bP70h\\b|P79HD 3G|G18d 3G|\\bP79HD\\b|\\bP89s\\b|\\bA88\\b|\\bP10HD\\b|\\bP19HD\\b|G18 3G|\\bP78HD\\b|\\bA78\\b|\\bP75\\b|G17s 3G|G17h 3G|\\bP85t\\b|\\bP90\\b|\\bP11\\b|\\bP98t\\b|\\bP98HD\\b|\\bG18d\\b|\\bP85s\\b|\\bP11HD\\b|\\bP88s\\b|\\bA80HD\\b|\\bA80se\\b|\\bA10h\\b|\\bP89\\b|\\bP78s\\b|\\bG18\\b|\\bP85\\b|\\bA70h\\b|\\bA70\\b|\\bG17\\b|\\bP18\\b|\\bA80s\\b|\\bA11s\\b|\\bP88HD\\b|\\bA80h\\b|\\bP76s\\b|\\bP76h\\b|\\bP98\\b|\\bA10HD\\b|\\bP78\\b|\\bP88\\b|\\bA11\\b|\\bA10t\\b|\\bP76a\\b|\\bP76t\\b|\\bP76e\\b|\\bP85HD\\b|\\bP85a\\b|\\bP86\\b|\\bP75HD\\b|\\bP76v\\b|\\bA12\\b|\\bP75a\\b|\\bA15\\b|\\bP76Ti\\b|\\bP81HD\\b|\\bA10\\b|\\bT760VE\\b|\\bT720HD\\b|\\bP76\\b|\\bP73\\b|\\bP71\\b|\\bP72\\b|\\bT720SE\\b|\\bC520Ti\\b|\\bT760\\b|\\bT720VE\\b|T720-3GE|T720-WiFi",OndaTablet:"\\b(V975i|Vi30|VX530|V701|Vi60|V701s|Vi50|V801s|V719|Vx610w|VX610W|V819i|Vi10|VX580W|Vi10|V711s|V813|V811|V820w|V820|Vi20|V711|VI30W|V712|V891w|V972|V819w|V820w|Vi60|V820w|V711|V813s|V801|V819|V975s|V801|V819|V819|V818|V811|V712|V975m|V101w|V961w|V812|V818|V971|V971s|V919|V989|V116w|V102w|V973|Vi40)\\b[\\s]+|V10 \\b4G\\b",JaytechTablet:"TPC-PA762",BlaupunktTablet:"Endeavour 800NG|Endeavour 1010",DigmaTablet:"\\b(iDx10|iDx9|iDx8|iDx7|iDxD7|iDxD8|iDsQ8|iDsQ7|iDsQ8|iDsD10|iDnD7|3TS804H|iDsQ11|iDj7|iDs10)\\b",EvolioTablet:"ARIA_Mini_wifi|Aria[ _]Mini|Evolio X10|Evolio X7|Evolio X8|\\bEvotab\\b|\\bNeura\\b",LavaTablet:"QPAD E704|\\bIvoryS\\b|E-TAB IVORY|\\bE-TAB\\b",AocTablet:"MW0811|MW0812|MW0922|MTK8382|MW1031|MW0831|MW0821|MW0931|MW0712",MpmanTablet:"MP11 OCTA|MP10 OCTA|MPQC1114|MPQC1004|MPQC994|MPQC974|MPQC973|MPQC804|MPQC784|MPQC780|\\bMPG7\\b|MPDCG75|MPDCG71|MPDC1006|MP101DC|MPDC9000|MPDC905|MPDC706HD|MPDC706|MPDC705|MPDC110|MPDC100|MPDC99|MPDC97|MPDC88|MPDC8|MPDC77|MP709|MID701|MID711|MID170|MPDC703|MPQC1010",CelkonTablet:"CT695|CT888|CT[\\s]?910|CT7 Tab|CT9 Tab|CT3 Tab|CT2 Tab|CT1 Tab|C820|C720|\\bCT-1\\b",WolderTablet:"miTab \\b(DIAMOND|SPACE|BROOKLYN|NEO|FLY|MANHATTAN|FUNK|EVOLUTION|SKY|GOCAR|IRON|GENIUS|POP|MINT|EPSILON|BROADWAY|JUMP|HOP|LEGEND|NEW AGE|LINE|ADVANCE|FEEL|FOLLOW|LIKE|LINK|LIVE|THINK|FREEDOM|CHICAGO|CLEVELAND|BALTIMORE-GH|IOWA|BOSTON|SEATTLE|PHOENIX|DALLAS|IN 101|MasterChef)\\b",MediacomTablet:"M-MPI10C3G|M-SP10EG|M-SP10EGP|M-SP10HXAH|M-SP7HXAH|M-SP10HXBH|M-SP8HXAH|M-SP8MXA",MiTablet:"\\bMI PAD\\b|\\bHM NOTE 1W\\b",NibiruTablet:"Nibiru M1|Nibiru Jupiter One",NexoTablet:"NEXO NOVA|NEXO 10|NEXO AVIO|NEXO FREE|NEXO GO|NEXO EVO|NEXO 3G|NEXO SMART|NEXO KIDDO|NEXO MOBI",LeaderTablet:"TBLT10Q|TBLT10I|TBL-10WDKB|TBL-10WDKBO2013|TBL-W230V2|TBL-W450|TBL-W500|SV572|TBLT7I|TBA-AC7-8G|TBLT79|TBL-8W16|TBL-10W32|TBL-10WKB|TBL-W100",UbislateTablet:"UbiSlate[\\s]?7C",PocketBookTablet:"Pocketbook",KocasoTablet:"\\b(TB-1207)\\b",HisenseTablet:"\\b(F5281|E2371)\\b",Hudl:"Hudl HT7S3|Hudl 2",TelstraTablet:"T-Hub2",GenericTablet:"Android.*\\b97D\\b|Tablet(?!.*PC)|BNTV250A|MID-WCDMA|LogicPD Zoom2|\\bA7EB\\b|CatNova8|A1_07|CT704|CT1002|\\bM721\\b|rk30sdk|\\bEVOTAB\\b|M758A|ET904|ALUMIUM10|Smartfren Tab|Endeavour 1010|Tablet-PC-4|Tagi Tab|\\bM6pro\\b|CT1020W|arc 10HD|\\bTP750\\b|\\bQTAQZ3\\b|WVT101|TM1088|KT107"},oss:{AndroidOS:"Android",BlackBerryOS:"blackberry|\\bBB10\\b|rim tablet os",PalmOS:"PalmOS|avantgo|blazer|elaine|hiptop|palm|plucker|xiino",SymbianOS:"Symbian|SymbOS|Series60|Series40|SYB-[0-9]+|\\bS60\\b",WindowsMobileOS:"Windows CE.*(PPC|Smartphone|Mobile|[0-9]{3}x[0-9]{3})|Windows Mobile|Windows Phone [0-9.]+|WCE;",WindowsPhoneOS:"Windows Phone 10.0|Windows Phone 8.1|Windows Phone 8.0|Windows Phone OS|XBLWP7|ZuneWP7|Windows NT 6.[23]; ARM;",iOS:"\\biPhone.*Mobile|\\biPod|\\biPad|AppleCoreMedia",iPadOS:"CPU OS 13",SailfishOS:"Sailfish",MeeGoOS:"MeeGo",MaemoOS:"Maemo",JavaOS:"J2ME/|\\bMIDP\\b|\\bCLDC\\b",webOS:"webOS|hpwOS",badaOS:"\\bBada\\b",BREWOS:"BREW"},uas:{Chrome:"\\bCrMo\\b|CriOS|Android.*Chrome/[.0-9]* (Mobile)?",Dolfin:"\\bDolfin\\b",Opera:"Opera.*Mini|Opera.*Mobi|Android.*Opera|Mobile.*OPR/[0-9.]+$|Coast/[0-9.]+",Skyfire:"Skyfire",Edge:"\\bEdgiOS\\b|Mobile Safari/[.0-9]* Edge",IE:"IEMobile|MSIEMobile",Firefox:"fennec|firefox.*maemo|(Mobile|Tablet).*Firefox|Firefox.*Mobile|FxiOS",Bolt:"bolt",TeaShark:"teashark",Blazer:"Blazer",Safari:"Version((?!\\bEdgiOS\\b).)*Mobile.*Safari|Safari.*Mobile|MobileSafari",WeChat:"\\bMicroMessenger\\b",UCBrowser:"UC.*Browser|UCWEB",baiduboxapp:"baiduboxapp",baidubrowser:"baidubrowser",DiigoBrowser:"DiigoBrowser",Mercury:"\\bMercury\\b",ObigoBrowser:"Obigo",NetFront:"NF-Browser",GenericBrowser:"NokiaBrowser|OviBrowser|OneBrowser|TwonkyBeamBrowser|SEMC.*Browser|FlyFlow|Minimo|NetFront|Novarra-Vision|MQQBrowser|MicroMessenger",PaleMoon:"Android.*PaleMoon|Mobile.*PaleMoon"},props:{Mobile:"Mobile/[VER]",Build:"Build/[VER]",Version:"Version/[VER]",VendorID:"VendorID/[VER]",iPad:"iPad.*CPU[a-z ]+[VER]",iPhone:"iPhone.*CPU[a-z ]+[VER]",iPod:"iPod.*CPU[a-z ]+[VER]",Kindle:"Kindle/[VER]",Chrome:["Chrome/[VER]","CriOS/[VER]","CrMo/[VER]"],Coast:["Coast/[VER]"],Dolfin:"Dolfin/[VER]",Firefox:["Firefox/[VER]","FxiOS/[VER]"],Fennec:"Fennec/[VER]",Edge:"Edge/[VER]",IE:["IEMobile/[VER];","IEMobile [VER]","MSIE [VER];","Trident/[0-9.]+;.*rv:[VER]"],NetFront:"NetFront/[VER]",NokiaBrowser:"NokiaBrowser/[VER]",Opera:[" OPR/[VER]","Opera Mini/[VER]","Version/[VER]"],"Opera Mini":"Opera Mini/[VER]","Opera Mobi":"Version/[VER]",UCBrowser:["UCWEB[VER]","UC.*Browser/[VER]"],MQQBrowser:"MQQBrowser/[VER]",MicroMessenger:"MicroMessenger/[VER]",baiduboxapp:"baiduboxapp/[VER]",baidubrowser:"baidubrowser/[VER]",SamsungBrowser:"SamsungBrowser/[VER]",Iron:"Iron/[VER]",Safari:["Version/[VER]","Safari/[VER]"],Skyfire:"Skyfire/[VER]",Tizen:"Tizen/[VER]",Webkit:"webkit[ /][VER]",PaleMoon:"PaleMoon/[VER]",SailfishBrowser:"SailfishBrowser/[VER]",Gecko:"Gecko/[VER]",Trident:"Trident/[VER]",Presto:"Presto/[VER]",Goanna:"Goanna/[VER]",iOS:" \\bi?OS\\b [VER][ ;]{1}",Android:"Android [VER]",Sailfish:"Sailfish [VER]",BlackBerry:["BlackBerry[\\w]+/[VER]","BlackBerry.*Version/[VER]","Version/[VER]"],BREW:"BREW [VER]",Java:"Java/[VER]","Windows Phone OS":["Windows Phone OS [VER]","Windows Phone [VER]"],"Windows Phone":"Windows Phone [VER]","Windows CE":"Windows CE/[VER]","Windows NT":"Windows NT [VER]",Symbian:["SymbianOS/[VER]","Symbian/[VER]"],webOS:["webOS/[VER]","hpwOS/[VER];"]},utils:{Bot:"Googlebot|facebookexternalhit|Google-AMPHTML|s~amp-validator|AdsBot-Google|Google Keyword Suggestion|Facebot|YandexBot|YandexMobileBot|bingbot|ia_archiver|AhrefsBot|Ezooms|GSLFbot|WBSearchBot|Twitterbot|TweetmemeBot|Twikle|PaperLiBot|Wotbox|UnwindFetchor|Exabot|MJ12bot|YandexImages|TurnitinBot|Pingdom|contentkingapp|AspiegelBot",MobileBot:"Googlebot-Mobile|AdsBot-Google-Mobile|YahooSeeker/M1A1-R2D2",DesktopMode:"WPDesktop",TV:"SonyDTV|HbbTV",WebKit:"(webkit)[ /]([\\w.]+)",Console:"\\b(Nintendo|Nintendo WiiU|Nintendo 3DS|Nintendo Switch|PLAYSTATION|Xbox)\\b",Watch:"SM-V700"}},g.detectMobileBrowsers={fullPattern:/(android|bb\d+|meego).+mobile|avantgo|bada\/|blackberry|blazer|compal|elaine|fennec|hiptop|iemobile|ip(hone|od)|iris|kindle|lge |maemo|midp|mmp|mobile.+firefox|netfront|opera m(ob|in)i|palm( os)?|phone|p(ixi|re)\/|plucker|pocket|psp|series(4|6)0|symbian|treo|up\.(browser|link)|vodafone|wap|windows ce|xda|xiino/i,
shortPattern:/1207|6310|6590|3gso|4thp|50[1-6]i|770s|802s|a wa|abac|ac(er|oo|s\-)|ai(ko|rn)|al(av|ca|co)|amoi|an(ex|ny|yw)|aptu|ar(ch|go)|as(te|us)|attw|au(di|\-m|r |s )|avan|be(ck|ll|nq)|bi(lb|rd)|bl(ac|az)|br(e|v)w|bumb|bw\-(n|u)|c55\/|capi|ccwa|cdm\-|cell|chtm|cldc|cmd\-|co(mp|nd)|craw|da(it|ll|ng)|dbte|dc\-s|devi|dica|dmob|do(c|p)o|ds(12|\-d)|el(49|ai)|em(l2|ul)|er(ic|k0)|esl8|ez([4-7]0|os|wa|ze)|fetc|fly(\-|_)|g1 u|g560|gene|gf\-5|g\-mo|go(\.w|od)|gr(ad|un)|haie|hcit|hd\-(m|p|t)|hei\-|hi(pt|ta)|hp( i|ip)|hs\-c|ht(c(\-| |_|a|g|p|s|t)|tp)|hu(aw|tc)|i\-(20|go|ma)|i230|iac( |\-|\/)|ibro|idea|ig01|ikom|im1k|inno|ipaq|iris|ja(t|v)a|jbro|jemu|jigs|kddi|keji|kgt( |\/)|klon|kpt |kwc\-|kyo(c|k)|le(no|xi)|lg( g|\/(k|l|u)|50|54|\-[a-w])|libw|lynx|m1\-w|m3ga|m50\/|ma(te|ui|xo)|mc(01|21|ca)|m\-cr|me(rc|ri)|mi(o8|oa|ts)|mmef|mo(01|02|bi|de|do|t(\-| |o|v)|zz)|mt(50|p1|v )|mwbp|mywa|n10[0-2]|n20[2-3]|n30(0|2)|n50(0|2|5)|n7(0(0|1)|10)|ne((c|m)\-|on|tf|wf|wg|wt)|nok(6|i)|nzph|o2im|op(ti|wv)|oran|owg1|p800|pan(a|d|t)|pdxg|pg(13|\-([1-8]|c))|phil|pire|pl(ay|uc)|pn\-2|po(ck|rt|se)|prox|psio|pt\-g|qa\-a|qc(07|12|21|32|60|\-[2-7]|i\-)|qtek|r380|r600|raks|rim9|ro(ve|zo)|s55\/|sa(ge|ma|mm|ms|ny|va)|sc(01|h\-|oo|p\-)|sdk\/|se(c(\-|0|1)|47|mc|nd|ri)|sgh\-|shar|sie(\-|m)|sk\-0|sl(45|id)|sm(al|ar|b3|it|t5)|so(ft|ny)|sp(01|h\-|v\-|v )|sy(01|mb)|t2(18|50)|t6(00|10|18)|ta(gt|lk)|tcl\-|tdg\-|tel(i|m)|tim\-|t\-mo|to(pl|sh)|ts(70|m\-|m3|m5)|tx\-9|up(\.b|g1|si)|utst|v400|v750|veri|vi(rg|te)|vk(40|5[0-3]|\-v)|vm40|voda|vulc|vx(52|53|60|61|70|80|81|83|85|98)|w3c(\-| )|webc|whit|wi(g |nc|nw)|wmlb|wonu|x700|yas\-|your|zeto|zte\-/i,tabletPattern:/android|ipad|playbook|silk/i};var h,i=Object.prototype.hasOwnProperty;return g.FALLBACK_PHONE="UnknownPhone",g.FALLBACK_TABLET="UnknownTablet",g.FALLBACK_MOBILE="UnknownMobile",h="isArray"in Array?Array.isArray:function(a){return"[object Array]"===Object.prototype.toString.call(a)},function(){var a,b,c,e,f,j,k=g.mobileDetectRules;for(a in k.props)if(i.call(k.props,a)){for(b=k.props[a],h(b)||(b=[b]),f=b.length,e=0;e<f;++e)c=b[e],j=c.indexOf("[VER]"),j>=0&&(c=c.substring(0,j)+"([\\w._\\+]+)"+c.substring(j+5)),b[e]=new RegExp(c,"i");k.props[a]=b}d(k.oss),d(k.phones),d(k.tablets),d(k.uas),d(k.utils),k.oss0={WindowsPhoneOS:k.oss.WindowsPhoneOS,WindowsMobileOS:k.oss.WindowsMobileOS}}(),g.findMatch=function(a,b){for(var c in a)if(i.call(a,c)&&a[c].test(b))return c;return null},g.findMatches=function(a,b){var c=[];for(var d in a)i.call(a,d)&&a[d].test(b)&&c.push(d);return c},g.getVersionStr=function(a,b){var c,d,e,f,h=g.mobileDetectRules.props;if(i.call(h,a))for(c=h[a],e=c.length,d=0;d<e;++d)if(f=c[d].exec(b),null!==f)return f[1];return null},g.getVersion=function(a,b){var c=g.getVersionStr(a,b);return c?g.prepareVersionNo(c):NaN},g.prepareVersionNo=function(a){var b;return b=a.split(/[a-z._ \/\-]/i),1===b.length&&(a=b[0]),b.length>1&&(a=b[0]+".",b.shift(),a+=b.join("")),Number(a)},g.isMobileFallback=function(a){return g.detectMobileBrowsers.fullPattern.test(a)||g.detectMobileBrowsers.shortPattern.test(a.substr(0,4))},g.isTabletFallback=function(a){return g.detectMobileBrowsers.tabletPattern.test(a)},g.prepareDetectionCache=function(a,c,d){if(a.mobile===b){var e,h,i;return(h=g.findMatch(g.mobileDetectRules.tablets,c))?(a.mobile=a.tablet=h,void(a.phone=null)):(e=g.findMatch(g.mobileDetectRules.phones,c))?(a.mobile=a.phone=e,void(a.tablet=null)):void(g.isMobileFallback(c)?(i=f.isPhoneSized(d),i===b?(a.mobile=g.FALLBACK_MOBILE,a.tablet=a.phone=null):i?(a.mobile=a.phone=g.FALLBACK_PHONE,a.tablet=null):(a.mobile=a.tablet=g.FALLBACK_TABLET,a.phone=null)):g.isTabletFallback(c)?(a.mobile=a.tablet=g.FALLBACK_TABLET,a.phone=null):a.mobile=a.tablet=a.phone=null)}},g.mobileGrade=function(a){var b=null!==a.mobile();return a.os("iOS")&&a.version("iPad")>=4.3||a.os("iOS")&&a.version("iPhone")>=3.1||a.os("iOS")&&a.version("iPod")>=3.1||a.version("Android")>2.1&&a.is("Webkit")||a.version("Windows Phone OS")>=7||a.is("BlackBerry")&&a.version("BlackBerry")>=6||a.match("Playbook.*Tablet")||a.version("webOS")>=1.4&&a.match("Palm|Pre|Pixi")||a.match("hp.*TouchPad")||a.is("Firefox")&&a.version("Firefox")>=12||a.is("Chrome")&&a.is("AndroidOS")&&a.version("Android")>=4||a.is("Skyfire")&&a.version("Skyfire")>=4.1&&a.is("AndroidOS")&&a.version("Android")>=2.3||a.is("Opera")&&a.version("Opera Mobi")>11&&a.is("AndroidOS")||a.is("MeeGoOS")||a.is("Tizen")||a.is("Dolfin")&&a.version("Bada")>=2||(a.is("UC Browser")||a.is("Dolfin"))&&a.version("Android")>=2.3||a.match("Kindle Fire")||a.is("Kindle")&&a.version("Kindle")>=3||a.is("AndroidOS")&&a.is("NookTablet")||a.version("Chrome")>=11&&!b||a.version("Safari")>=5&&!b||a.version("Firefox")>=4&&!b||a.version("MSIE")>=7&&!b||a.version("Opera")>=10&&!b?"A":a.os("iOS")&&a.version("iPad")<4.3||a.os("iOS")&&a.version("iPhone")<3.1||a.os("iOS")&&a.version("iPod")<3.1||a.is("Blackberry")&&a.version("BlackBerry")>=5&&a.version("BlackBerry")<6||a.version("Opera Mini")>=5&&a.version("Opera Mini")<=6.5&&(a.version("Android")>=2.3||a.is("iOS"))||a.match("NokiaN8|NokiaC7|N97.*Series60|Symbian/3")||a.version("Opera Mobi")>=11&&a.is("SymbianOS")?"B":(a.version("BlackBerry")<5||a.match("MSIEMobile|Windows CE.*Mobile")||a.version("Windows Mobile")<=5.2,"C")},g.detectOS=function(a){return g.findMatch(g.mobileDetectRules.oss0,a)||g.findMatch(g.mobileDetectRules.oss,a)},g.getDeviceSmallerSide=function(){return window.screen.width<window.screen.height?window.screen.width:window.screen.height},f.prototype={constructor:f,mobile:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.mobile},phone:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.phone},tablet:function(){return g.prepareDetectionCache(this._cache,this.ua,this.maxPhoneWidth),this._cache.tablet},userAgent:function(){return this._cache.userAgent===b&&(this._cache.userAgent=g.findMatch(g.mobileDetectRules.uas,this.ua)),this._cache.userAgent},userAgents:function(){return this._cache.userAgents===b&&(this._cache.userAgents=g.findMatches(g.mobileDetectRules.uas,this.ua)),this._cache.userAgents},os:function(){return this._cache.os===b&&(this._cache.os=g.detectOS(this.ua)),this._cache.os},version:function(a){return g.getVersion(a,this.ua)},versionStr:function(a){return g.getVersionStr(a,this.ua)},is:function(b){return c(this.userAgents(),b)||a(b,this.os())||a(b,this.phone())||a(b,this.tablet())||c(g.findMatches(g.mobileDetectRules.utils,this.ua),b)},match:function(a){return a instanceof RegExp||(a=new RegExp(a,"i")),a.test(this.ua)},isPhoneSized:function(a){return f.isPhoneSized(a||this.maxPhoneWidth)},mobileGrade:function(){return this._cache.grade===b&&(this._cache.grade=g.mobileGrade(this)),this._cache.grade}},"undefined"!=typeof window&&window.screen?f.isPhoneSized=function(a){return a<0?b:g.getDeviceSmallerSide()<=a}:f.isPhoneSized=function(){},f._impl=g,f.version="1.4.5 2021-03-13",f})}(function(a){if("undefined"!=typeof module&&module.exports)return function(a){module.exports=a()};if("function"==typeof define&&define.amd)return define;if("undefined"!=typeof window)return function(a){window.MobileDetect=a()};throw new Error("unknown environment")}());var ai_lists=!0,ai_block_class_def="code-block";
if("undefined"!=typeof ai_lists){function X(b,e){for(var n=[];b=b.previousElementSibling;)("undefined"==typeof e||b.matches(e))&&n.push(b);return n}function fa(b,e){for(var n=[];b=b.nextElementSibling;)("undefined"==typeof e||b.matches(e))&&n.push(b);return n}var host_regexp=RegExp(":\\/\\/(.[^/:]+)","i");function ha(b){b=b.match(host_regexp);return null!=b&&1<b.length&&"string"===typeof b[1]&&0<b[1].length?b[1].toLowerCase():null}function Q(b){return b.includes(":")?(b=b.split(":"),1E3*(3600*parseInt(b[0])+
60*parseInt(b[1])+parseInt(b[2]))):null}function Y(b){try{var e=Date.parse(b);isNaN(e)&&(e=null)}catch(n){e=null}if(null==e&&b.includes(" ")){b=b.split(" ");try{e=Date.parse(b[0]),e+=Q(b[1]),isNaN(e)&&(e=null)}catch(n){e=null}}return e}function Z(){null==document.querySelector("#ai-iab-tcf-bar")&&null==document.querySelector(".ai-list-manual")||"function"!=typeof __tcfapi||"function"!=typeof ai_load_blocks||"undefined"!=typeof ai_iab_tcf_callback_installed||(__tcfapi("addEventListener",2,function(b,
e){e&&"useractioncomplete"===b.eventStatus&&(ai_tcData=b,ai_load_blocks(),b=document.querySelector("#ai-iab-tcf-status"),null!=b&&(b.textContent="IAB TCF 2.0 DATA LOADED"),b=document.querySelector("#ai-iab-tcf-bar"),null!=b&&(b.classList.remove("status-error"),b.classList.add("status-ok")))}),ai_iab_tcf_callback_installed=!0)}ai_process_lists=function(b){function e(a,c,k){if(0==a.length){if("!@!"==k)return!0;c!=k&&("true"==k.toLowerCase()?k=!0:"false"==k.toLowerCase()&&(k=!1));return c==k}if("object"!=
typeof c&&"array"!=typeof c)return!1;var l=a[0];a=a.slice(1);if("*"==l)for(let [,p]of Object.entries(c)){if(e(a,p,k))return!0}else if(l in c)return e(a,c[l],k);return!1}function n(a,c,k){if("object"!=typeof a||-1==c.indexOf("["))return!1;c=c.replace(/]| /gi,"").split("[");return e(c,a,k)}function z(){if("function"==typeof __tcfapi){var a=document.querySelector("#ai-iab-tcf-status"),c=document.querySelector("#ai-iab-tcf-bar");null!=a&&(a.textContent="IAB TCF 2.0 DETECTED");__tcfapi("getTCData",2,function(k,
l){l?(null!=c&&(c.classList.remove("status-error"),c.classList.add("status-ok")),"tcloaded"==k.eventStatus||"useractioncomplete"==k.eventStatus)?(ai_tcData=k,k.gdprApplies?null!=a&&(a.textContent="IAB TCF 2.0 DATA LOADED"):null!=a&&(a.textContent="IAB TCF 2.0 GDPR DOES NOT APPLY"),null!=c&&(c.classList.remove("status-error"),c.classList.add("status-ok")),setTimeout(function(){ai_process_lists()},10)):"cmpuishown"==k.eventStatus&&(ai_cmpuishown=!0,null!=a&&(a.textContent="IAB TCF 2.0 CMP UI SHOWN"),
null!=c&&(c.classList.remove("status-error"),c.classList.add("status-ok"))):(null!=a&&(a.textContent="IAB TCF 2.0 __tcfapi getTCData failed"),null!=c&&(c.classList.remove("status-ok"),c.classList.add("status-error")))})}}function C(a){"function"==typeof __tcfapi?(ai_tcfapi_found=!0,"undefined"==typeof ai_iab_tcf_callback_installed&&Z(),"undefined"==typeof ai_tcData_requested&&(ai_tcData_requested=!0,z(),cookies_need_tcData=!0)):a&&("undefined"==typeof ai_tcfapi_found&&(ai_tcfapi_found=!1,setTimeout(function(){ai_process_lists()},
10)),a=document.querySelector("#ai-iab-tcf-status"),null!=a&&(a.textContent="IAB TCF 2.0 MISSING: __tcfapi function not found"),a=document.querySelector("#ai-iab-tcf-bar"),null!=a&&(a.classList.remove("status-ok"),a.classList.add("status-error")))}if(null==b)b=document.querySelectorAll("div.ai-list-data, meta.ai-list-data");else{window.jQuery&&window.jQuery.fn&&b instanceof jQuery&&(b=Array.prototype.slice.call(b));var x=[];b.forEach((a,c)=>{a.matches(".ai-list-data")?x.push(a):(a=a.querySelectorAll(".ai-list-data"),
a.length&&a.forEach((k,l)=>{x.push(k)}))});b=x}if(b.length){b.forEach((a,c)=>{a.classList.remove("ai-list-data")});var L=ia(window.location.search);if(null!=L.referrer)var A=L.referrer;else A=document.referrer,""!=A&&(A=ha(A));var R=window.navigator.userAgent,S=R.toLowerCase(),aa=navigator.language,M=aa.toLowerCase();if("undefined"!==typeof MobileDetect)var ba=new MobileDetect(R);b.forEach((a,c)=>{var k=document.cookie.split(";");k.forEach(function(f,h){k[h]=f.trim()});c=a.closest("div."+ai_block_class_def);
var l=!0;if(a.hasAttribute("referer-list")){var p=a.getAttribute("referer-list");p=b64d(p).split(",");var v=a.getAttribute("referer-list-type"),E=!1;p.every((f,h)=>{f=f.trim();if(""==f)return!0;if("*"==f.charAt(0))if("*"==f.charAt(f.length-1)){if(f=f.substr(1,f.length-2),-1!=A.indexOf(f))return E=!0,!1}else{if(f=f.substr(1),A.substr(-f.length)==f)return E=!0,!1}else if("*"==f.charAt(f.length-1)){if(f=f.substr(0,f.length-1),0==A.indexOf(f))return E=!0,!1}else if("#"==f){if(""==A)return E=!0,!1}else if(f==
A)return E=!0,!1;return!0});var r=E;switch(v){case "B":r&&(l=!1);break;case "W":r||(l=!1)}}if(l&&a.hasAttribute("client-list")&&"undefined"!==typeof ba)switch(p=a.getAttribute("client-list"),p=b64d(p).split(","),v=a.getAttribute("client-list-type"),r=!1,p.every((f,h)=>{if(""==f.trim())return!0;f.split("&&").every((d,t)=>{t=!0;var w=!1;for(d=d.trim();"!!"==d.substring(0,2);)t=!t,d=d.substring(2);"language:"==d.substring(0,9)&&(w=!0,d=d.substring(9).toLowerCase());var q=!1;w?"*"==d.charAt(0)?"*"==d.charAt(d.length-
1)?(d=d.substr(1,d.length-2).toLowerCase(),-1!=M.indexOf(d)&&(q=!0)):(d=d.substr(1).toLowerCase(),M.substr(-d.length)==d&&(q=!0)):"*"==d.charAt(d.length-1)?(d=d.substr(0,d.length-1).toLowerCase(),0==M.indexOf(d)&&(q=!0)):d==M&&(q=!0):"*"==d.charAt(0)?"*"==d.charAt(d.length-1)?(d=d.substr(1,d.length-2).toLowerCase(),-1!=S.indexOf(d)&&(q=!0)):(d=d.substr(1).toLowerCase(),S.substr(-d.length)==d&&(q=!0)):"*"==d.charAt(d.length-1)?(d=d.substr(0,d.length-1).toLowerCase(),0==S.indexOf(d)&&(q=!0)):ba.is(d)&&
(q=!0);return(r=q?t:!t)?!0:!1});return r?!1:!0}),v){case "B":r&&(l=!1);break;case "W":r||(l=!1)}var N=p=!1;for(v=1;2>=v;v++)if(l){switch(v){case 1:var g=a.getAttribute("cookie-list");break;case 2:g=a.getAttribute("parameter-list")}if(null!=g){g=b64d(g);switch(v){case 1:var y=a.getAttribute("cookie-list-type");break;case 2:y=a.getAttribute("parameter-list-type")}g=g.replace("tcf-gdpr","tcf-v2[gdprApplies]=true");g=g.replace("tcf-no-gdpr","tcf-v2[gdprApplies]=false");g=g.replace("tcf-google","tcf-v2[vendor][consents][755]=true && tcf-v2[purpose][consents][1]=true");
g=g.replace("tcf-no-google","!!tcf-v2[vendor][consents][755]");g=g.replace("tcf-media.net","tcf-v2[vendor][consents][142]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-media.net","!!tcf-v2[vendor][consents][142]");g=g.replace("tcf-amazon","tcf-v2[vendor][consents][793]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-amazon","!!tcf-v2[vendor][consents][793]");g=g.replace("tcf-ezoic","tcf-v2[vendor][consents][347]=true && tcf-v2[purpose][consents][1]=true");g=g.replace("tcf-no-ezoic",
"!!tcf-v2[vendor][consents][347]");var F=g.split(","),ca=[];k.forEach(function(f){f=f.split("=");try{var h=JSON.parse(decodeURIComponent(f[1]))}catch(d){h=decodeURIComponent(f[1])}ca[f[0]]=h});r=!1;var I=a;F.every((f,h)=>{f.split("&&").every((d,t)=>{t=!0;for(d=d.trim();"!!"==d.substring(0,2);)t=!t,d=d.substring(2);var w=d,q="!@!",T="tcf-v2"==w&&"!@!"==q,B=-1!=d.indexOf("["),J=0==d.indexOf("tcf-v2")||0==d.indexOf("euconsent-v2");J=J&&(B||T);-1!=d.indexOf("=")&&(q=d.split("="),w=q[0],q=q[1],B=-1!=w.indexOf("["),
J=(J=0==w.indexOf("tcf-v2")||0==w.indexOf("euconsent-v2"))&&(B||T));if(J)document.querySelector("#ai-iab-tcf-status"),B=document.querySelector("#ai-iab-tcf-bar"),null!=B&&(B.style.display="block"),T&&"boolean"==typeof ai_tcfapi_found?r=ai_tcfapi_found?t:!t:"object"==typeof ai_tcData?(null!=B&&(B.classList.remove("status-error"),B.classList.add("status-ok")),w=w.replace(/]| /gi,"").split("["),w.shift(),r=(w=e(w,ai_tcData,q))?t:!t):"undefined"==typeof ai_tcfapi_found&&(I.classList.add("ai-list-data"),
N=!0,"function"==typeof __tcfapi?C(!1):"undefined"==typeof ai_tcData_retrying&&(ai_tcData_retrying=!0,setTimeout(function(){"function"==typeof __tcfapi?C(!1):setTimeout(function(){"function"==typeof __tcfapi?C(!1):setTimeout(function(){C(!0)},3E3)},1E3)},600)));else if(B)r=(w=n(ca,w,q))?t:!t;else{var U=!1;"!@!"==q?k.every(function(ja){return ja.split("=")[0]==d?(U=!0,!1):!0}):U=-1!=k.indexOf(d);r=U?t:!t}return r?!0:!1});return r?!1:!0});r&&(N=!1,I.classList.remove("ai-list-data"));switch(y){case "B":r&&
(l=!1);break;case "W":r||(l=!1)}}}a.classList.contains("ai-list-manual")&&(l?(I.classList.remove("ai-list-data"),I.classList.remove("ai-list-manual")):(p=!0,I.classList.add("ai-list-data")));(l||!p&&!N)&&a.hasAttribute("data-debug-info")&&(g=document.querySelector("."+a.dataset.debugInfo),null!=g&&(g=g.parentElement,null!=g&&g.classList.contains("ai-debug-info")&&g.remove()));y=X(a,".ai-debug-bar.ai-debug-lists");var ka=""==A?"#":A;0!=y.length&&y.forEach((f,h)=>{h=f.querySelector(".ai-debug-name.ai-list-info");
null!=h&&(h.textContent=ka,h.title=R+"\n"+aa);h=f.querySelector(".ai-debug-name.ai-list-status");null!=h&&(h.textContent=l?ai_front.visible:ai_front.hidden)});g=!1;if(l&&a.hasAttribute("scheduling-start")&&a.hasAttribute("scheduling-end")&&a.hasAttribute("scheduling-days")){var u=a.getAttribute("scheduling-start");v=a.getAttribute("scheduling-end");y=a.getAttribute("scheduling-days");g=!0;u=b64d(u);F=b64d(v);var V=parseInt(a.getAttribute("scheduling-fallback")),O=parseInt(a.getAttribute("gmt"));if(u.includes("-")||
F.includes("-"))P=Y(u)+O,K=Y(F)+O;else var P=Q(u),K=Q(F);P??=0;K??=0;var W=b64d(y).split(",");y=a.getAttribute("scheduling-type");var D=(new Date).getTime()+O;v=new Date(D);var G=v.getDay();0==G?G=6:G--;u.includes("-")||F.includes("-")||(u=(new Date(v.getFullYear(),v.getMonth(),v.getDate())).getTime()+O,D-=u,0>D&&(D+=864E5));scheduling_start_date_ok=D>=P;scheduling_end_date_ok=0==K||D<K;u=scheduling_start_date_ok&&scheduling_end_date_ok&&W.includes(G.toString());switch(y){case "B":u=!u}u||(l=!1);
var la=v.toISOString().split(".")[0].replace("T"," ");y=X(a,".ai-debug-bar.ai-debug-scheduling");0!=y.length&&y.forEach((f,h)=>{h=f.querySelector(".ai-debug-name.ai-scheduling-info");null!=h&&(h.textContent=la+" "+G+" current_time: "+Math.floor(D.toString()/1E3)+" start_date:"+Math.floor(P/1E3).toString()+"=>"+scheduling_start_date_ok.toString()+" end_date:"+Math.floor(K/1E3).toString()+"=>"+scheduling_end_date_ok.toString()+" days:"+W.toString()+"=>"+W.includes(G.toString()).toString());h=f.querySelector(".ai-debug-name.ai-scheduling-status");
null!=h&&(h.textContent=l?ai_front.visible:ai_front.hidden);l||0==V||(f.classList.remove("ai-debug-scheduling"),f.classList.add("ai-debug-fallback"),h=f.querySelector(".ai-debug-name.ai-scheduling-status"),null!=h&&(h.textContent=ai_front.fallback+" = "+V))})}if(p||!l&&N)return!0;a.style.visibility="";a.style.position="";a.style.width="";a.style.height="";a.style.zIndex="";if(l){if(null!=c&&(c.style.visibility="",c.classList.contains("ai-remove-position")&&(c.style.position="")),a.hasAttribute("data-code")){p=
b64d(a.dataset.code);u=document.createRange();g=!0;try{H=u.createContextualFragment(p)}catch(f){g=!1}g&&(null!=a.closest("head")?(a.parentNode.insertBefore(H,a.nextSibling),a.remove()):a.append(H));da(a)}}else if(g&&!u&&0!=V){null!=c&&(c.style.visibility="",c.classList.contains("ai-remove-position")&&c.css({position:""}));p=fa(a,".ai-fallback");0!=p.length&&p.forEach((f,h)=>{f.classList.remove("ai-fallback")});if(a.hasAttribute("data-fallback-code")){p=b64d(a.dataset.fallbackCode);u=document.createRange();
g=!0;try{var H=u.createContextualFragment(p)}catch(f){g=!1}g&&a.append(H);da(a)}else a.style.display="none",null!=c&&null==c.querySelector(".ai-debug-block")&&c.hasAttribute("style")&&-1==c.getAttribute("style").indexOf("height:")&&(c.style.display="none");null!=c&&c.hasAttribute("data-ai")&&(c.getAttribute("data-ai"),a.hasAttribute("fallback-tracking")&&(H=a.getAttribute("fallback-tracking"),c.setAttribute("data-ai-"+a.getAttribute("fallback_level"),H)))}else a.style.display="none",null!=c&&(c.removeAttribute("data-ai"),
c.classList.remove("ai-track"),null!=c.querySelector(".ai-debug-block")?(c.style.visibility="",c.classList.remove("ai-close"),c.classList.contains("ai-remove-position")&&(c.style.position="")):c.hasAttribute("style")&&-1==c.getAttribute("style").indexOf("height:")&&(c.style.display="none"));a.setAttribute("data-code","");a.setAttribute("data-fallback-code","");null!=c&&c.classList.remove("ai-list-block")})}};function ea(b){b=`; ${document.cookie}`.split(`; ${b}=`);if(2===b.length)return b.pop().split(";").shift()}
function ma(b,e,n){ea(b)&&(document.cookie=b+"="+(e?";path="+e:"")+(n?";domain="+n:"")+";expires=Thu, 01 Jan 1970 00:00:01 GMT")}function m(b){ea(b)&&(ma(b,"/",window.location.hostname),document.cookie=b+"=; Path=/; Expires=Thu, 01 Jan 1970 00:00:01 GMT;")}(function(b){"complete"===document.readyState||"loading"!==document.readyState&&!document.documentElement.doScroll?b():document.addEventListener("DOMContentLoaded",b)})(function(){setTimeout(function(){ai_process_lists();setTimeout(function(){Z();
if("function"==typeof ai_load_blocks){document.addEventListener("cmplzEnableScripts",e);document.addEventListener("cmplz_event_marketing",e);function e(n){"cmplzEnableScripts"!=n.type&&"all"!==n.consentLevel||ai_load_blocks()}document.addEventListener("cmplz_enable_category",function(n){"marketing"===n.detail.category&&ai_load_blocks()})}},50);var b=document.querySelector(".ai-debug-page-type");null!=b&&b.addEventListener("dblclick",e=>{e=document.querySelector("#ai-iab-tcf-status");null!=e&&(e.textContent=
"CONSENT COOKIES");e=document.querySelector("#ai-iab-tcf-bar");null!=e&&(e.style.display="block")});b=document.querySelector("#ai-iab-tcf-bar");null!=b&&b.addEventListener("click",e=>{m("euconsent-v2");m("__lxG__consent__v2");m("__lxG__consent__v2_daisybit");m("__lxG__consent__v2_gdaisybit");m("CookieLawInfoConsent");m("cookielawinfo-checkbox-advertisement");m("cookielawinfo-checkbox-analytics");m("cookielawinfo-checkbox-necessary");m("complianz_policy_id");m("complianz_consent_status");m("cmplz_marketing");
m("cmplz_consent_status");m("cmplz_preferences");m("cmplz_statistics-anonymous");m("cmplz_choice");m("cmplz_banner-status");m("cmplz_functional");m("cmplz_policy_id");m("cmplz_statistics");m("moove_gdpr_popup");m("real_cookie_banner-blog:1-tcf");m("real_cookie_banner-blog:1");e=document.querySelector("#ai-iab-tcf-status");null!=e&&(e.textContent="CONSENT COOKIES DELETED")})},5)});function da(b){setTimeout(function(){"function"==typeof ai_process_rotations_in_element&&ai_process_rotations_in_element(b);
"function"==typeof ai_process_lists&&ai_process_lists();"function"==typeof ai_process_ip_addresses&&ai_process_ip_addresses();"function"==typeof ai_process_filter_hooks&&ai_process_filter_hooks();"function"==typeof ai_adb_process_blocks&&ai_adb_process_blocks(b);"function"==typeof ai_process_impressions&&1==ai_tracking_finished&&ai_process_impressions();"function"==typeof ai_install_click_trackers&&1==ai_tracking_finished&&ai_install_click_trackers();"function"==typeof ai_install_close_buttons&&ai_install_close_buttons(document)},
5)}function ia(b){var e=b?b.split("?")[1]:window.location.search.slice(1);b={};if(e){e=e.split("#")[0];e=e.split("&");for(var n=0;n<e.length;n++){var z=e[n].split("="),C=void 0,x=z[0].replace(/\[\d*\]/,function(L){C=L.slice(1,-1);return""});z="undefined"===typeof z[1]?"":z[1];x=x.toLowerCase();z=z.toLowerCase();b[x]?("string"===typeof b[x]&&(b[x]=[b[x]]),"undefined"===typeof C?b[x].push(z):b[x][C]=z):b[x]=z}}return b}};
ai_run_741196977980 = function(){
ai_document_write=document.write;document.write=function(a){"interactive"==document.readyState?(console.error("document.write called after page load: ",a),"undefined"!=typeof ai_js_errors&&ai_js_errors.push(["document.write called after page load",a,0])):ai_document_write.call(document,a)};
ai_insert ('before', 'h2#_2', b64d ('PGRpdiBjbGFzcz0nY29kZS1ibG9jayBjb2RlLWJsb2NrLTEnIHN0eWxlPSdtYXJnaW46IDhweCAwOyBjbGVhcjogYm90aDsnPgo8ZGl2IGlkPSJpbS03ZjYwY2E5ZTU0MjA0YzBiYmZiNzRjMGRjYjg4Y2U2ZCI+CiAgPHNjcmlwdCBhc3luYyBzcmM9Imh0dHBzOi8vaW1wLWFkZWRnZS5pLW1vYmlsZS5jby5qcC9zY3JpcHQvdjEvc3BvdC5qcz8yMDIyMDEwNCI+PC9zY3JpcHQ+CiAgPHNjcmlwdD4od2luZG93LmFkc2J5aW1vYmlsZT13aW5kb3cuYWRzYnlpbW9iaWxlfHxbXSkucHVzaCh7cGlkOjg0OTcxLG1pZDo1OTM4NDMsYXNpZDoxOTM2NTc3LHR5cGU6ImJhbm5lciIsZGlzcGxheToiaW5saW5lIixlbGVtZW50aWQ6ImltLTdmNjBjYTllNTQyMDRjMGJiZmI3NGMwZGNiODhjZTZkIn0pPC9zY3JpcHQ+CjwvZGl2PjwvZGl2Pgo='));
};
if (document.readyState === 'complete' || (document.readyState !== 'loading' && !document.documentElement.doScroll)) ai_run_741196977980 (); else document.addEventListener ('DOMContentLoaded', ai_run_741196977980);
ai_js_code = true;
</script>
</body></html>