
PythonのデータサイエンスライブラリであるPyTorchやTensorFlowでは、データセットの操作を効率的に実装するための重要な関数としてDataset.map()が利用されています。この記事では、この関数の起源から最新の応用までを詳しく解説します。
この記事の目次
- Dataset.map() の基本的な構造
- map()関数の進化
- map()の内部動作
- 他のデータ操作方法との比較
- まとめ
Dataset.map() の基本的な構造
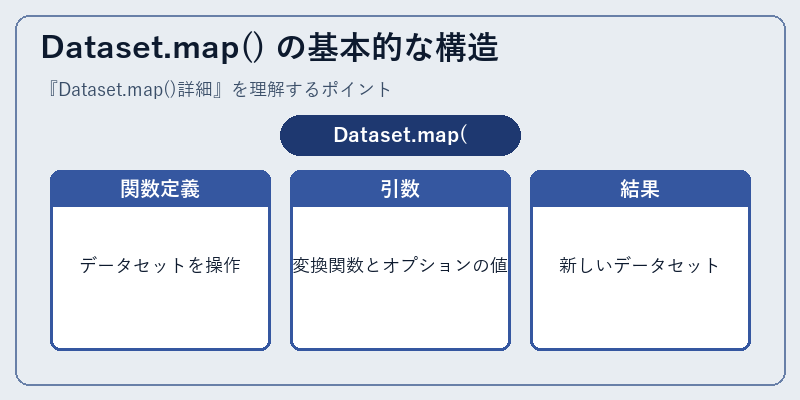
この関数は、PythonにおけるPyTorchやTensorFlowなどの機械学習フレームワークで頻繁に使用されます。map()関数を用いることで、複雑な処理の流れを簡潔かつ明確にすることができます。
具体的には、あるデータセットに対して各要素に適用したい処理を渡すと、その結果が新たなデータセットとして返ってきます。この機能は特に大量のデータを扱う際の効率化に寄与します。
map()関数の進化
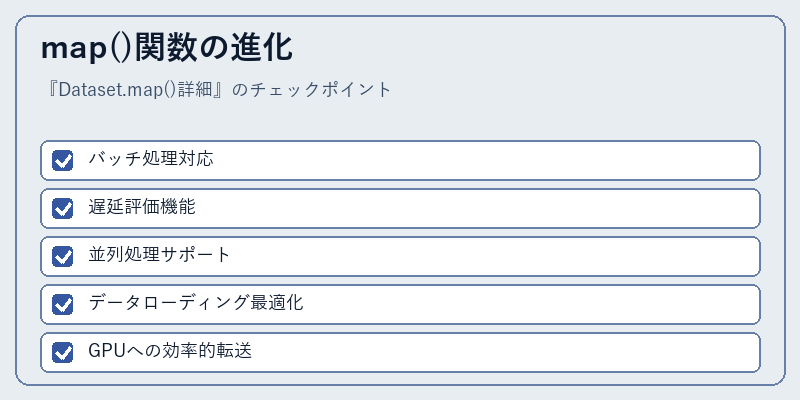
当初は単純なマッピング機能を提供しただけのmap()でしたが、最近では様々な拡張機能が追加されています。バッチ処理や遅延評価といった機能により、効率的なデータセット操作が可能になりました。
これらの進化は、複雑な機械学習モデルにおけるパフォーマンスの向上に大きく貢献しており、特に大規模なトレーニング作業ではその恩恵を受けることができます。
map()の内部動作
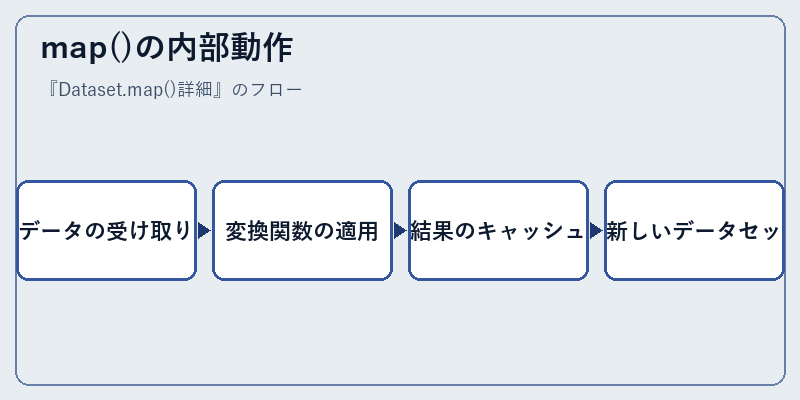
実際には、呼び出された際に一連の処理が内部で行われます。まず最初に渡された変換関数をデータ要素に対して逐次適用し、その後その結果はキャッシュや新たなデータ構造へ格納されます。
このプロセスにおいて、効率的なメモリ管理と並列化技術の活用によって全体のパフォーマンスが向上します。こうした点からもmap()関数の重要性が際立っています。
他のデータ操作方法との比較

map()と比較して、従来のデータ操作手法ではコードが複雑になりやすく、またパフォーマンス面での問題もしばしば生じます。一方でmap()はそのシンプルさから高い生産性を実現しています。
特に大規模なプロジェクトや日々進化する機械学習環境においては、効率的な処理と柔軟性の両立が必須であり、この点でもmap()の重要性は増すばかりです。
まとめ
Dataset.map()は現代のデータ科学や機械学習で欠かせないツールとして認識されつつあり、今後もその役割は大きくなると予想されます。この関数を効果的に活用することで、より高速で洗練されたコード開発が可能となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







