
Pythonの標準ライブラリに含まれるfilter()関数は、20世紀後半からある歴史を持ち、リストやイテレータを効率的にフィルタリングするための重要なツールとして広く使用されている。この記事では、filter()関数の基本的な概念、動作原理、および他の類似ライブラリとの比較を通じて、その多面的な利用法について詳しく解説します。
この記事の目次
- filter() 関数とは
- 動作原理
- 他のフィルタリング方法との比較
- filter() 関数の応用例
- まとめ
filter() 関数とは
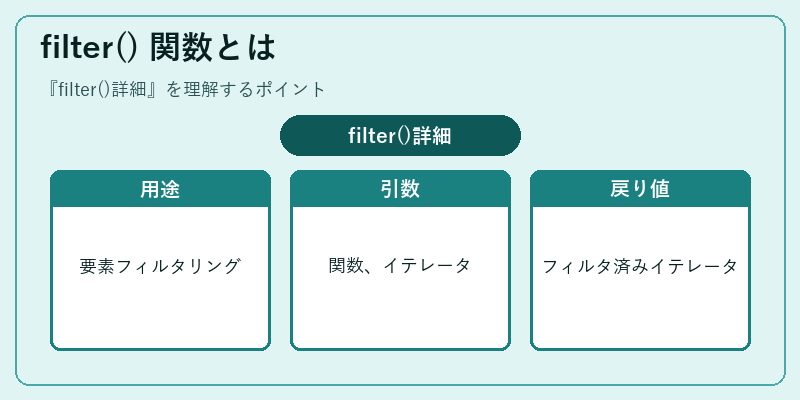
filter() 関数は Python でリストや他のデータ構造を効率的に処理するための重要な要素です。この関数は、通常のリスト操作よりも柔軟な条件に基づいて要素を選別します。
例えば、ある整数のリストから偶数だけ取り出す場合、filter() 関数とlambda式を組み合わせて実装できます。これはシンプルかつ効率的なコード生成を可能にし、Python開発者にとって強力なツールとなっています。
動作原理
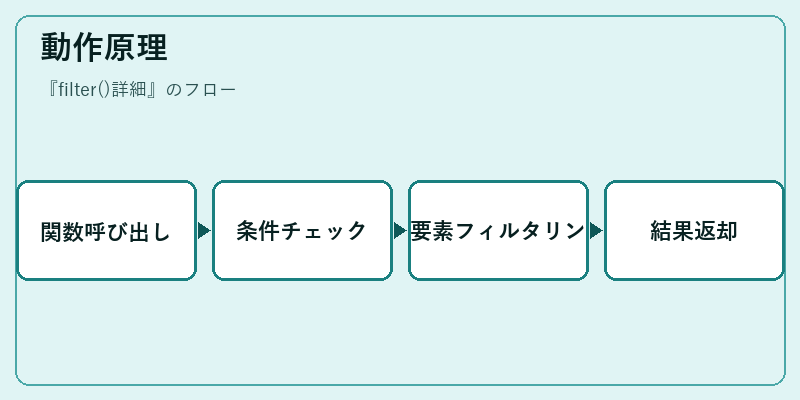
filter() 関数は内部的に Python が提供するイテレータと連携して動作します。まず、与えられた関数(通常はlambda式)を各要素に適用し、その結果に基づいてフィルタリングを行います。
具体的には、フィルタ条件としての関数が真となるデータのみを抽出して返す仕組みで、これにより非常に効率的なコード生成が可能となります。このプロセスはイテレータを利用して行われ、メモリ消費量も抑えられます。
他のフィルタリング方法との比較

filter() 関数は、同じような用途を持つリスト内包表記と比較して、より汎用的なフィルタリング操作を提供します。
例えば、フィルタ条件が複雑な場合でも filter() は簡単に実装可能ですが、リスト内包表記では冗長なコードが必要になることがあります。
filter() 関数の応用例

filter() 関数は、データウェアハウスやWebアプリケーションなどの開発において広範囲にわたる応用が可能です。
例えば、APIから取得した大規模なレスポンスを絞り込む際にも効果的で、複雑な条件での要素選別には特に威力を発揮します。
まとめ
filter() 関数はPythonにおけるリスト処理において重要な役割を果たしており、その多機能性と柔軟性が開発者の手助けとなる多くの場面があることが理解できたでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







