
Feastはデータサイエンスと機械学習に特化したデータ管理ツールです。2019年にMeta社によって開発が始まり、現在では多くの企業で使用されています。本記事ではFeastの基本概念から高度な利用法までを解説します。
この記事の目次
- Feastの機能と用途
- Feastのアーキテクチャ
- Feastと他のツールの比較
- Feastの歴史と展望
- まとめ
Feastの機能と用途
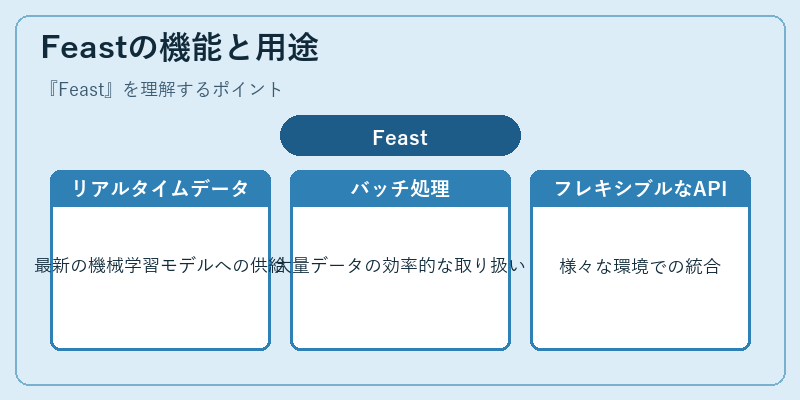
Feastは、リアルタイムとバッチモードで効率的にデータを管理します。例えば、オンラインレコメンデーションシステムでは、ユーザーアクティビティの最新情報をすぐに反映させます。
一方、大規模な機械学習プロジェクトでは、バッチ処理を使用して大量データを高速に解析します。これにより開発者は複雑なモデルを効率よく構築できます。
Feastのアーキテクチャ

Feastのアーキテクチャは拡張性と柔軟性を兼ね備えています。データソースから抽出したデータは、Feature Viewsを通じて適切な形式に変換され、ストレージで保存されます。
その後、リアルタイムエンドポイントやバッチジョブを通じて機械学習モデルへ提供されます。このように複雑さを最小限に抑えることで開発者は効率的に作業を行えます。
Feastと他のツールの比較

Feastは、他のツールとは異なる独自のアプローチを採用しています。例えば、リアルタイム対応やFeature View機能が特徴的です。
一方でApache Kafkaはメッセージングシステムと分散処理に長けており、ストリーミングデータに対する豊富なサポートがあります。両者は用途によって使い分けることができます。
Feastの歴史と展望
Feastは2019年にMeta社によって開発が始められ、その後様々な機能が追加されてきました。現在では多くの企業で採用されつつあります。
今後も機械学習技術の進化に合わせて新たな機能を追加していくことが予想されます。これによりFeastはさらなる拡張性と柔軟性を持つでしょう。
まとめ
Feastはデータ収集フレームワークとして重要な役割を果たしており、現代の機械学習プロジェクトにおいて欠かせない存在と言えます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







