
Fixed-size chunkingは、大量データを効率的に取り扱うために開発されたテクノロジーで、1980年代から利用されている。この方法は、連続するデータのセグメントを一定サイズに分割することで、並列処理や分散ストレージシステムにおける計算効率を向上させる。本記事ではその仕組みと利点について掘り下げていく。
この記事の目次
- Fixed-size chunkingの定義
- Fixed-size chunkingの歴史と進歩
- Fixed-size chunkingの実装とメカニズム
- Fixed-size chunkingと他の分割手法の比較
- まとめ
Fixed-size chunkingの定義
Fixed-size chunkingは、連続的なデータストリームを固定長区画に分割する技術です。これにより、大規模なデータセットを扱う際の計算や検索速度が向上します。その一方で、各データブロックのサイズを適切に決定することが重要になります。
例えば、音声ファイルでは1秒間に32,000サンプルある場合、それぞれの区画はそれらのサンプル数に応じて均等に分割されます。これにより、特定の部分に対するアクセスや処理が高速化します。
Fixed-size chunkingの歴史と進歩

Fixed-size chunkingは、1980年代に分散ファイルシステムが開発される頃から徐々に普及しました。当時は並列計算や大規模データセットへのアクセス効率向上というニーズがありました。
その後、インターネットの勃興とともにデータ量が増加し、この技術はより重要な位置を占めるようになりました。現在ではクラウドコンピューティングや機械学習などの分野でも広く使用されています。
Fixed-size chunkingの実装とメカニズム

Fixed-size chunkingは、まず全体のデータストリームを読み取ります。次に固定長で各部分を区分けし、それぞれの区画に対して同時に処理を行います。これが高速かつ効率的な計算を可能とします。
例えば、ビデオファイルの圧縮処理では、一定時間分だけのフレームを一括して処理することで、全体の読み込み時間を短縮できます。この技術は、データ量が多くなるにつれてその優位性がより顕著になります。
Fixed-size chunkingと他の分割手法の比較
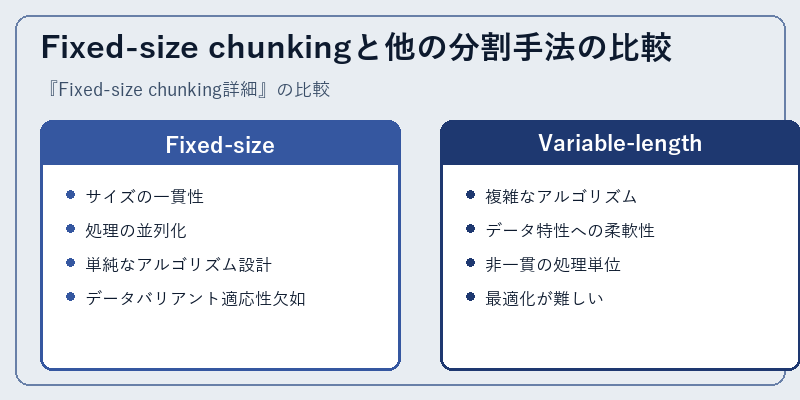
固定長区画と可変長区画は、それぞれ特徴的なアプローチを採用しています。前者は計算効率に優れますが、データ特性への柔軟性には欠けます。後者はその逆で、一貫したパフォーマンスを達成するのが難しいことがあります。
具体的な利用シーンでは、固定長区画が大量の同質データに対して効果的であり、一方で可変長区画は特性の異なる複数データセットに対する柔軟性が必要な場合に適しています。
まとめ
Fixed-size chunkingは大規模データ処理において重要な役割を果たし、今後もその活用範囲が広がっていくことが予想されます。しかし、アプリケーションの特性に応じて最適な分割方法を選択することが肝要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







