
BERT(Bidirectional Encoder Representations from Transformers)は、Googleのジェイコブ・デブリン氏らが2018年10月に発表した事前学習済み言語モデルである。Transformerのエンコーダ部分を双方向に学習することで、それまで一方向だったGPT系モデルや浅い表現しか得られなかったWord2Vec/GloVeを大きく上回る精度を叩き出した。GLUE、SQuADなど主要ベンチマークを軒並み更新し、自然言語処理の歴史を「BERT前」と「BERT後」に分けたとさえ言われる。本記事ではBERTの構造、事前学習タスク、ファインチューニング手順、後継モデルへの影響を整理する。
この記事の目次
- BERTの新規性は3点に集約される
- Word2VecからBERTまでの系譜
- ファインチューニングの典型ユースケース
- BERT派生モデルと現在の立ち位置
- まとめ
BERTの新規性は3点に集約される
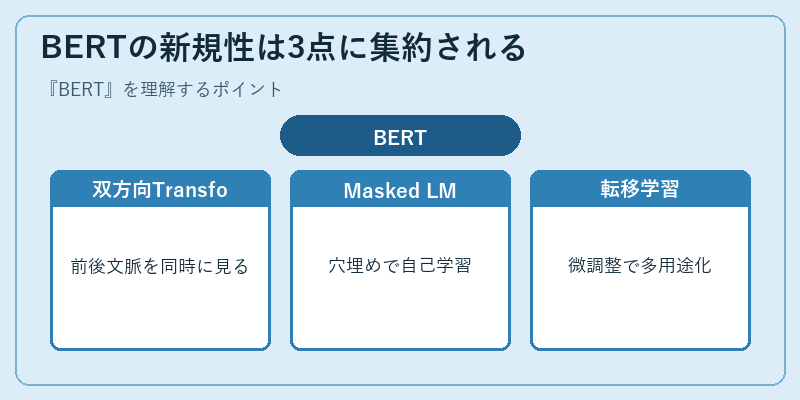
BERTの最大の発明は、Transformerエンコーダを双方向に動かしたことだ。GPT-1(2018年6月)は左から右への一方向学習だったが、BERTは「文中の単語の前後両方の文脈」を同時に参照しながら学習する。Masked Language Model(MLM)と呼ばれる事前学習タスクでは、入力文の15%の単語をマスクして当てさせるという穴埋め問題を解かせる仕組みだ。
もう一つの事前学習タスクがNext Sentence Prediction(NSP)で、2文がつながっているかを判定する二値分類だった。事前学習で巨大なWikipediaやBooksCorpusを読み込み、その後タスク別の少量データで微調整する転移学習が、自然言語処理の常識を一気に書き換えた。BERTBaseは1.1億、BERTLargeは3.4億パラメータと、当時としては破格の規模だった。
Word2VecからBERTまでの系譜

BERT登場前の言語表現学習は、2013年のWord2Vec、2014年のGloVeに代表される単語埋め込みが主流だった。ただし「bank」が「銀行」か「土手」かを文脈で区別できないという欠点があった。2018年初頭にAllenAIから登場したELMoは双方向LSTMで文脈依存埋め込みを実現し、業界が一気に文脈モデルへ舵を切る。
同年6月、OpenAIのGPT-1がTransformerデコーダの事前学習+ファインチューニングという枠組みを提示。そして10月、GoogleがBERTを発表してGLUEスコアを劇的に塗り替えた。わずか半年で「単語埋め込み→双方向LSTM→Transformer事前学習」へと地殻変動が起きた、言語処理史でも稀有なスピード感だった。
ファインチューニングの典型ユースケース

BERTは事前学習済みの重みをHugging Face Hub等から取得し、特定タスクに合わせて出力層を載せ替えて微調整する流れが定番だ。Googleは2019年10月、検索エンジン本体にBERTを組み込んだと発表し、英語クエリの約10%の理解精度が改善したと報告した。問い合わせの文脈理解、口語的な表現、前置詞の意味の取り違えなど、検索アルゴリズムが長年苦戦してきた領域に直接効いたのである。
国内ではNTTやサイバーエージェント、東北大学の乾研究室などが日本語版BERT(東北大版BERT、cl-tohoku/bert-base-japanese系)を公開し、企業や研究機関が広く使った。Q&A、レビュー分析、メール自動分類、医療文書のキーフレーズ抽出など応用は多岐にわたる。GPT登場以前の自然言語処理プロジェクトでは、まずBERTから始めるのが現実的な選択だった。
BERT派生モデルと現在の立ち位置
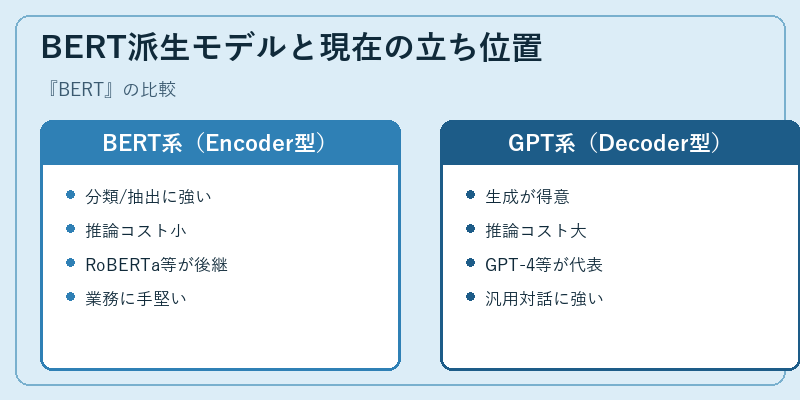
BERT後はFacebookのRoBERTa(2019年、学習設定を最適化)、GoogleのALBERT(パラメータ共有で軽量化)、ELECTRA(識別器型事前学習)など改良が次々と登場した。また分野特化版としてBioBERT(生医学)、FinBERT(金融)、SciBERT(科学論文)なども作られた。
現在の生成AIブームの主役はGPT系のDecoderモデルに移ったものの、文書分類、検索リランキング、固有表現抽出といった「与えられた文を理解する」タスクではBERT系が依然として現役だ。推論コストがGPT系より圧倒的に小さく、ファインチューニングが容易な点も大規模運用で評価される。「BERTは古い」と決めつけず、用途に応じて使い分けるのが賢明な選択である。
まとめ
BERTは2018年に登場した双方向Transformerの事前学習モデルで、自然言語処理の常識を一変させた。GPT全盛の現在もEncoder型の理解タスクでは現役であり、検索や分析の現場で粘り強く使われ続けている。事前学習+ファインチューニングという枠組みの祖先として、その仕組みを押さえておく価値は今も大きい。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント