
GradientBoostingClassifierは、グラデーションブースティング(GB)アルゴリズムを用いて効率的なモデルを構築するためのツールです。20世紀後半に発展した統計手法が起源で、近年ではPythonのscikit-learnライブラリで実装されており、データサイエンスコミュニティでの普及も進んでいます。
この記事の目次
- GradientBoostingClassifierの定義
- GBMアルゴリズムの歴史
- GradientBoostingClassifierの仕組み
- GradientBoostingClassifierと他のアルゴリズムの比較
- まとめ
GradientBoostingClassifierの定義
GradientBoostingClassifierは、分類タスクに対する最適なモデルを構築します。GBMの考え方では、各エラーに対して逐次的に最小化が行われます。これにより、モデルが複雑さと過学習を避ける一方で高い性能を発揮することが可能になります。
例えば、デジタル広告のクリック予測や医療データからの診断推論など、多数の実世界の問題において、GradientBoostingClassifierは重要な役割を果たしています。
GBMアルゴリズムの歴史

GradientBoostingClassifierは、グラデーションブースティングという概念から始まりました。これは1980年代から研究され、その後2000年にscikit-learnなどの機械学習フレームワークに実装されました。
このアルゴリズムは、その頃のデータサイエンス業界で大きな変革をもたらしました。それまでの単純な線形モデルだけでなく、複雑な非線形パターンの検出にも適用可能となりました。
GradientBoostingClassifierの仕組み
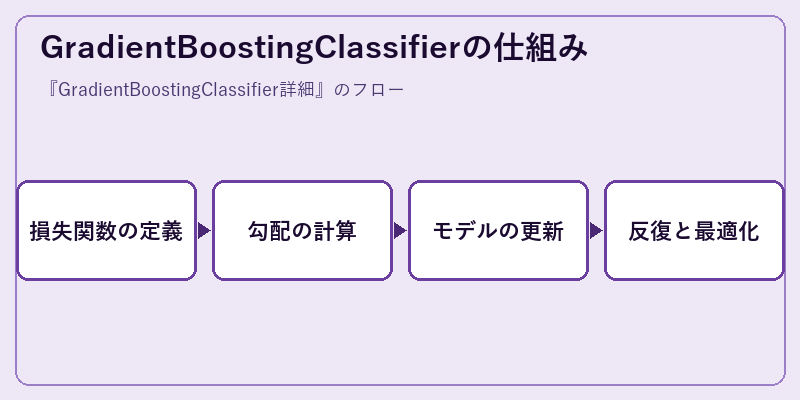
GBMでは、各ステップで新たな予測器を加えて全体的な誤差を改善します。これが繰り返されることで、最終的に精度が極端に高い分類器が完成します。このプロセスは反復と勾配の計算により行われます。
それぞれの予測器は、前回よりもよい結果になるように調整されます。したがって、モデル全体の複雑さを適切に管理しつつ精度を向上させることが可能です。
GradientBoostingClassifierと他のアルゴリズムの比較
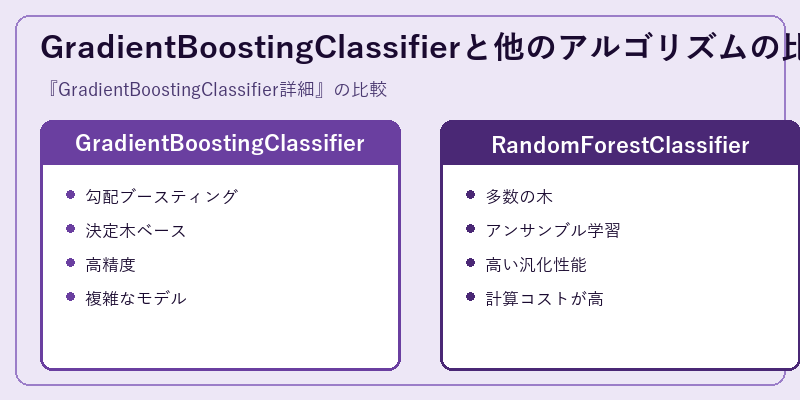
GradientBoostingClassifierとRandomForestClassifierは、どちらも決定木をベースにした機械学習アルゴリズムです。しかし、その仕組みや性能上の特性には大きな違いがあります。
GBMは逐次的に予測器を追加し精度向上を目指しますが、RFは多数の決定木をアンサンブルすることでパフォーマンスを最大化するアプローチを採用しています。
まとめ
GradientBoostingClassifierは、その直感的な性能と強力な予測能力から多くのデータサイエンティストに選ばれていますが、適切なパラメータの調整が必要となる点にも注意が必要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







