
機械学習における性能評価の重要な方法として、データ分割技術であるCross Validationが使われている。その歴史と進化を振り返りつつ、この手法が今日のデータサイエンスに果たす役割について詳しく紹介する。
この記事の目次
- Cross Validationとは
- Cross Validationの種類
- Cross Validationのワークフロー
- Cross Validationと他の評価技術の比較
- まとめ
Cross Validationとは
Cross Validationは、機械学習モデルの性能を正確に評価するために開発された手法です。その特徴には、
モデルが未知データに対する予測力を持つかどうかを適切に判定できる点があります。これは
機械学習における欠かせないプロセスと言えるでしょう。
具体的な例として、ある分類問題の検証を行う際、通常の単純なトレーニングとテストデータの分割とは異なり、Cross Validationは異なる訓練セットと評価セットを繰り返し使用することで、モデルの堅牢性を高めます。この手法により、モデルが特定のトレーニングセットに過度に適合していないかを確認できます。
Cross Validationの種類

Cross Validationには複数の異なる方法があり、それぞれの利点と制限があります。最も一般的なのはk-Fold Cross Validationで、データセットをk個に分割し、各々について訓練とテストを行う。
この手法は他の多くのバリエーションを生み出し、状況に応じた最適な選択が可能です。
Leave-One-Out Cross Validationでは、それぞれの観測値に対して一度だけモデルをトレーニングします。一方、Stratified k-foldはクラスバランスを維持するために使用されます。
また、Shuffle splitはランダムにデータセットを分割するため、時間系列データの場合はTime series cross-validationが選ばれることがあります。
Cross Validationのワークフロー
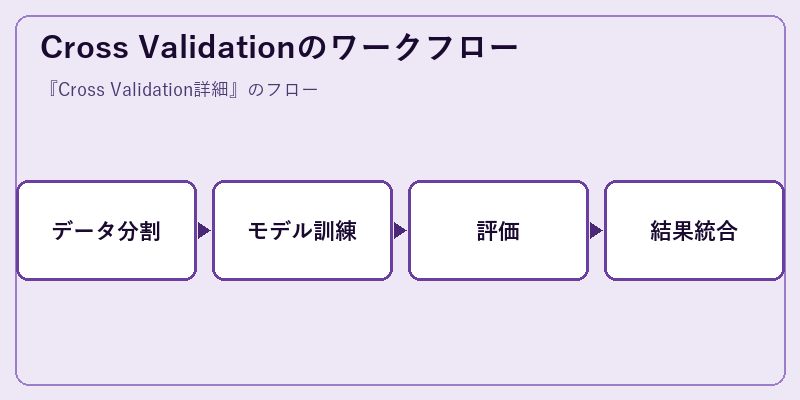
Cross Validationを行う際は、まずデータセットを適切に分割します。次に各セグメントについて学習とテストを行います。
この過程を通じて、モデルの性能を綿密に調査していきます。
評価ステップでは、前述した種類のCross Validationの中から最適な手法を選択し、精度や正規化などをチェックします。
結果が統合されると、全体としてのパフォーマンス指標が明確になります。
Cross Validationと他の評価技術の比較

Cross Validationと、より基本的な訓練/テスト分割という手法を比較すると、前者は後者よりも多くの観測値に基づいてモデルの評価を行います。
これが、Cross Validationがしばしば選択される主な理由です。
一方で、単純な訓練/テスト分割では、一部のデータセットが無視されてしまうことがあり、また過学習のリスクも高まります。
これらの課題を克服するために、複数回のデータ分割と評価を行うCross Validationが有用であると言えます。
まとめ
Cross Validationは機械学習における性能評価の鍵となる技術であり、モデルの信頼性と実用性を向上させるために重要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







