
2018年に設立されたオープンソースのプラットフォーム、Hugging Faceが提供するdatasetsは、自然言語処理モデルを訓練するための大規模なデータセットをホストしています。ここでは、その仕組みと特長について詳しく解説します。
この記事の目次
- HuggingFace datasetsの定義
- 歴史と発展
- データセットの取り扱い方法
- 他のデータセットサービスとの比較
- まとめ
HuggingFace datasetsの定義

大規模な自然言語処理データを提供するdatasetsは、多様な研究者がモデル開発に取り組める基盤となる。API経由でのアクセスやPythonライブラリを通じた統合利用が可能だ。
例えば、Wikipediaの全文やSQuADのような質問応答タスク用データセットを容易に取得し、モデルトレーニングに活用できる。
歴史と発展
HuggingFace datasetsは、オープンソースプロジェクトとしてスタートし、研究者の間で急速に普及しました。
2019年に登録数が爆発的に増えた理由の一つは、各データセットをAPI経由で簡単にアクセスできることです。
データセットの取り扱い方法

HuggingFace datasetsでは、まずAPIを使用して目的のデータセットを検索します。次に、必要に応じて前処理を行います。
検索と処理後は、バッチでダウンロードし、最終的に自然言語処理モデルへの統合へと進める流れが標準的です。
他のデータセットサービスとの比較
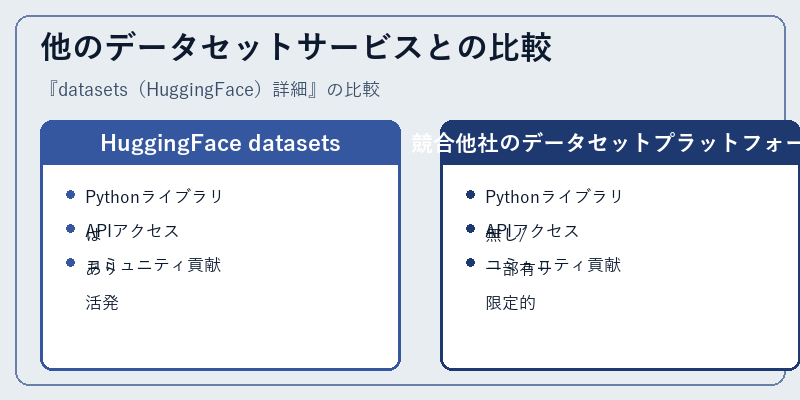
HuggingFace datasetsは、自然言語処理モデルの開発者にとって柔軟性と効率を提供します。
対する他のデータセットプラットフォームでは、Python統合やAPIアクセシビリティが制限され、コミュニティ活動も少ない傾向にあります。
まとめ
HuggingFace datasetsは自然言語処理モデル開発において重要な役割を果たしています。データセットの取り扱い方法や比較点などを理解することで、研究・実装における効率的な活用が可能となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







