
Actor-Criticは強化学習において、アクタとクリティックという双方向フィードバック構造を用いた手法です。1980年代に生まれ、現在ではDeep Reinforcement Learningで中心的な役割を果たしています。
目次
この記事の目次
- Actor-Criticの概念
- Actor-Criticの歴史的背景
- Actor-Criticの仕組み
- 他の強化学習手法との比較
- まとめ
Actor-Criticの概念
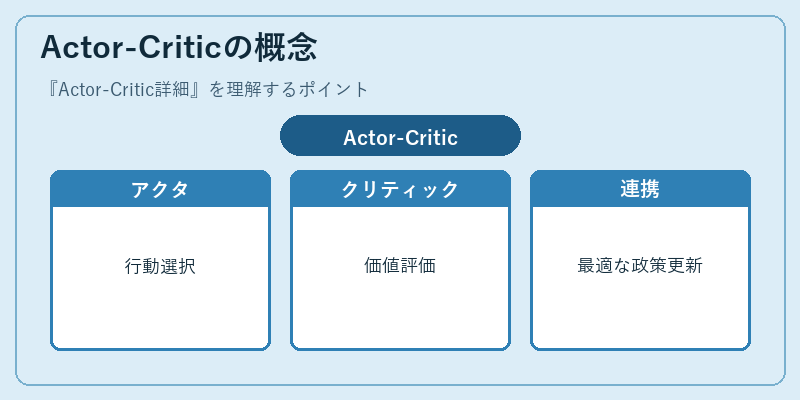
Actor-Criticは強化学習で役立つ概念を導入します。
例えば、アクタが環境との対話を通じて行動を選択し、その効果をクリティックが評価することで、政策の最適化を行います。
Actor-Criticの歴史的背景

Actor-Criticは、その理論的な基盤を1980年代の強化学習研究から得ています。
その後、DeepMindによるA3CアルゴリズムやAlphaGoなどの活用で急速に進化し、現代ではDeep Learningと統合されています。
Actor-Criticの仕組み
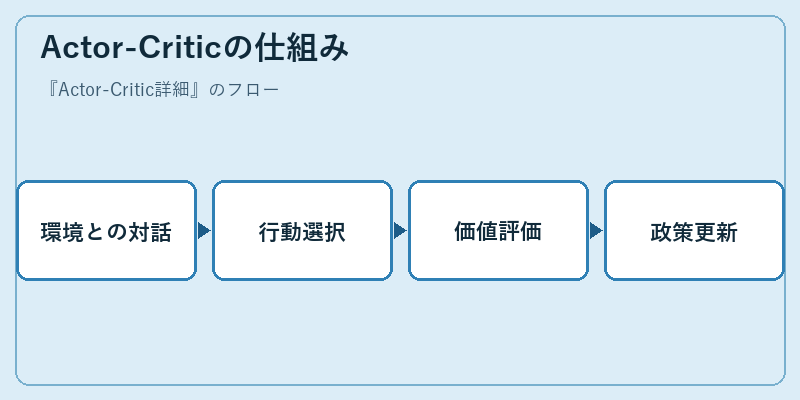
Actor-Criticでは、環境から得た情報に基づき行動を決定し、その結果を用いて価値を評価します。
その後、このプロセスを通じて政策が更新され、より効率的な学習が可能となります。
他の強化学習手法との比較
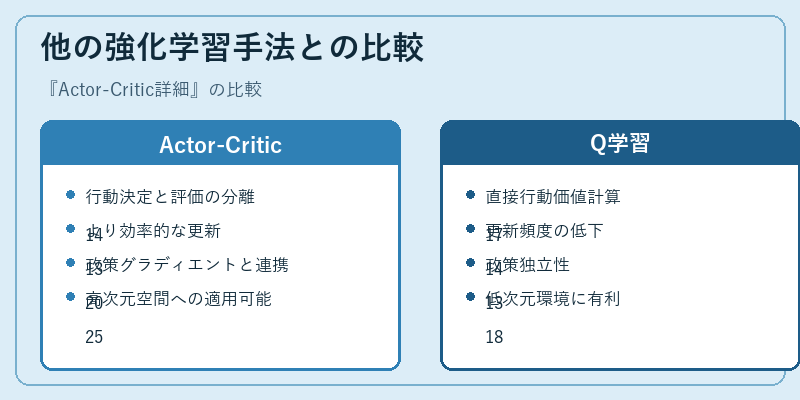
Actor-Criticは、行動決定と評価を分離することで効率的な学習を可能にします。また、Q学習とは異なり、高次元空間でも適用可能です。
一方でQ学習は直接的に行動価値を計算し、更新頻度の低下が予想されます。したがって、特定の条件ではそれぞれの手法が異なる利点を持ちます。
まとめ
Actor-Criticを通じて強化学習における効率化と柔軟性のバランスを理解することで、より広範な応用可能性が開けます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント