
TransformerはGoogleの研究者アシシュ・ヴァスワニ氏らが2017年6月に発表した論文「Attention Is All You Need」で提案されたニューラルネットワーク・アーキテクチャである。再帰型ニューラルネット(RNN)や畳み込み(CNN)を一切使わず、自己注意機構(Self-Attention)のみで系列データを扱う設計を打ち出した。登場後の数年でBERT、GPT、T5、Vision Transformerと派生モデルが次々と現れ、生成AI時代の事実上の標準アーキテクチャとなった。本記事では仕組み、歴史的経緯、現在のLLMでの位置付けを通して、Transformerを腑分けする。
この記事の目次
- Transformerの中核は3つの仕組み
- RNN/LSTM時代からの転換
- EncoderとDecoderの組み合わせ方
- RNN/CNNとの違いを整理
- まとめ
Transformerの中核は3つの仕組み
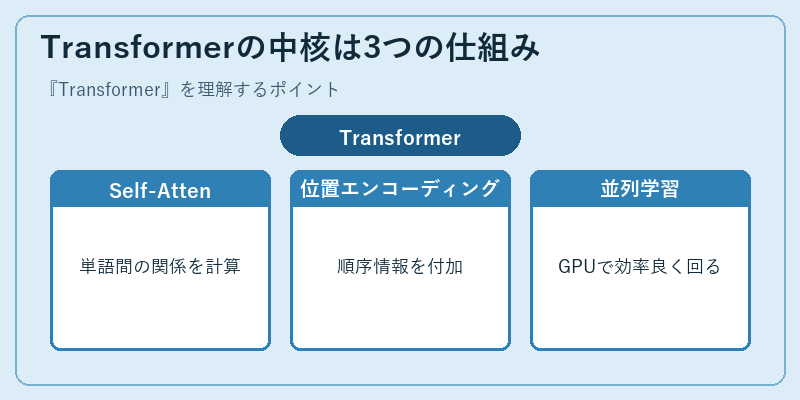
Transformerの心臓部はSelf-Attention(自己注意)機構だ。入力された単語列の各要素が、互いをどの程度参照すべきかを内積で算出し、加重平均で次の表現を作る。Query、Key、Valueの3つの行列を学習し、それらの内積でアテンションスコアを計算するという仕組みは、論文公開以来ほぼそのまま使われ続けている。
RNNと違って単語を逐次処理する必要がなく、行列演算で一括処理できるためGPUとの相性が極めて良い。ただし単語の順序情報がそのままでは失われるため、Positional Encoding(位置エンコーディング)を加えて系列の前後関係を表現する。後にRotary Position Embedding(RoPE)など発展形も登場し、長文脈対応の鍵となった。
RNN/LSTM時代からの転換
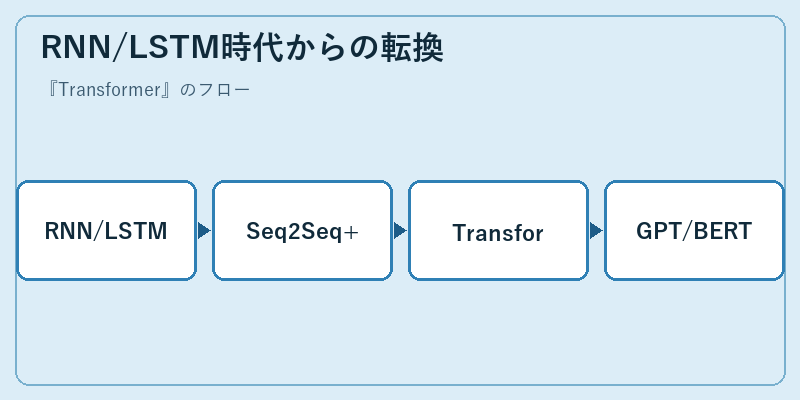
Transformer登場前の自然言語処理は、LSTMやGRUといった再帰型ネットワークが主役だった。2014年頃のSequence-to-Sequence(Seq2Seq)モデル、2015年のAttention付きSeq2Seq(バーダナウ・アテンション)を経て、徐々に注意機構の有用性が認識されていた。その流れで「再帰をやめてアテンションだけにしてみよう」と踏み込んだのがVaswani氏らのTransformerだ。
翌2018年、GoogleからBERT、OpenAIからGPTが相次いで発表され、自然言語処理ベンチマークが軒並み塗り替えられた。2020年のGPT-3、2022年のChatGPT登場で一般社会にもTransformerの存在感が広く知れ渡る。今や画像認識ではVision Transformer、音声認識ではWhisper、生体配列ではAlphaFold 2と、Transformerは言語の枠を超えて拡張され続けている。
EncoderとDecoderの組み合わせ方

原論文のTransformerはEncoderとDecoderの2塔構成だが、その後の派生モデルは用途に応じて片方だけ使うことが多い。BERTはEncoderのみで分類・抽出系タスクに強く、GPTはDecoderのみで自己回帰的にテキストを生成する。GoogleのT5やFacebookのBARTは両方を持ち、要約・翻訳・質問応答などに幅広く対応する。
画像分野ではGoogleのDosovitskiy氏らが2020年に提案したVision Transformer(ViT)が、画像をパッチに分割してトークンとして扱う発想で従来のCNN支配を覆した。音声ではOpenAIのWhisper、化学ではDeepMindのAlphaFold 2が、Transformerの応用範囲を一気に広げた象徴的存在である。現代AIの主要モデルはほぼ全てTransformer系列、と言って差し支えない状況だ。
RNN/CNNとの違いを整理
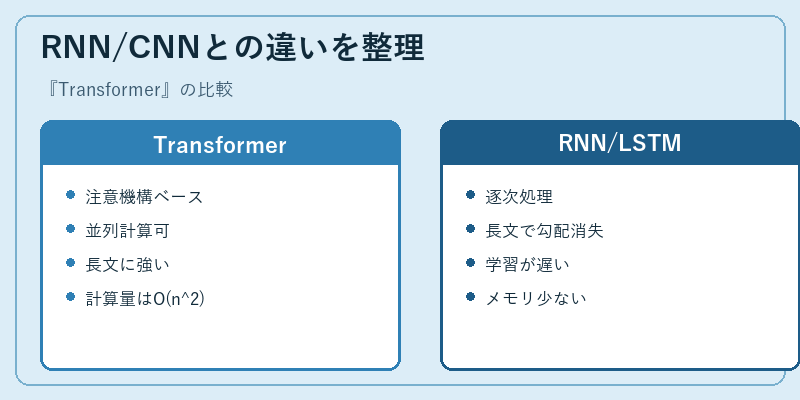
RNN/LSTMは時系列の順序通りに計算するため、長い文章で勾配消失が起きやすく、並列化も難しかった。Transformerはこの両方を克服した一方、Self-Attentionの計算量が系列長nに対してO(n^2)になるという別の課題を抱える。そのためFlashAttentionやRing Attention、状態空間モデルのMambaなど、計算効率を改善する研究が今も活発だ。
また、Transformerはパラメータ数が増えるほど性能が伸びる「スケーリング則」が報告されており、GPT-3の1750億パラメータ、Llama 3.1の4050億パラメータといった巨大化が続いている。学習コストと推論コストは爆増するものの、汎用的な性能向上が得られる点で従来手法と一線を画す。現代のAI戦略を考える上で、Transformerという基盤の特性を理解することは避けて通れない。
まとめ
Transformerは2017年の論文公開からわずか数年で、自然言語処理だけでなく画像・音声・科学計算までを呑み込む万能アーキテクチャに育った。Self-Attentionと位置エンコーディング、並列学習のしやすさという特性が現代AIの爆発的進化を支えている。今後の発展を追う上でも、原論文の理解はAIエンジニアの基礎教養と言える。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント