
FSDP(Fully Sharded Data Parallel)は、近年の大規模な機械学習モデル開発において重要な役割を果たすデータ並列処理の一種です。本記事では、その概念や仕組みから実際の活用例まで幅広く解説します。
この記事の目次
- FSDPとは何か
- FSDPの歴史的背景
- FSDPの仕組み
- FSDPと従来型並列処理の比較
- まとめ
FSDPとは何か
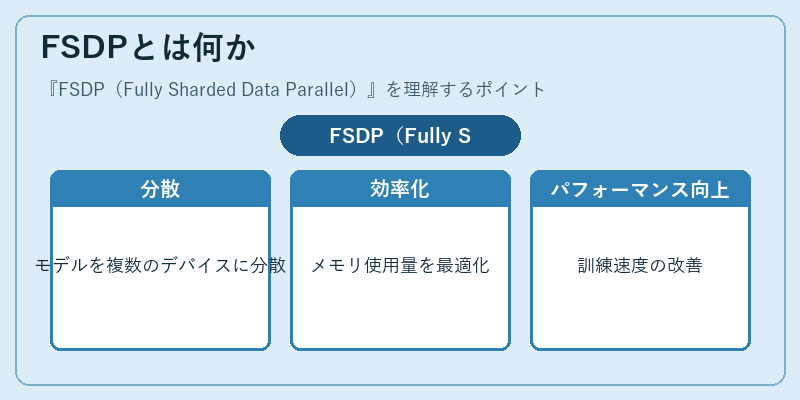
FSDPは、大規模なAIモデルをトレーニングする際に利用される技術です。この手法では、データセットが複数のプロセッサ間で分割され、効率的に処理されます。例えば、長文の文章生成モデルの訓練において、GPUメモリを節約しながら高速に学習を行うことが可能になります。
なお、従来型のデータ並列処理と比較してFSDPは更なるパフォーマンス向上が期待できるため、最先端のAI研究や実践的なデプロイメントで注目されています。
FSDPの歴史的背景

FSDPの開発は、大規模な深層学習モデルを効率的にトレーニングする必要性から始まりました。計算資源やデータセットが急速に増加する中、従来型の並列処理では限界を感じるようになりました。
その解決策として生まれたFSDPは、単なるパフォーマンス改善だけでなく、新たなトレンドを生み出すこととなりました。
FSDPの仕組み
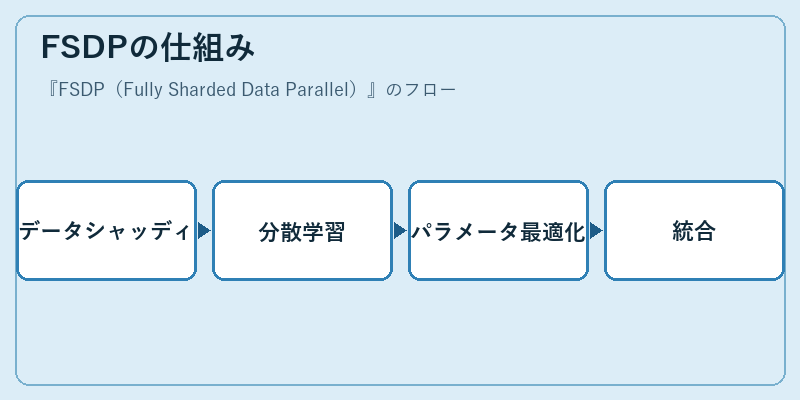
FSDPでは、まずモデルとデータセットを細かく分割し、各プロセッサが独立して学習を行います。これによりメモリ使用効率の向上と並行処理による高速化が可能となります。
このプロセスは複雑ですが、適切なチューニングによって極めて効果的なモデルトレーニングを実現します。
FSDPと従来型並列処理の比較
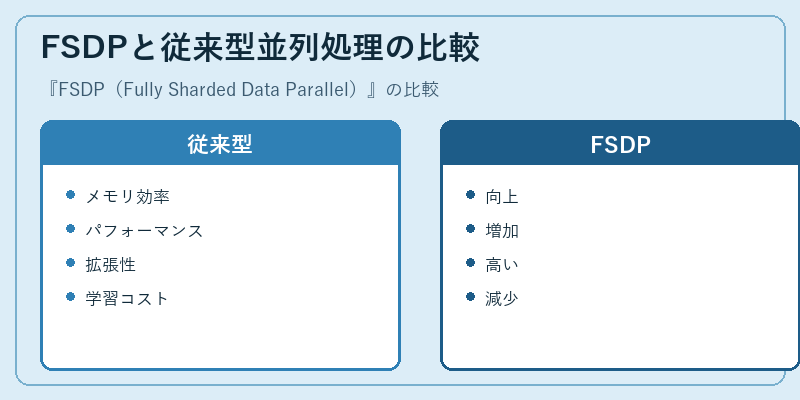
従来型のデータ並列処理では、モデルサイズやデータ量が増えるとメモリ効率は低下します。これに対してFSDPは、より効果的なメモリ管理を実現しており、大規模なトレーニングでも安定したパフォーマンスを維持できます。
また、拡張性や学習コストにおいても優れた性能を発揮し、AI研究者や開発者の新たな選択肢となっています。
まとめ
FSDPは、大規模な機械学習モデルのトレーニングに新しい可能性をもたらす技術です。今後もこの領域での進展に注目したいところです。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







