
KubeflowはKubernetes上でJupyter Notebook環境、データ前処理、分散学習、ハイパーパラメータチューニング、モデルサービング、そしてパイプライン自動化までを統合的に提供する、フルスタックのMLOpsプラットフォームです。2017年12月にGoogleのDavid Aronchickらが「TensorFlow Extended(TFX)」の社内ノウハウをK8sユーザーへ開放する形で公開し、現在はCNCFインキュベーションプロジェクトとしてGoogle・Red Hat・IBM・Cisco・Bloombergなど多数の企業エンジニアが開発に参加しています。K8sを既に使っている組織がMLパイプラインまで同じ基盤で統一したいときの代表的選択肢です。
この記事の目次
- Notebook・Pipelines・Katib・KServe
- Googleが種を蒔きCNCFで育つ
- K8sを核にした本番ML運用
- MLflow・SageMaker・Vertex AIとの違い
- まとめ
Notebook・Pipelines・Katib・KServe
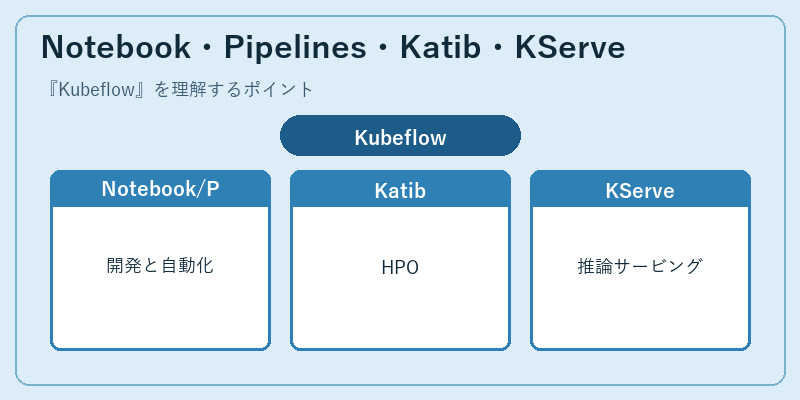
Kubeflowは複数のサブプロジェクトの集合体で、コアとなるのは「Kubeflow Pipelines」「Katib」「KServe」「Notebooks」の4つです。Pipelinesでは前処理・学習・評価・登録の各ステップをコンテナ単位のDAG(有向非巡回グラフ)として定義し、K8s上で再現性高く実行できます。Notebooksは多人数共有のJupyterLab環境をK8s上に立てる仕組みで、GPUリソースを必要なときだけ割り当てる運用が可能です。「研究者の手元」と「本番パイプライン」の橋渡しを意識した設計が、Kubeflowの根本思想となっています。
「Katib」はAutoMLのうちハイパーパラメータ最適化(HPO)とNeural Architecture Searchを担当し、Random/Grid/Bayesian/HyperBandなどのアルゴリズムをサポートします。「KServe」(旧KFServing)はONNX、TensorFlow、PyTorch、scikit-learn、Hugging Face Transformersなどを統一APIで推論サービングする推論基盤で、自動スケール、トラフィック分割、Canaryデプロイ、Explanationといった本番運用機能を備えています。これらが組み合わさることで、K8sを既に持つ組織は「ML専用クラスタを別途立てる」発想を回避し、既存基盤の上にMLOpsを乗せられるのが大きな利点です。
Googleが種を蒔きCNCFで育つ
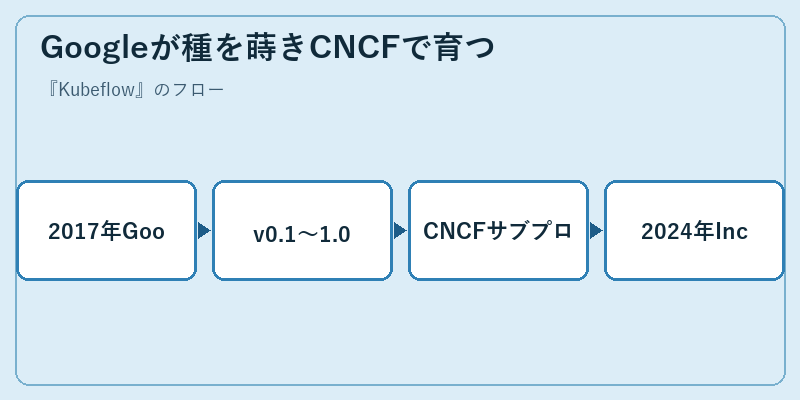
Kubeflowは2017年12月、GoogleのDavid Aronchickらが社内のTensorFlow ExtendedをK8sユーザーへ汎用化する形で公開しました。当初は単なる「TensorFlowをK8sで動かす」ためのHelmチャート集でしたが、すぐに多くのフレームワーク対応と多コンポーネント化が進み、2020年代にはMLOpsの代表的OSSとして広く認知されるようになりました。GoogleのほかRed Hat、IBM、Cisco、Bloomberg、Arrikto、CERNなどの企業や研究機関が積極的にコントリビュートし、多社協調で進化を続けています。
プロジェクトは2024年6月、CNCFの正式なIncubatingプロジェクトとして受け入れられ、KubernetesやPrometheusと同じ枠組みで運営されるようになりました。中立的な財団下でガバナンスが整備されたことで、「Google独自路線」から「マルチベンダーのコミュニティOSS」へ位置付けが明確になり、新規組織の採用検討においても安心材料が増しました。各クラウドベンダーが自社のK8sサービス向けに対応版を提供しており、Google Cloud Vertex AI Pipelines、AWS SageMaker、Azure Machine Learning Pipelinesなどとも一定の互換性が保たれています。
K8sを核にした本番ML運用

Kubeflowが本領を発揮するのは、すでに開発・本番でK8sを使っている組織がMLパイプラインを統一したいケースです。データ前処理はSpark、特徴量抽出はBeam、学習はPyTorchやTensorFlowといった異なるコンテナを、Pipelines上で1本のDAGとして繋ぎ、再現可能なバッチ学習を毎日/毎週スケジュール実行できます。GPUノードとCPUノードの混在クラスタでも、KubernetesのNode AffinityとTaint/Tolerationで自動的にスケジュールされます。TPUを使うGCP上のKubernetes Engineとも連携でき、Googleが研究で使った大規模学習構成を企業内で再現可能です。
本番サービングではKServeを使い、新モデルを10%のトラフィックで試すCanaryデプロイ、説明可能AI(Explainer)の付加、TLS付きの推論エンドポイント発行などを自動で行えます。Katibを並列で走らせれば、Bayesianアルゴリズムでハイパーパラメータ100通りを自動探索しつつ、最良モデルだけをKServeに昇格させる流れまで一気通貫で構築できます。K8sのリソースクォータやRBACをそのまま使うため、複数チーム間のリソース分配・権限制御も新規ツールを覚えずに既存運用に乗せられる点も魅力です。
MLflow・SageMaker・Vertex AIとの違い

MLflowは実験記録とモデル管理に特化したコンパクトなOSSで、Kubeflowほど広範な機能は持たない代わりに導入のハードルが低いのが特長です。AmazonのSageMaker、GoogleのVertex AI、MicrosoftのAzure Machine Learningは、それぞれクラウドベンダー純正のマネージドMLOpsで、運用は楽な代わりにベンダーロックインが発生します。Kubeflowの強みは「K8sがあればどこでも動く」「OSSで自社運用可」「マルチクラウド・オンプレに対応」という点で、規制業界やマルチクラウド戦略を採る組織で特に好まれます。
ただし、Kubeflowは多くのサブプロジェクトを束ねた巨大スタックゆえに学習コストと運用負荷が高く、「とりあえずML実験管理だけ」という用途には過剰になりがちです。そのため最近は「実験管理はMLflow、本番パイプラインはKubeflow Pipelines、サービングはKServe」のように使い分ける構成や、「研究はSageMaker、本番だけKubeflow」というハイブリッド運用も現実的な選択肢として広がっており、組織のMLメンタリティとK8s習熟度で選定が分かれます。
まとめ
KubeflowはGoogleが種を蒔きCNCFで育つK8sネイティブのフルスタックMLOps基盤で、Pipelines・Katib・KServe・Notebooksを束ねます。K8sをすでに運用している組織が本番MLまで同じ基盤で統一したい場合の有力選択肢で、MLflowやVertex AIと組み合わせて使う「いいとこ取り」構成も含めて、エンタープライズMLOpsの中核を担っています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント