
1995年にYoav FreundとRobert Schapireによって提唱されたAdaBoostは、強化学習における重要な手法として知られる。確率的近似法を用いた機械学習理論に基づき、多数の弱い推定器から強い推定器を作り出すことで高い精度を達成する。
この記事の目次
- AdaBoostの基本概念
- AdaBoostの学習過程
- AdaBoostと他のアルゴリズムの比較
- AdaBoostの適用事例
- まとめ
AdaBoostの基本概念

AdaBoostは、機械学習におけるブースティング技術の一種です。これは個々の弱い推定器が組み合わさることで全体として高い精度を持つ強力な推定器を形成するという概念に基づいています。最初に弱い推定器はデータセットからランダムに選択され、その後誤分類されたサンプルには重みが付けられ、新たな学習が行われます。
たとえば、複数の決定木アルゴリズムが組み合わさることで、より高度な推定器を作り出すことができるようになります。AdaBoostはこれらの個々の推定器を効果的に統合し、全体として高い精度を持つ強力なモデルを作成します。
AdaBoostの学習過程
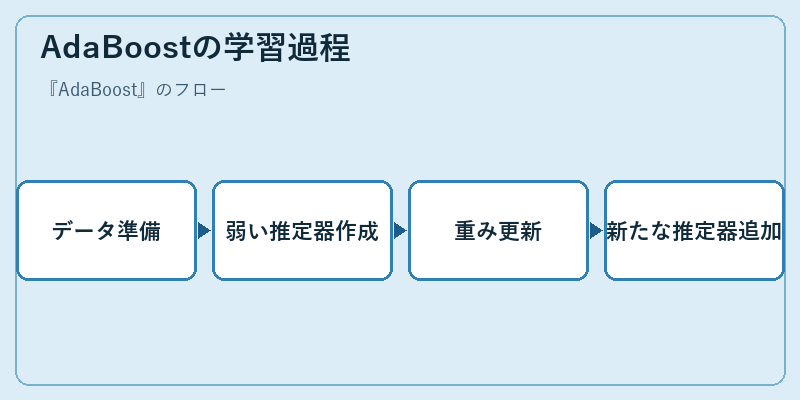
AdaBoostでは、学習プロセスは繰り返し行われます。最初に適切なデータセットが用意され、次いで複数の弱い推定器が作られます。これはしばしば決定木など比較的単純なモデルから始まります。
この初期ステージでは、すべてのサンプルは同様の重みを持つと仮定します。次に、誤分類されたデータ点に対して重みを増加させることで、次の学習フェーズではこれらのデータ点への焦点が強化されます。繰り返し行われるこのプロセスにより、最終的なモデルがより高度な推定能力を持つようになります。
AdaBoostと他のアルゴリズムの比較

AdaBoostと他の強化学習アルゴリズムとの間には重要な違いがあります。AdaBoostは個々の弱い推定器から全体として強いモデルを作り出すため、複雑さを最小限に抑えることが可能です。これに対し、サポートベクトマシン(SVM)はデータポイントにおける最大の分離境界を見つけ出し、非線形空間への対応能力を高めます。
AdaBoostでは特に誤分類サンプルに対する重み更新が重要な役割を果たします。これにより、モデルは精度向上に効率的に焦点を当てることができます。しかしSVMの場合は計算量が増えてしまうというデメリットがあります。
AdaBoostの適用事例

AdaBoostは、様々な応用事例においてその有用性を発揮します。特に画像の識別や文書の分類といった問題では、複数の弱い推定器から作られる強力なモデルが優れた性能を示すことが多々あります。
さらに医療診断や金融リスク評価などの実践的な場面でも、AdaBoostはその柔軟性と精度向上能力により重要な役割を果たします。これらの分野では高精度かつ効率的な推定が必要であり、AdaBoostはそれらのニーズに適応することができます。
まとめ
1990年代以降、AdaBoostは機械学習における重要な手法として広く採用されています。今日でもその基本原理が多くのアルゴリズムやフレームワークに適用され続けていることは興味深い。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント