
HTMLHeaderTextSplitterは、ドキュメント内のヘッダーと本文を区別しやすくする自然言語処理の一部として開発されました。この記事では、その機能と背景、そして現代における役割について詳しく見ていきます。
この記事の目次
- HTMLHeaderTextSplitterとは
- HTMLHeaderTextSplitterの歴史
- 仕組みと性能
- HTMLHeaderTextSplitterと他のツールの比較
- まとめ
HTMLHeaderTextSplitterとは

このツールは、HTML文書からタイトルやセクションを抽出し、それらが文章全体の中で果たす役割を明確にします。
例えば、ウェブページ上の各ヘッダーがどの部分の内容を示しているかを自動で特定することは可能になり、これにより記事の構造化や要約作成が容易になります。
HTMLHeaderTextSplitterの歴史

HTMLHeaderTextSplitterの開発は、ウェブコンテンツが複雑化する中でユーザビリティを向上させるための試みから始まりました。
その後、さまざまなドキュメント解析ツールや機械学習モデルとの統合を通じて機能が拡張され、今日では多くのオンラインプラットフォームにおいて基本的な要件となっています。
仕組みと性能
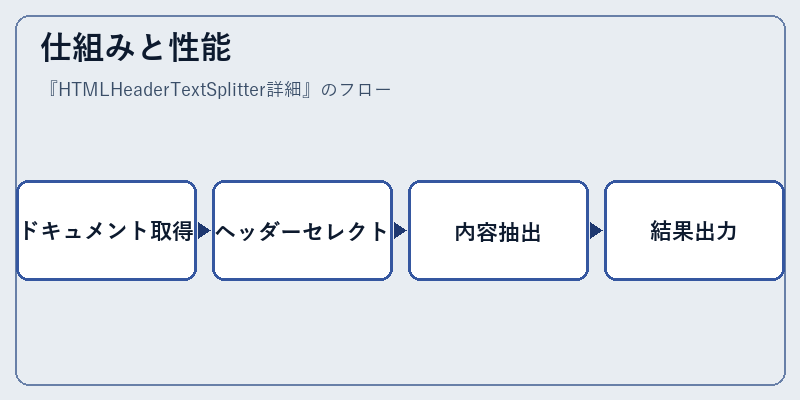
HTMLHeaderTextSplitterは、入力されたHTMLデータを分析し、各セクションの役割とその範囲を特定します。
このプロセスでは、テキストから意図的な構造を読み取り、その後それを人間が容易に理解できる形式で表示する仕組みになっています。
HTMLHeaderTextSplitterと他のツールの比較

HTMLHeaderTextSplitterは、主にウェブドキュメントの構造解析を目的としています。
一方で、テキストマイニングツールはより広範な文脈理解を目指し、ウェブページ以外のデータセットでも有用です。
まとめ
HTMLHeaderTextSplitterは現代のドキュメンテーション分析において重要な役割を果たしており、その技術進化と応用例について深く掘り下げることは今後の研究開発にとって不可欠となるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







