
MLflowは機械学習の実験パラメータ・メトリクス・成果物(モデル)・ソースコードバージョンを統一フォーマットで記録し、後から比較・再現・本番デプロイまで一気通貫で扱えるオープンソースのMLOps基盤です。2018年6月にApache Spark生みの親Matei Zahariaが率いるDatabricks社が公開し、Apache License 2.0でOSS化しました。現在はLinux Foundation配下のLF AI & Dataプロジェクトとして中立的に運営されており、Pythonエコシステムを中心にscikit-learn、TensorFlow、PyTorch、XGBoost、LangChainなど主要フレームワークと公式統合を持つ「実験記録のデファクト」となっています。
この記事の目次
- Tracking・Models・Registry・Projects
- Databricks発、LF AI傘下へ
- 実験管理から生成AI評価まで
- Weights & Biases・Kubeflowとの違い
- まとめ
Tracking・Models・Registry・Projects
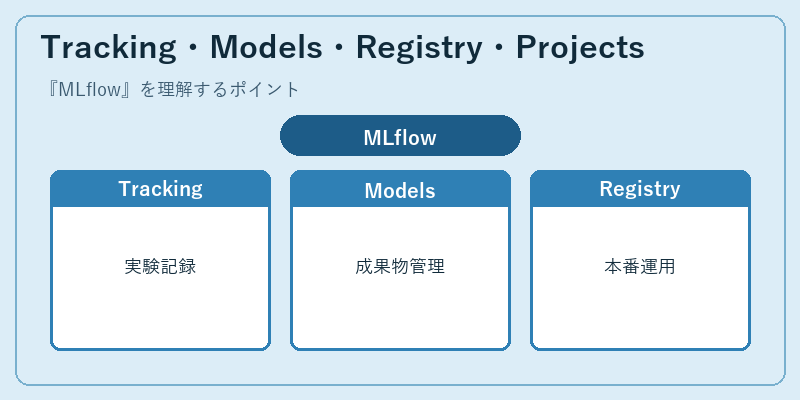
MLflowは大きく4つのコンポーネントに分かれています。「Tracking」は実験のパラメータ・メトリクス・アーティファクト・タグ・コードバージョンを記録し、Webコンソールから複数Runを並べて比較できるダッシュボードを提供します。「Models」はモデルを言語非依存のパッケージ形式(MLmodel)で保存し、scikit-learn、PyTorch、TensorFlow、ONNX、LangChain Chainなど多形式を統一的に扱えます。「Model Registry」では本番/ステージング/アーカイブのステージ管理ができ、誰が承認したか、どのバージョンがいつ昇格したかの監査ログも残ります。
「Projects」はconda/pip/Dockerで実行環境を宣言的に記述する仕組みで、mlflow run コマンドで同じコードを誰でも再現実行できます。Trackingサーバーは MySQL/PostgreSQL/SQLite/ファイルストレージなどに対応し、Artifact StoreにはAmazon S3/Azure Blob/Google Cloud Storage/HDFS/ローカルディスクが選べます。Databricks Managed MLflowを使えば運用ごと任せられ、自社運用したい場合もDocker一発でTrackingサーバーが立ち上がる気軽さが、急速な普及を後押ししました。
Databricks発、LF AI傘下へ

Databricks社はApache Sparkの生みの親であるMatei Zahariaがカリフォルニア大学バークレー校AMPLabの仲間と2013年に創業した会社で、Sparkを核にしたLakehouse基盤を商用化してきました。そのDatabricksが2018年6月、社内で複数チームの機械学習実験を統一管理する必要性から作っていたツールをOSSとして公開したのがMLflowの始まりです。公開当時のSpark Summitでマテイ自らがデモを行い、強い注目を浴びました。
2020年6月にv1.0が発表され、その後はバージョンを重ねながらLangChainやHugging Face Transformersなど生成AI領域の統合も進めています。2024年6月、MLflowはDatabricksから独立性を持たせるためLinux Foundation配下のLF AI & Dataプロジェクトに寄贈されました。これによりMicrosoft、Amazon、Google、Metaなど多数のベンダーが中立的にコントリビュートできる体制となり、MLOpsのデファクトとして長期的な利用が一段と現実的になりました。Databricksは引き続き主要スポンサーとして開発をリードしています。
実験管理から生成AI評価まで

典型的な使い方は import mlflow と mlflow.autolog() の2行を足すだけ、というシンプルさです。これだけでscikit-learnやPyTorchのパラメータ、評価指標、学習済みモデル、入力サンプルが自動でTrackingサーバーに記録され、WebコンソールでRun一覧を「Accuracy順」「F1スコア順」に並べて比較できます。Grid Searchや Optuna との連携も容易で、ハイパーパラメータ探索100通りの結果を1ダッシュボードに集めて、最良モデルだけをRegistryに登録する、というワークフローが標準的です。
近年はLLM/生成AI領域への拡張が顕著で、mlflow.evaluate() がLLMの応答を自動で評価したり、プロンプトのバージョン管理・LangChain Chain・LlamaIndexワークフローのトレーシングをサポートしたりと、生成AI MLOpsの土台に進化しています。本番運用ではMLflow Registryにモデルを登録し、Stagingで検証→Productionへ昇格、というApprovalフロー付きの運用が定番で、Kubernetes上のKServe、SageMaker、Vertex AI、Azure MLなどへエクスポートして推論サーバーを立てることも公式ツールでサポートされています。
Weights & Biases・Kubeflowとの違い

競合のWeights & BiasesはSaaS主体でダッシュボードのUXに磨きをかけ、特に研究機関やKaggleコミュニティで強い支持を得ています。KubeflowはK8s上のフルスタックML基盤で、パイプライン・Notebook・サービング・ハイパーパラメータチューニングを全部抱える広範な選択肢です。Neptune.aiとCometも実験管理SaaSとして高機能で、商用ライセンスや料金体系で住み分けが進んでいます。
MLflowの差別化軸は「完全OSSで自社運用も可能」「LF AI傘下で特定ベンダー依存が小さい」「Databricks純正の統合とサポート」の3点です。オンプレ要件やデータ越境制約のある業界(金融・医療・公共)ではMLflowが選ばれやすく、SaaSの便利さを取りたいスタートアップではW&Bが選ばれる、という棲み分けが進みつつあります。Databricks契約がある企業はManaged MLflowを使えば運用負担ゼロで導入できるため、Databricksユーザーには事実上の標準と言えます。
まとめ
MLflowはDatabricks発・LF AI & Data傘下の完全OSS MLOps基盤で、実験記録・モデル管理・本番昇格までを統一的に扱えます。Pythonエコシステムとの統合が広く、近年は生成AI評価まで守備範囲を広げ、Weights & BiasesやKubeflowと並ぶMLOpsの主役として企業導入を着実に伸ばし続けています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント